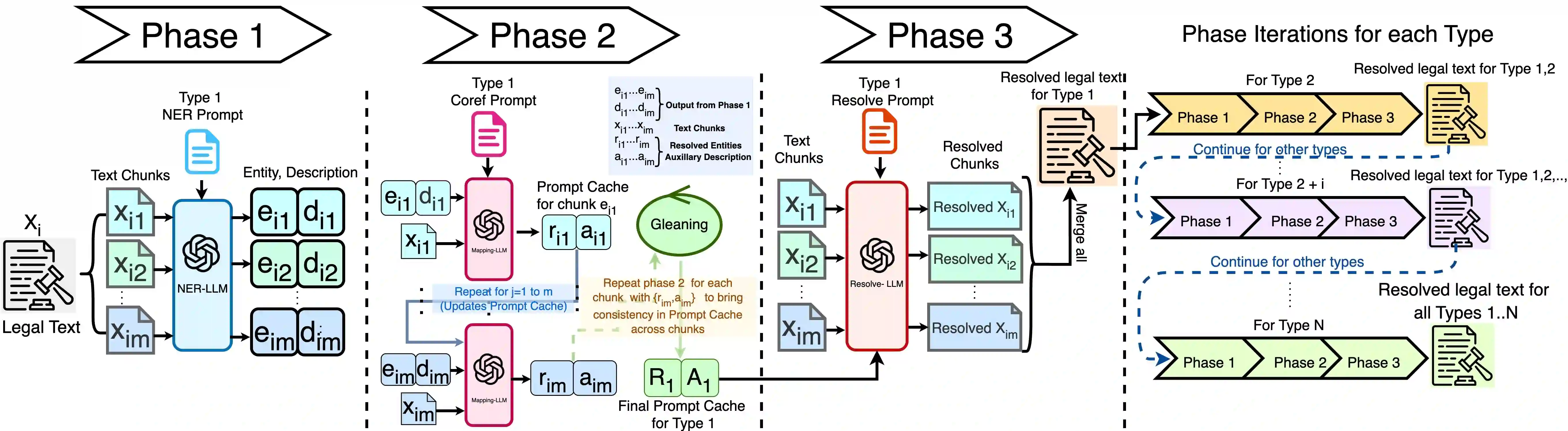
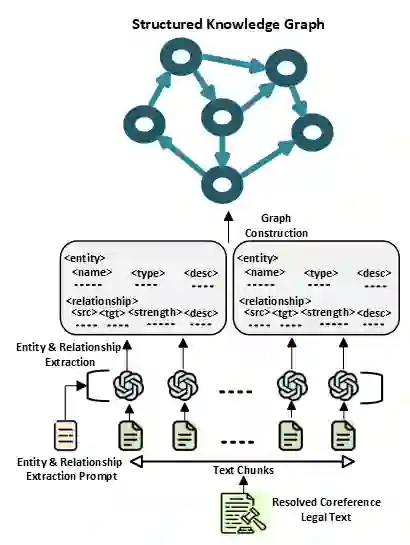
Human smuggling networks are complex and constantly evolving, making them difficult to analyze comprehensively. Legal case documents offer rich factual and procedural insights into these networks but are often long, unstructured, and filled with ambiguous or shifting references, posing significant challenges for automated knowledge graph (KG) construction. Existing methods either overlook coreference resolution or fail to scale beyond short text spans, leading to fragmented graphs and inconsistent entity linking. We propose LINK-KG, a modular framework that integrates a three-stage, LLM-guided coreference resolution pipeline with downstream KG extraction. At the core of our approach is a type-specific Prompt Cache, which consistently tracks and resolves references across document chunks, enabling clean and disambiguated narratives for structured knowledge graph construction from both short and long legal texts. LINK-KG reduces average node duplication by 45.21% and noisy nodes by 32.22% compared to baseline methods, resulting in cleaner and more coherent graph structures. These improvements establish LINK-KG as a strong foundation for analyzing complex criminal networks.
翻译:人口走私网络具有复杂且不断演变的特性,使得对其进行全面分析变得十分困难。法律案件文档为理解这些网络提供了丰富的事实与程序性信息,但这些文档通常篇幅冗长、结构松散,且包含大量模糊或动态变化的指代关系,这为自动化知识图谱构建带来了显著挑战。现有方法要么忽略了指代消解环节,要么难以扩展到短文本范围之外,导致生成的图谱碎片化严重且实体链接不一致。本文提出LINK-KG,一个模块化框架,将基于大语言模型的三阶段指代消解流程与下游知识图谱抽取相结合。该方法的核心理念是类型化提示缓存机制,它能够跨文档片段持续追踪并消解指代关系,从而为从长短不一的法律文本中构建结构化知识图谱提供清晰且无歧义的叙事基础。与基线方法相比,LINK-KG将平均节点重复率降低了45.21%,噪声节点减少了32.22%,从而生成更清晰、更连贯的图谱结构。这些改进使LINK-KG成为分析复杂犯罪网络的坚实基础。