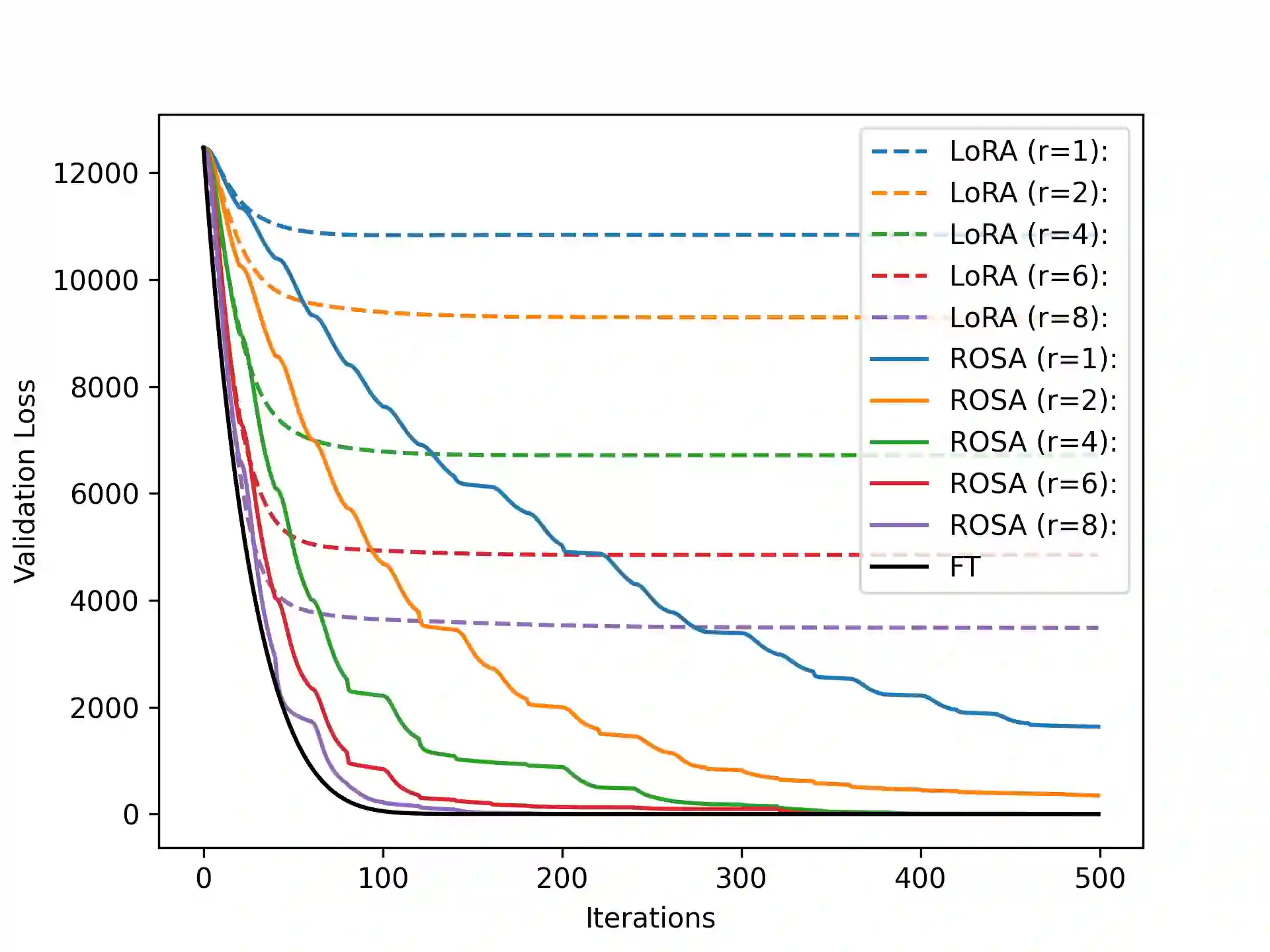
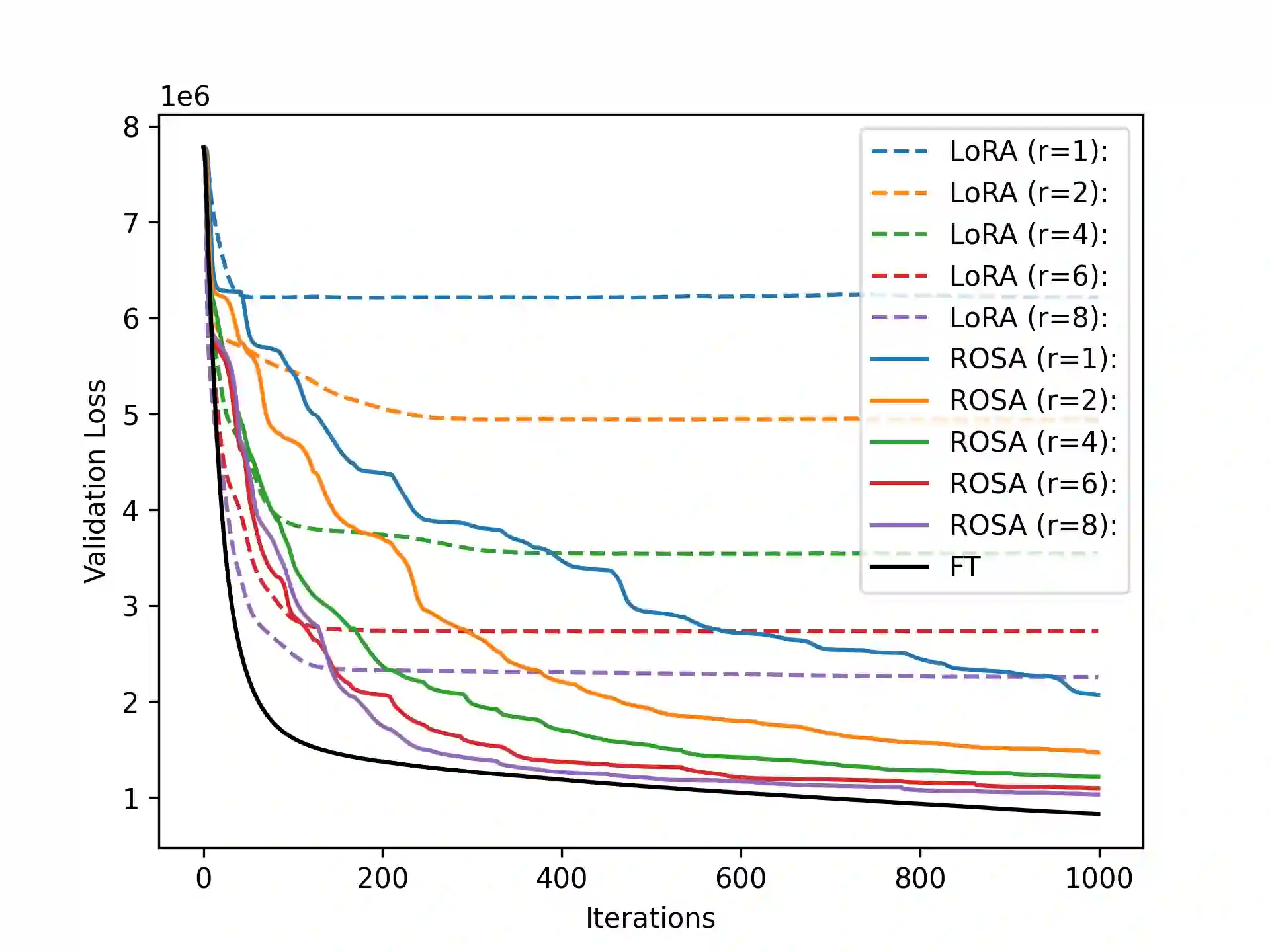
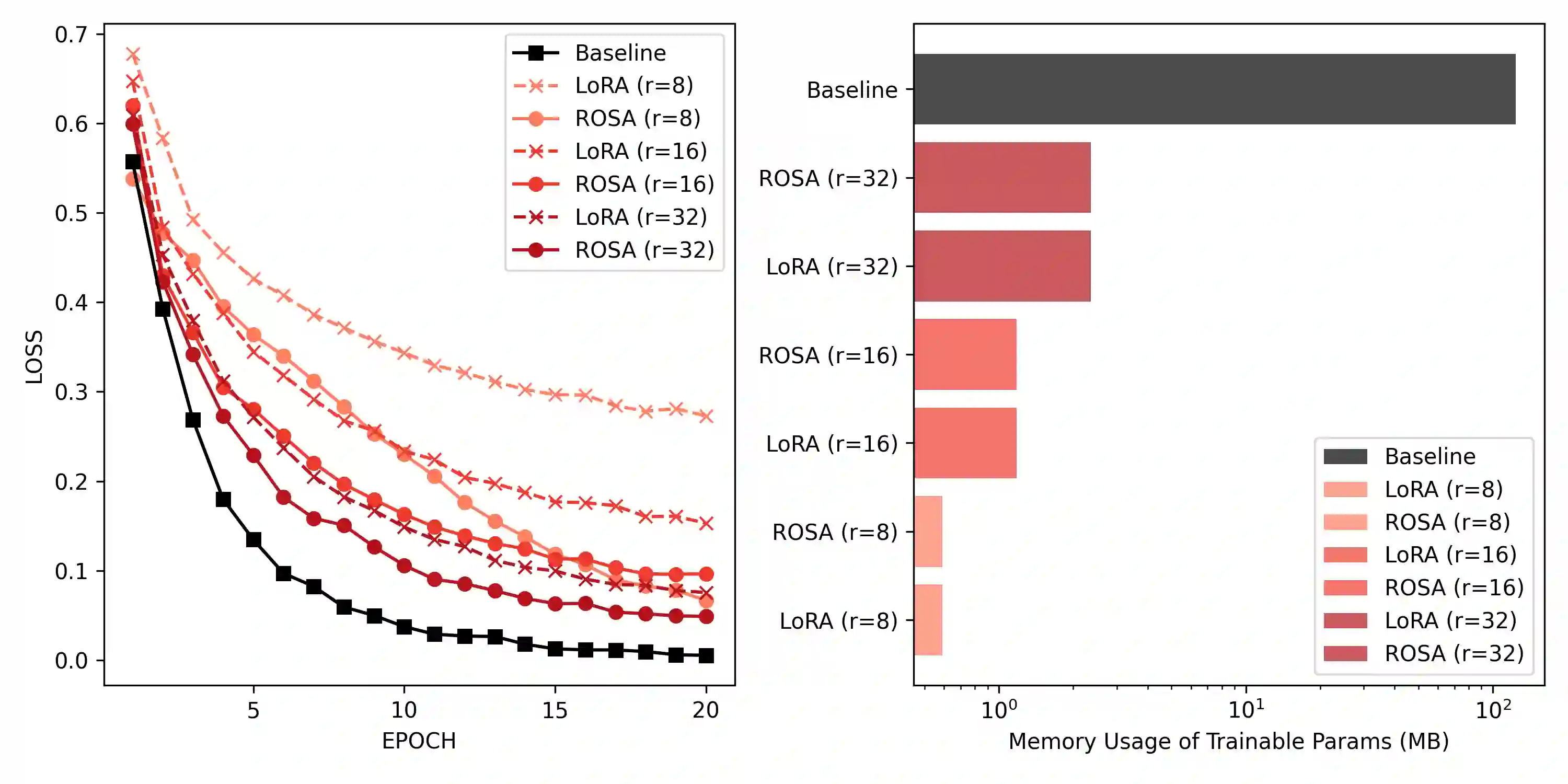
Model training requires significantly more memory, compared with inference. Parameter efficient fine-tuning (PEFT) methods provide a means of adapting large models to downstream tasks using less memory. However, existing methods such as adapters, prompt tuning or low-rank adaptation (LoRA) either introduce latency overhead at inference time or achieve subpar downstream performance compared with full fine-tuning. In this work we propose Random Subspace Adaptation (ROSA), a method that outperforms previous PEFT methods by a