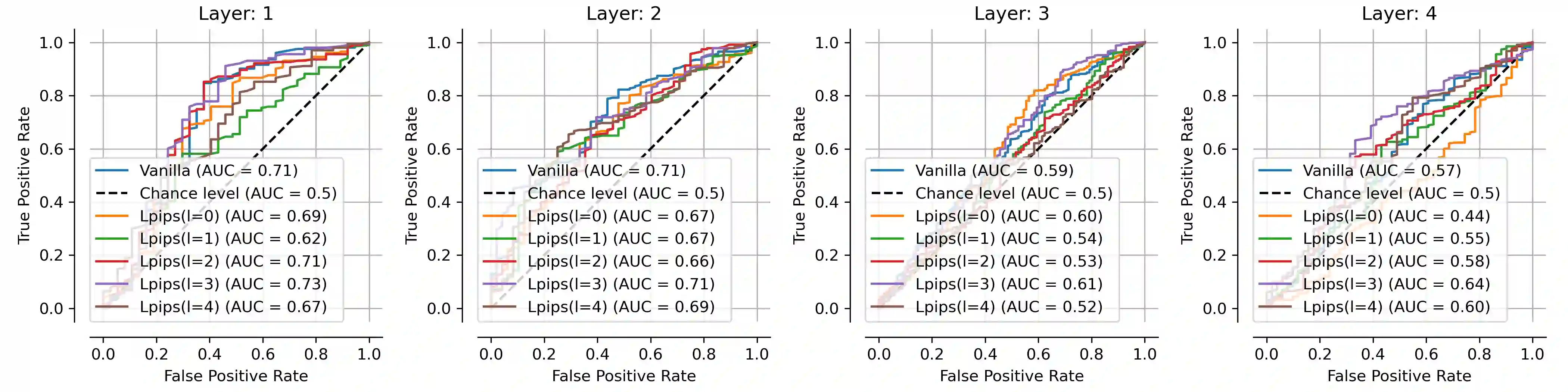
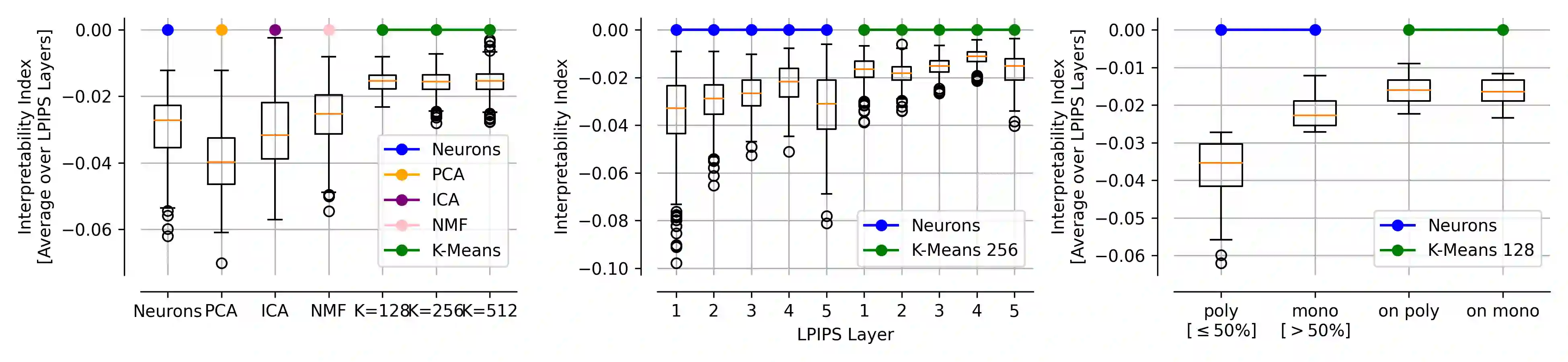
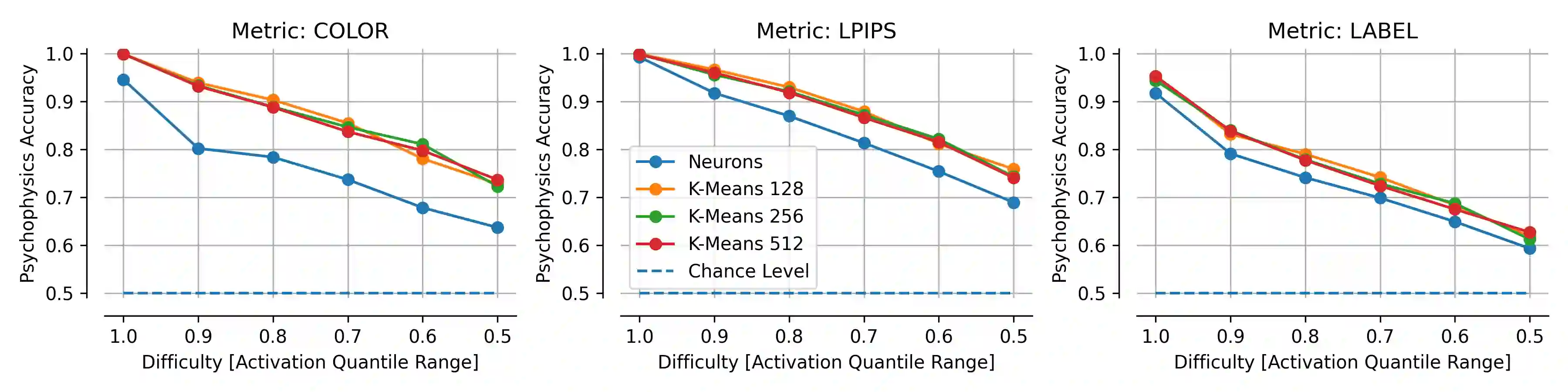
Single neurons in neural networks are often ``interpretable'' in that they represent individual, intuitively meaningful features. However, many neurons exhibit $\textit{mixed selectivity}$, i.e., they represent multiple unrelated features. A recent hypothesis proposes that features in deep networks may be represented in $\textit{superposition}$, i.e., on non-orthogonal axes by multiple neurons, since the number of possible interpretable features in natural data is generally larger than the number of neurons in a given network. Accordingly, we should be able to find meaningful directions in activation space that are not aligned with individual neurons. Here, we propose (1) an automated method for quantifying visual interpretability that is validated against a large database of human psychophysics judgments of neuron interpretability, and (2) an approach for finding meaningful directions in network activation space. We