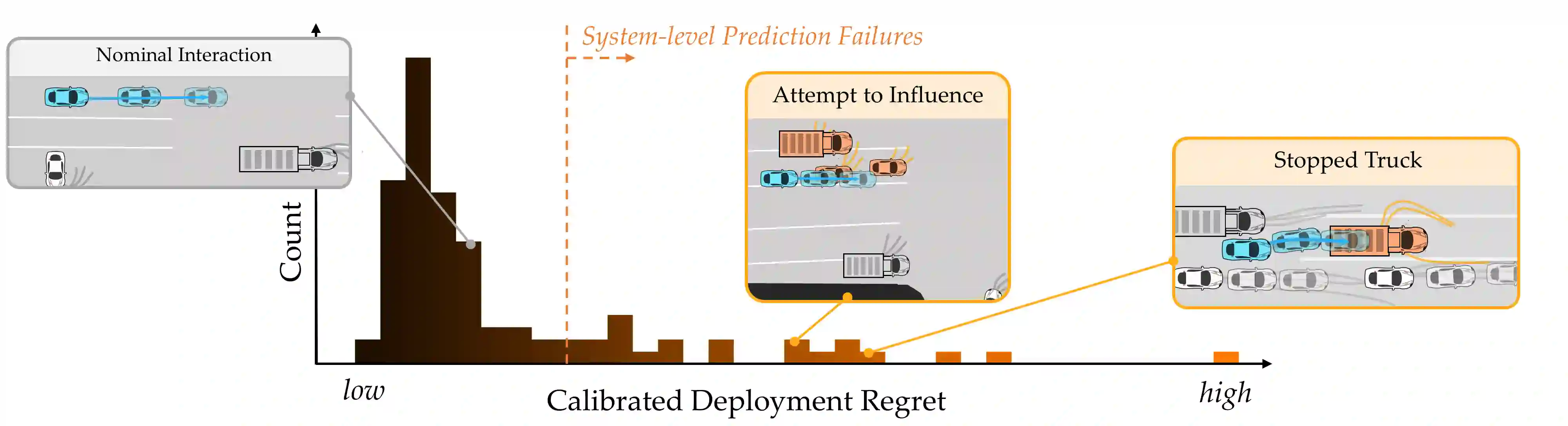
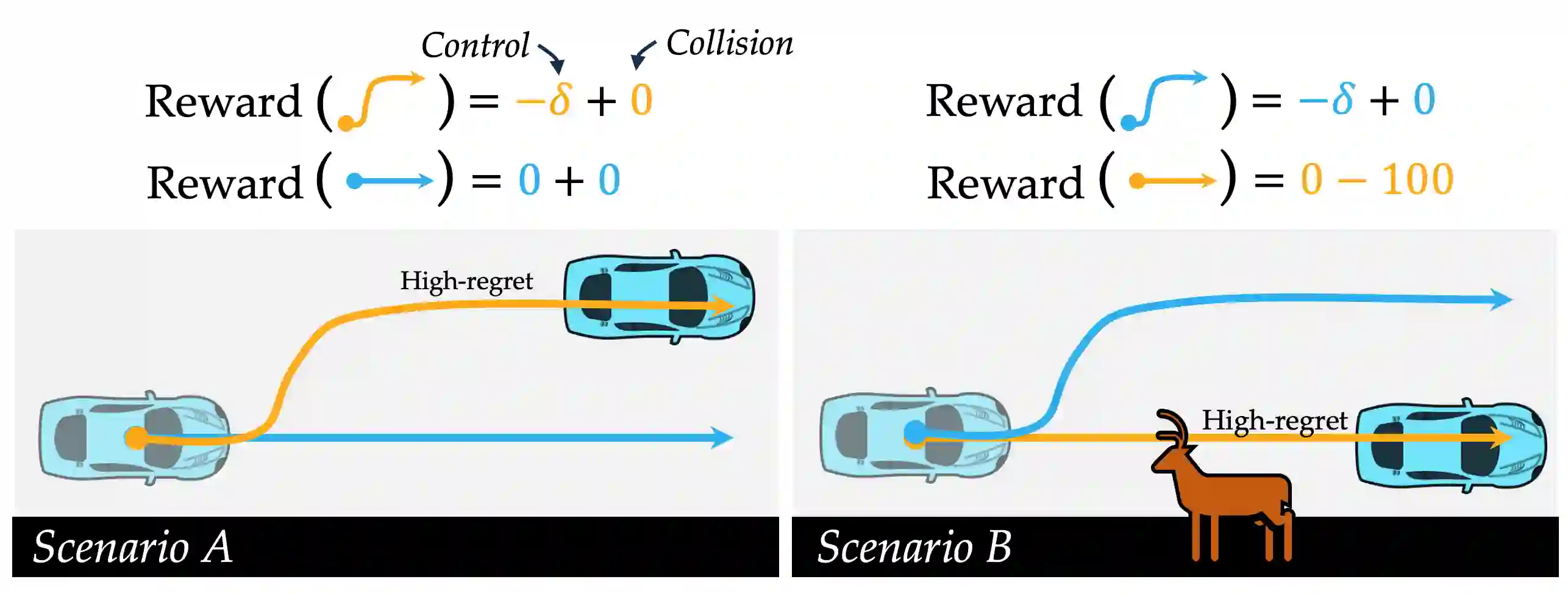
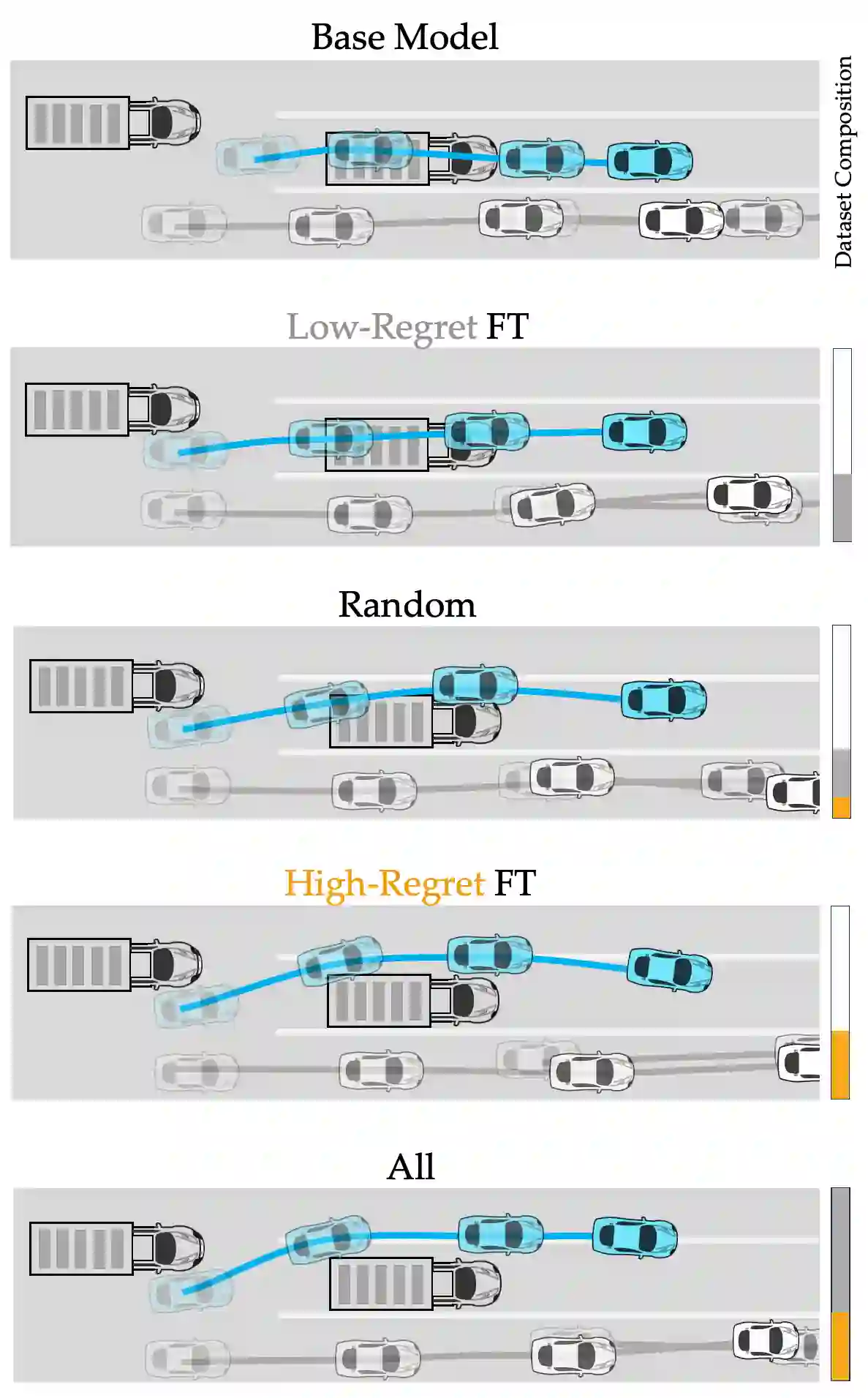
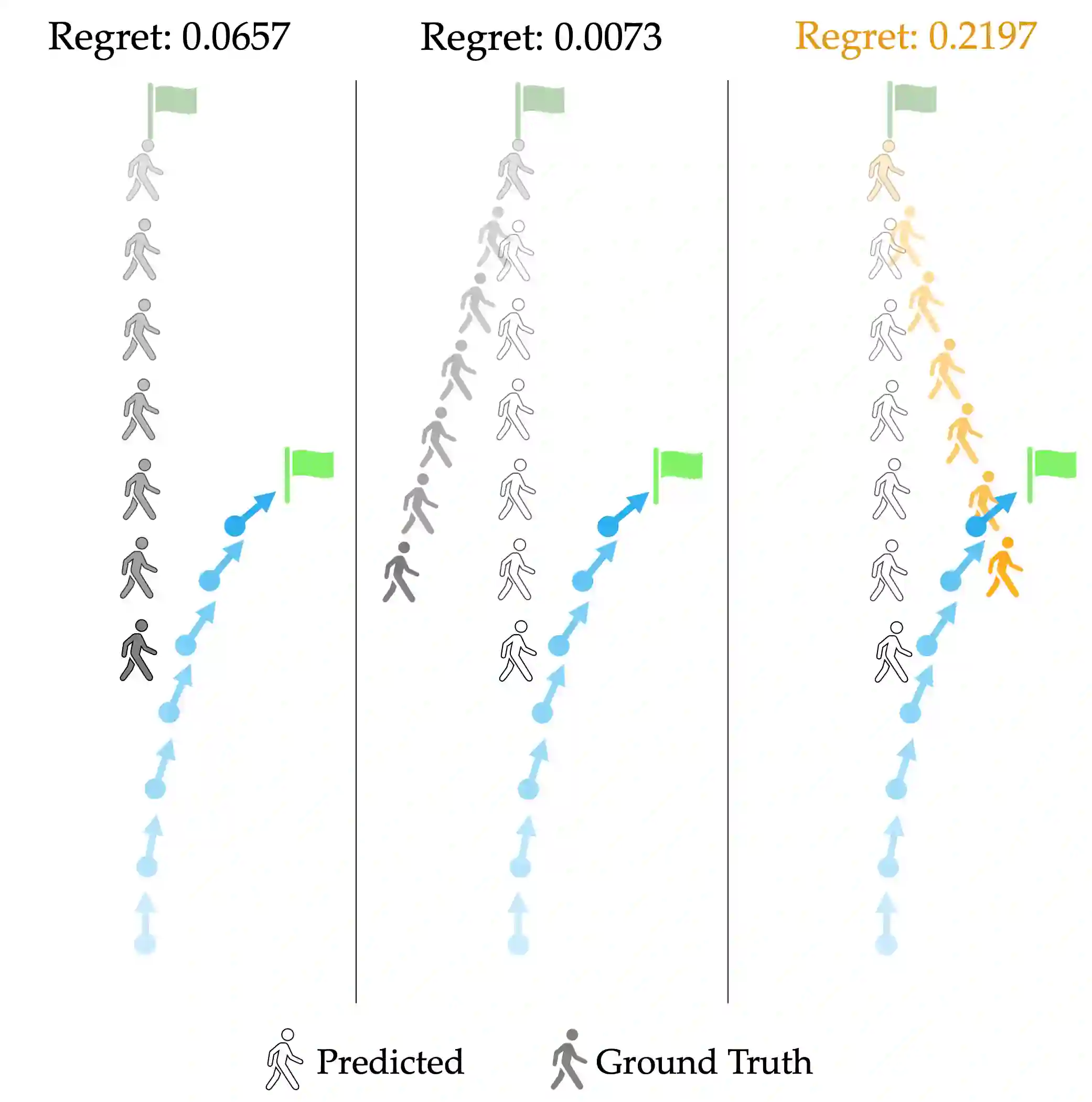
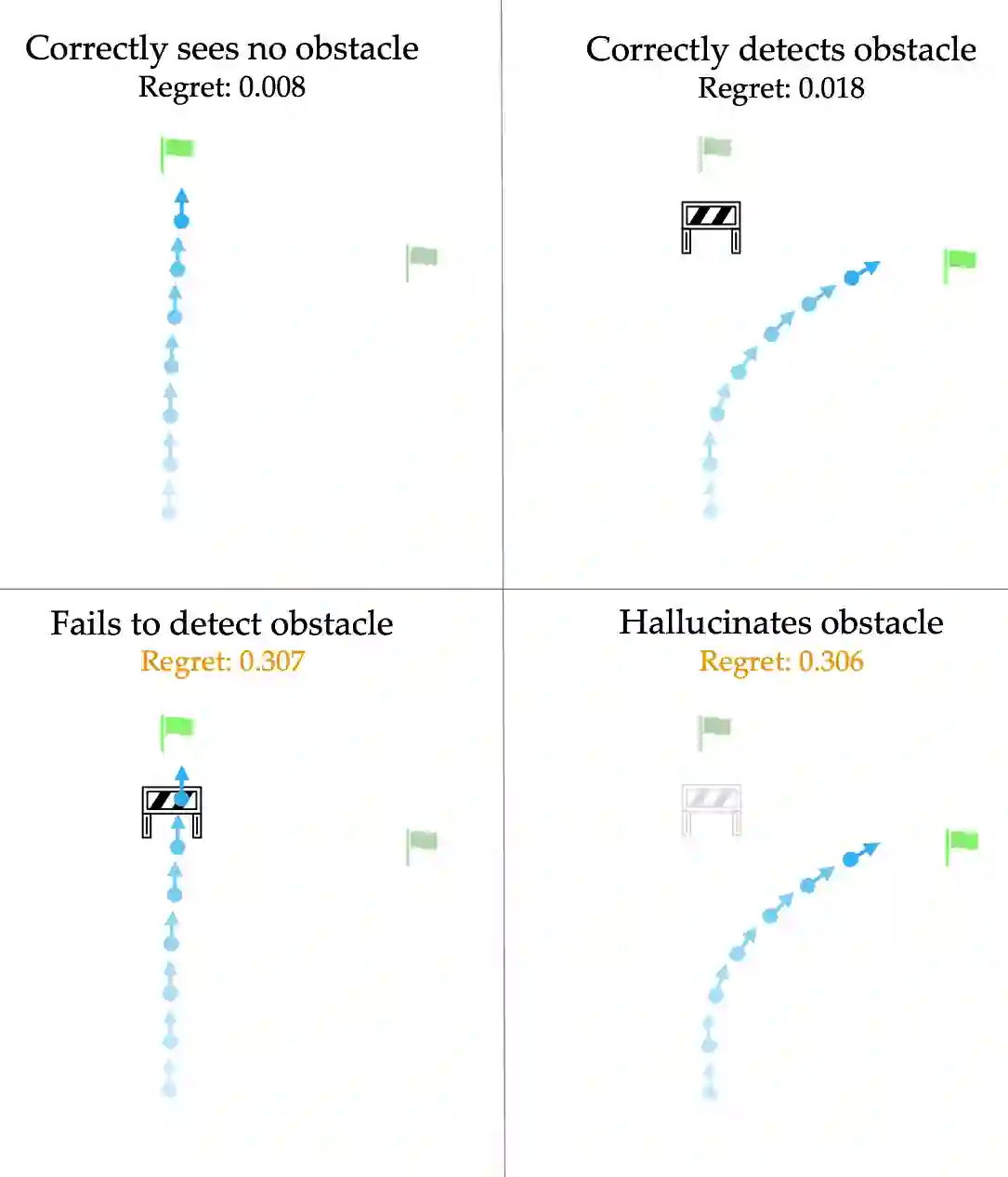
Robot decision-making increasingly relies on expressive data-driven human prediction models when operating around people. While these models are known to suffer from prediction errors in out-of-distribution interactions, not all prediction errors equally impact downstream robot performance. We