significant margin, while maintaining a zero latency overhead during inference time. In contrast to previous methods, ROSA is able to adapt subspaces of arbitrarily large dimension, better approximating full-finetuning. We demonstrate both theoretically and experimentally that this makes ROSA strictly more expressive than LoRA, without consuming additional memory during runtime. As PEFT methods are especially useful in the natural language processing domain, where models operate on scales that make full fine-tuning very expensive, we evaluate ROSA in two common NLP scenarios: natural language generation (NLG) and natural language understanding (NLU) with GPT-2 and RoBERTa, respectively. We show that on almost every GLUE task ROSA outperforms LoRA by a significant margin, while also outperforming LoRA on NLG tasks. Our code is available at https://github.com/rosa-paper/rosa
翻译:模型训练所需内存显著高于推理过程。参数高效微调方法能够以较少内存将大模型适配至下游任务。然而,现有方法如适配器、提示调优或低秩自适应在推理时会产生延迟开销,或在下游性能上逊色于全参数微调。本研究提出随机子空间自适应方法,该方法在保持推理阶段零延迟开销的同时,以显著优势超越现有参数高效微调方法。与先前方法不同,ROSA能够自适应任意维度的子空间,从而更逼近全参数微调效果。我们通过理论分析与实验验证表明,该方法在运行时不消耗额外内存的前提下,其表达能力严格优于LoRA。鉴于参数高效微调方法在自然语言处理领域尤为重要——该领域模型规模使得全参数微调成本极高,我们在两种典型NLP场景中评估ROSA:分别使用GPT-2和RoBERTa进行自然语言生成与自然语言理解任务。实验表明,在几乎所有GLUE任务上ROSA均显著优于LoRA,同时在自然语言生成任务上也超越LoRA。代码已开源:https://github.com/rosa-paper/rosa