leverage these methods to discover directions in convolutional neural networks that are more intuitively meaningful than individual neurons, as we confirm and investigate in a series of analyses. Moreover, we apply the same method to two recent datasets of visual neural responses in the brain and find that our conclusions largely transfer to real neural data, suggesting that superposition might be deployed by the brain. This also provides a link with disentanglement and raises fundamental questions about robust, efficient and factorized representations in both artificial and biological neural systems.
翻译:神经网络中的单个神经元通常具有“可解释性”,即它们代表各自独立且直观上有意义的特征。然而,许多神经元表现出混合选择性,即它们同时表征多个无关特征。最新假说提出,深度网络中的特征可能以叠加形式表征,即由多个神经元沿非正交轴共同编码,这是因为自然数据中可能存在的可解释特征数量通常大于给定网络中的神经元数量。据此,我们应当能够在激活空间中寻找到并非与单个神经元对齐的有意义方向。本文提出:(1) 一种自动量化视觉可解释性的方法,该方法通过大规模人类心理物理学神经元可解释性判断数据库进行验证;(2) 一种在神经网络激活空间中寻找有意义方向的方法。我们利用这些方法在卷积神经网络中发现了比单个神经元更具直观意义的特征方向,并通过一系列分析予以验证与探究。此外,我们将相同方法应用于两组最新的大脑视觉神经响应数据集,发现结论在很大程度上可迁移至真实神经数据,表明大脑可能也采用了叠加表征机制。这为解耦学习提供了关联纽带,并对人工与生物神经系统中鲁棒、高效及分解式表征提出了根本性问题。