identify that the mathematical notion of regret precisely characterizes the degree to which incorrect predictions of future interaction outcomes degraded closed-loop robot performance. However, canonical regret measures are poorly calibrated across diverse deployment interactions. We extend the canonical notion of regret by deriving a calibrated regret metric that generalizes from absolute reward space to probability space. With this transformation, our metric removes the need for explicit reward functions to calculate the robot's regret, enables fairer comparison of interaction anomalies across disparate deployment contexts, and facilitates targetted dataset construction of "system- level" prediction failures. We experimentally quantify the value of this high-regret interaction data for aiding the robot in improving its downstream decision-making. In a suite of closed- loop autonomous driving simulations, we find that fine-tuning ego-conditioned behavior predictors exclusively on high-regret human-robot interaction data can improve the robot's overall re-deployment performance with significantly (77%) less data.
翻译:机器人决策在与人共处时日益依赖富有表现力的数据驱动人类预测模型。尽管已知这些模型在分布外交互中会遭受预测误差,但并非所有预测误差对下游机器人性能的影响都相同。我们发现,遗憾的数学概念能精确表征对未来交互结果的错误预测如何降低闭环机器人性能。然而,经典的遗憾度量在多样化的部署交互中校准不佳。我们通过推导一种从绝对奖励空间推广到概率空间的校准遗憾度量,拓展了经典遗憾概念。借助这一变换,我们的度量消除了显式奖励函数计算机器人遗憾的需求,使得跨不同部署场景的交互异常比较更加公平,并促进了"系统级"预测失败的目标数据集构建。我们通过实验量化了这种高遗憾交互数据在帮助机器人改善下游决策中的价值。在一套闭环自动驾驶仿真中,我们发现仅在高质量人机交互数据上微调以自我为中心的条件行为预测器,可以显著(少用77%)提升机器人整体重新部署性能。