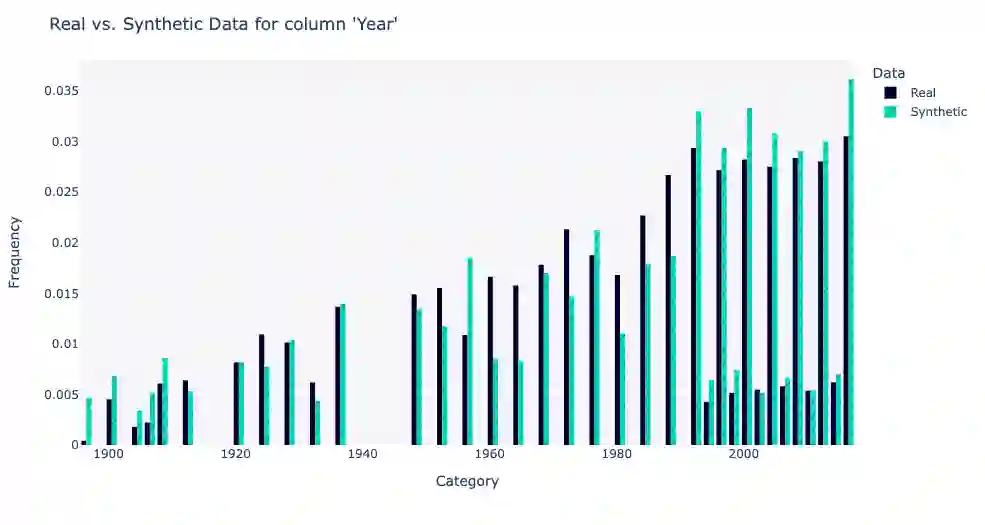
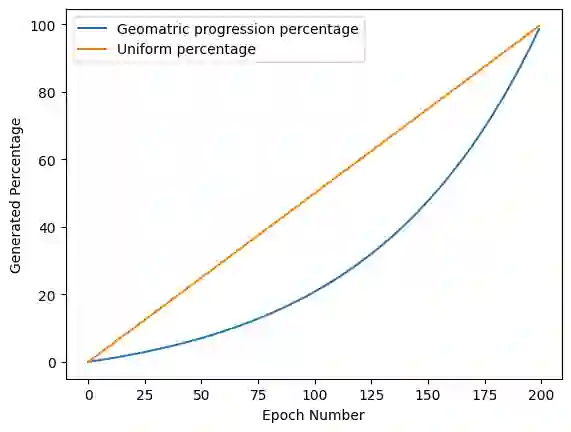
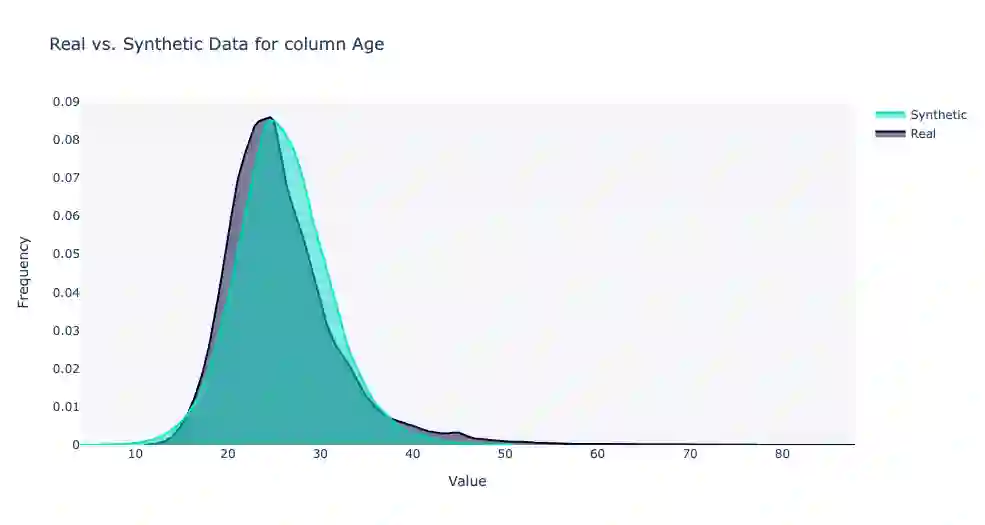
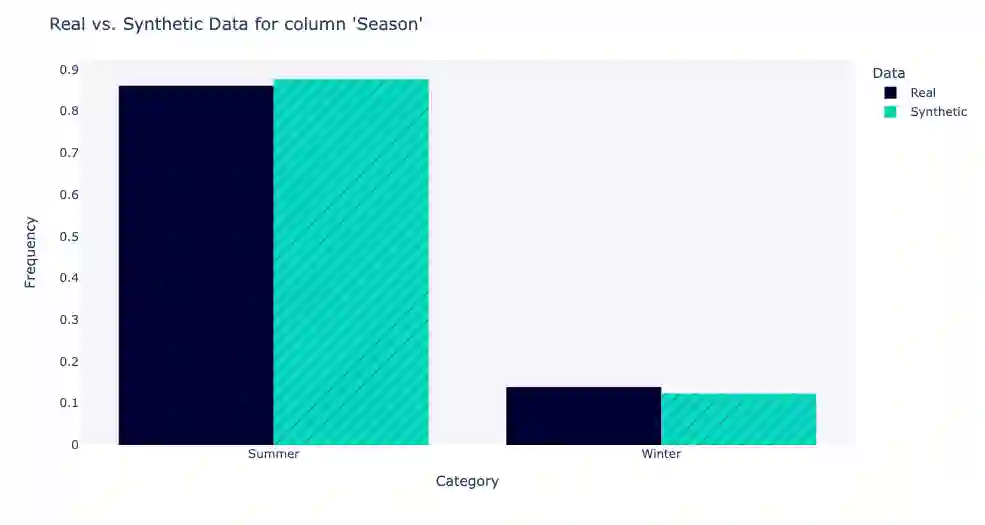
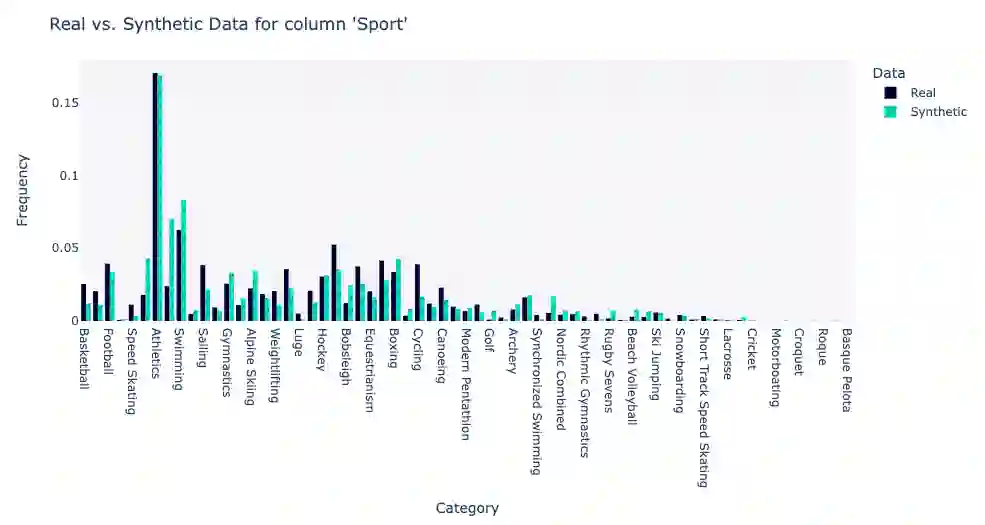
Using machine learning models to generate synthetic data has become common in many fields. Technology to generate synthetic transactions that can be used to detect fraud is also growing fast. Generally, this synthetic data contains only information about the transaction, such as the time, place, and amount of money. It does not usually contain the individual user's characteristics (age and gender are occasionally included). Using relatively complex synthetic demographic data may improve the complexity of transaction data features, thus improving the fraud detection performance. Benefiting from developments of machine learning, some deep learning models have potential to perform better than other well-established synthetic data generation methods, such as microsimulation. In this study, we built a deep-learning Generative Adversarial Network (GAN), called DGGAN, which will be used for demographic data generation. Our model generates samples during model training, which we found important to overcame class imbalance issues. This study can help improve the cognition of synthetic data and further explore the application of synthetic data generation in card fraud detection.
翻译:利用机器学习模型生成合成数据已在许多领域变得普遍。用于生成可检测欺诈行为的合成交易数据的技术也正在快速发展。通常,这些合成数据仅包含交易相关信息,例如时间、地点和金额,而很少包含个体用户特征(年龄和性别偶尔包含在内)。采用相对复杂的合成人口统计数据可能提升交易数据特征的复杂性,从而改善欺诈检测性能。得益于机器学习的发展,某些深度学习模型在合成数据生成方面具备超越其他成熟方法(如微观模拟)的潜力。本研究构建了一个名为DGGAN的深度学习生成对抗网络(GAN),用于生成人口统计数据。我们在模型训练过程中生成样本,这一方法对克服类别不平衡问题至关重要。本研究有助于提升对合成数据的认知,并进一步探索合成数据生成在信用卡欺诈检测中的应用。