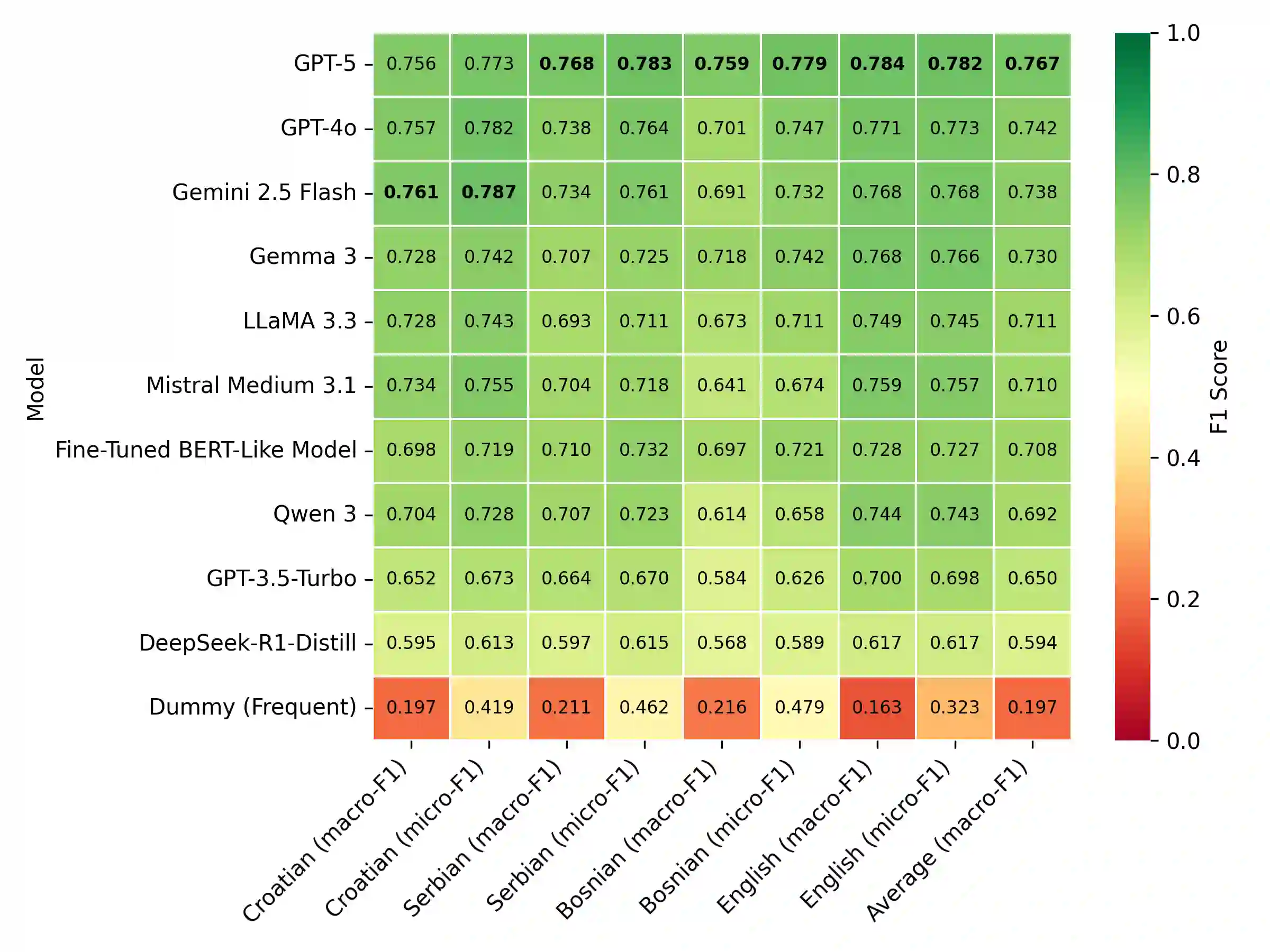
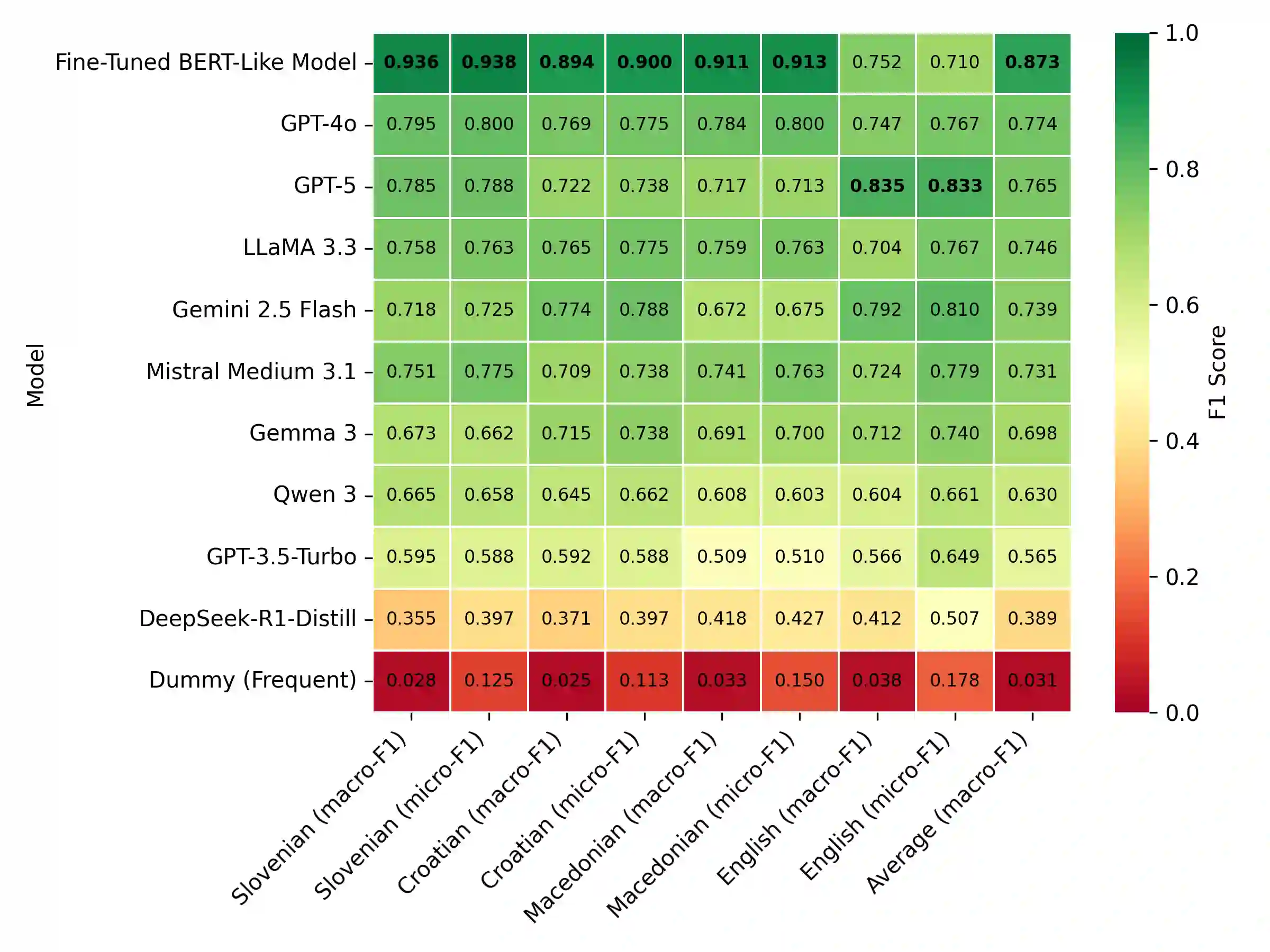
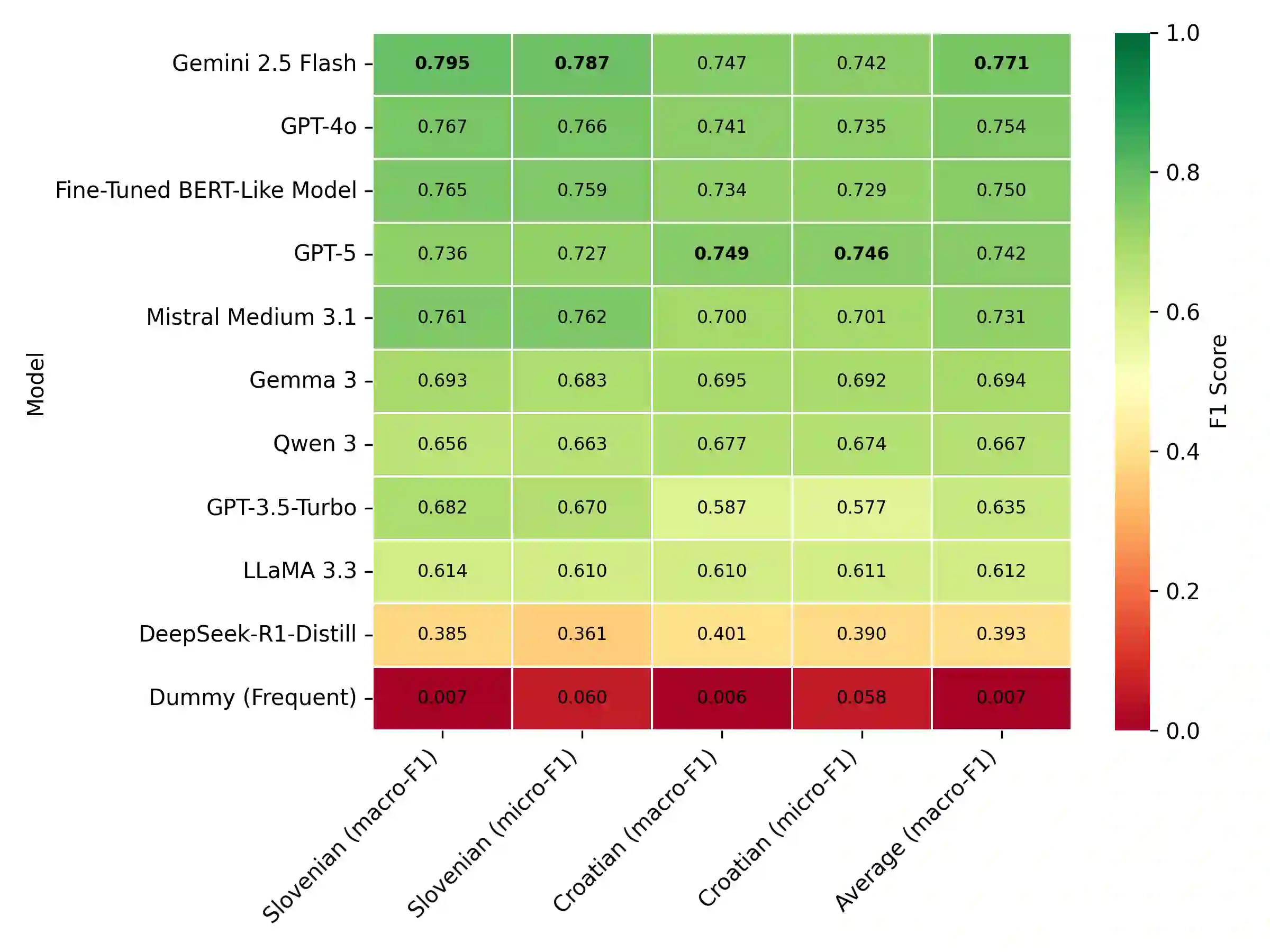
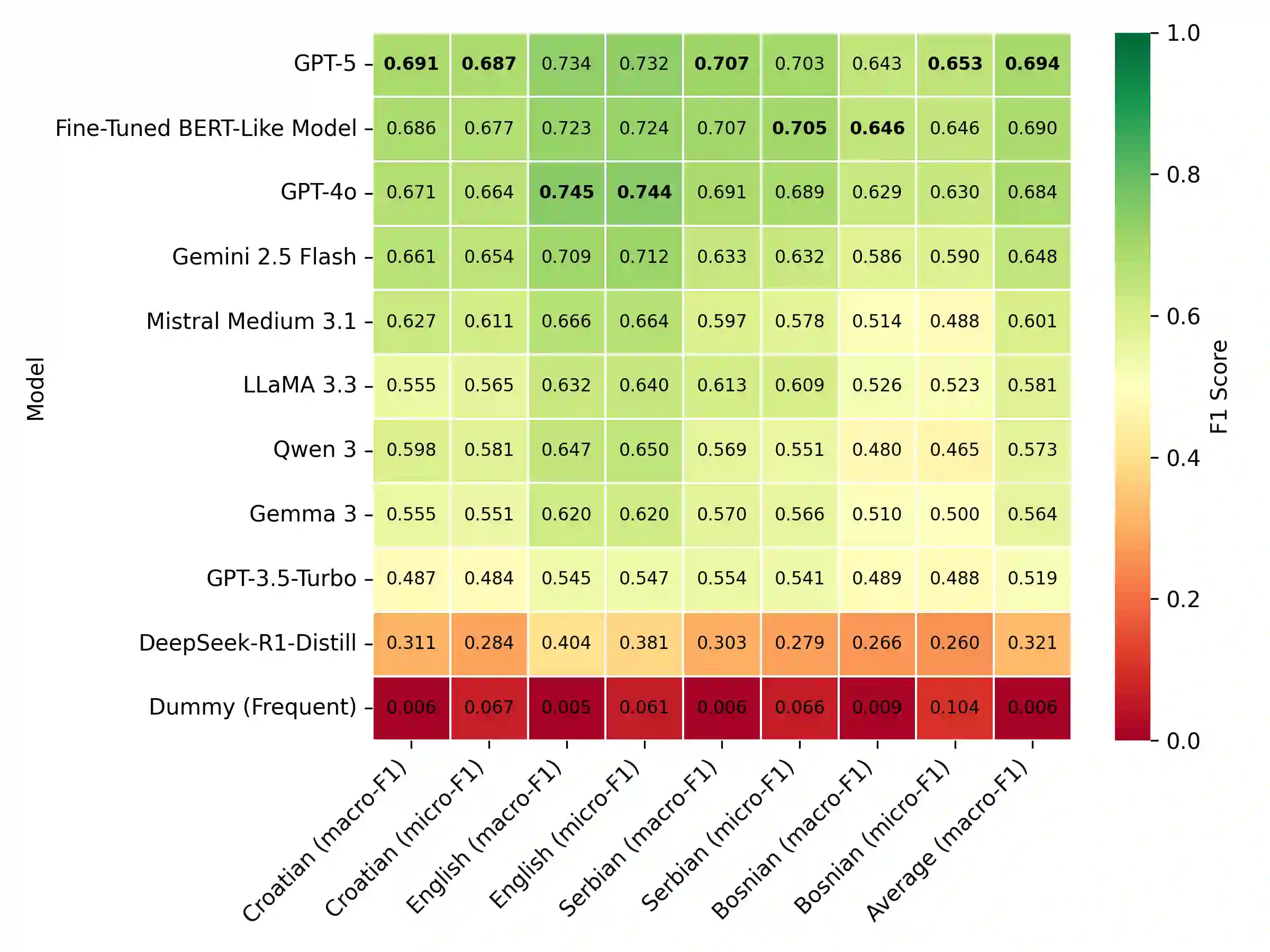
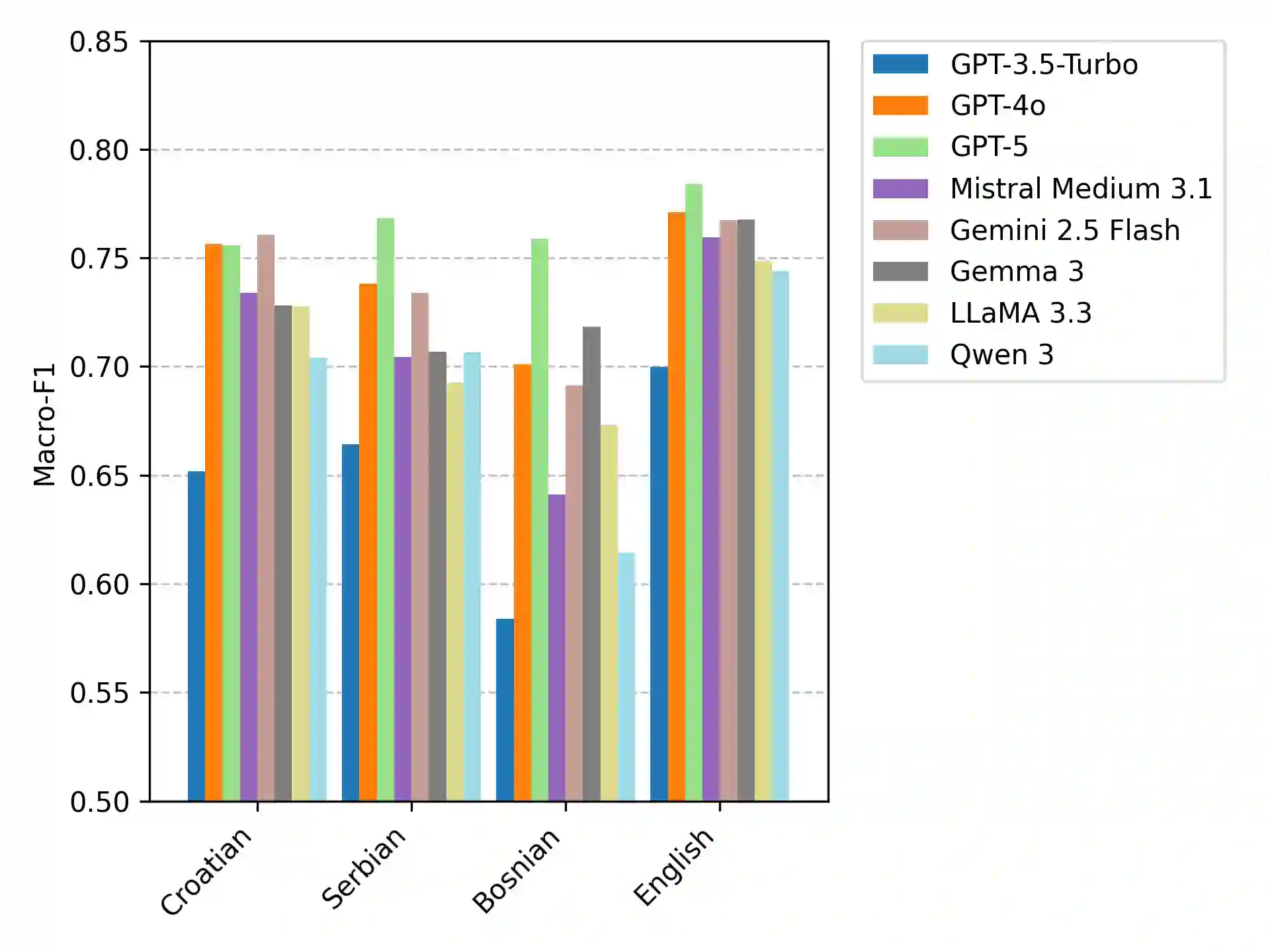
Until recently, fine-tuned BERT-like models provided state-of-the-art performance on text classification tasks. With the rise of instruction-tuned decoder-only models, commonly known as large