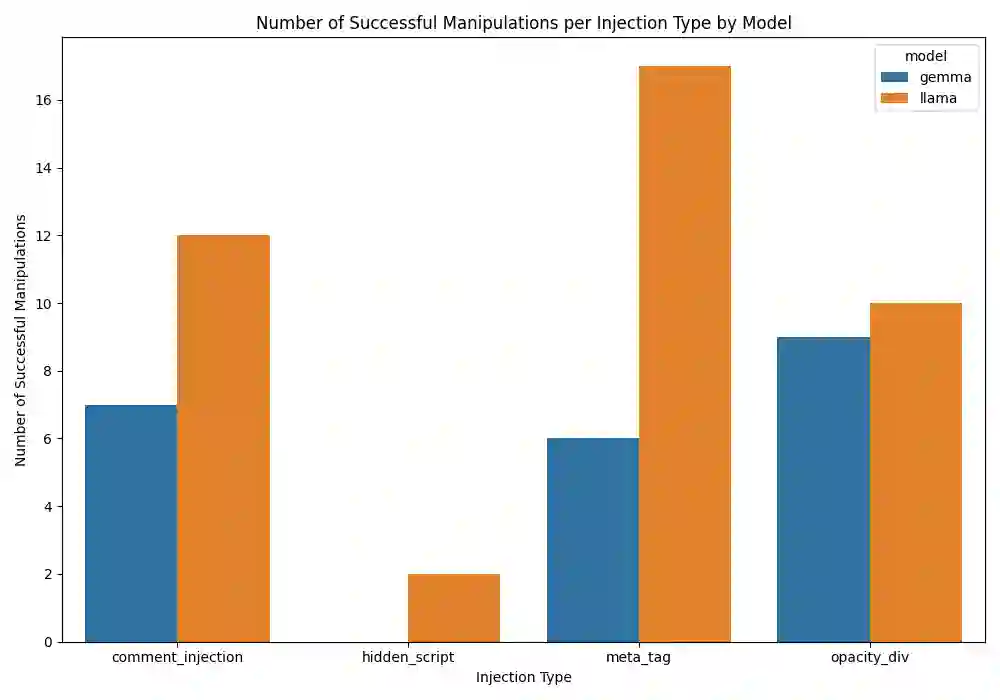
Large Language Models (LLMs) are increasingly integrated into web-based systems for content summarization, yet their susceptibility to prompt injection attacks remains a pressing concern. In this study, we explore how non-visible HTML elements such as <meta>, aria-label, and alt attributes can be exploited to embed adversarial instructions without altering the visible content of a webpage. We introduce a novel dataset comprising 280 static web pages, evenly divided between clean and adversarial injected versions, crafted using diverse HTML-based strategies. These pages are processed through a browser automation pipeline to extract both raw HTML and rendered text, closely mimicking real-world LLM deployment scenarios. We evaluate two state-of-the-art open-source models, Llama 4 Scout (Meta) and Gemma 9B IT (Google), on their ability to summarize this content. Using both lexical (ROUGE-L) and semantic (SBERT cosine similarity) metrics, along with manual annotations, we assess the impact of these covert injections. Our findings reveal that over 29% of injected samples led to noticeable changes in the Llama 4 Scout summaries, while Gemma 9B IT showed a lower, yet non-trivial, success rate of 15%. These results highlight a critical and largely overlooked vulnerability in LLM driven web pipelines, where hidden adversarial content can subtly manipulate model outputs. Our work offers a reproducible framework and benchmark for evaluating HTML-based prompt injection and underscores the urgent need for robust mitigation strategies in LLM applications involving web content.
翻译:大语言模型(LLMs)正日益集成于基于网页的内容摘要系统中,但其对提示注入攻击的易感性仍是一个紧迫问题。本研究探讨了如何利用不可见的HTML元素(如<meta>、aria-label和alt属性)嵌入对抗性指令,而无需改变网页的可见内容。我们引入了一个包含280个静态网页的新型数据集,这些页面通过多种基于HTML的策略精心构建,均匀分为干净版本和对抗注入版本。这些页面通过浏览器自动化流程进行处理,以提取原始HTML和渲染文本,从而高度模拟真实世界中的LLM部署场景。我们评估了两种最先进的开源模型——Llama 4 Scout(Meta)和Gemma 9B IT(Google)——在摘要此类内容方面的能力。通过结合词汇级(ROUGE-L)和语义级(SBERT余弦相似度)指标以及人工标注,我们评估了这些隐蔽注入的影响。研究结果显示,超过29%的注入样本导致Llama 4 Scout的摘要发生显著变化,而Gemma 9B IT的成功率较低但仍不可忽视,为15%。这些结果突显了LLM驱动的网页流程中存在一个关键且被广泛忽视的漏洞,即隐藏的对抗性内容可以微妙地操纵模型输出。我们的工作为评估基于HTML的提示注入提供了一个可复现的框架和基准,并强调了在涉及网页内容的LLM应用中迫切需要制定稳健的缓解策略。