language models (LLMs), the field has increasingly moved toward zero-shot and few-shot prompting. However, the performance of LLMs on text classification, particularly on less-resourced languages, remains under-explored. In this paper, we evaluate the performance of current language models on text classification tasks across several South Slavic languages. We compare openly available fine-tuned BERT-like models with a selection of open-source and closed-source LLMs across three tasks in three domains: sentiment classification in parliamentary speeches, topic classification in news articles and parliamentary speeches, and genre identification in web texts. Our results show that LLMs demonstrate strong zero-shot performance, often matching or surpassing fine-tuned BERT-like models. Moreover, when used in a zero-shot setup, LLMs perform comparably in South Slavic languages and English. However, we also point out key drawbacks of LLMs, including less predictable outputs, significantly slower inference, and higher computational costs. Due to these limitations, fine-tuned BERT-like models remain a more practical choice for large-scale automatic text annotation.
翻译:直到最近,经过微调的类BERT模型在文本分类任务上提供了最先进的性能。随着指令调优的仅解码器模型(通常称为大语言模型,LLMs)的兴起,该领域已越来越多地转向零样本和少样本提示学习。然而,LLMs在文本分类任务上的性能,尤其是在资源较少的语言上,仍然缺乏充分探索。本文评估了当前语言模型在多种南斯拉夫语言文本分类任务上的性能。我们在三个领域的三个任务中比较了公开可用的微调类BERT模型与一系列开源和闭源LLMs:议会演讲中的情感分类、新闻文章和议会演讲中的主题分类,以及网络文本中的体裁识别。我们的结果表明,LLMs展现出强大的零样本性能,通常能够匹配甚至超越微调的类BERT模型。此外,在零样本设置下,LLMs在南斯拉夫语言和英语上的表现相当。然而,我们也指出了LLMs的关键缺点,包括输出可预测性较低、推理速度显著更慢以及计算成本更高。由于这些限制,微调的类BERT模型在大规模自动文本标注中仍然是更实用的选择。