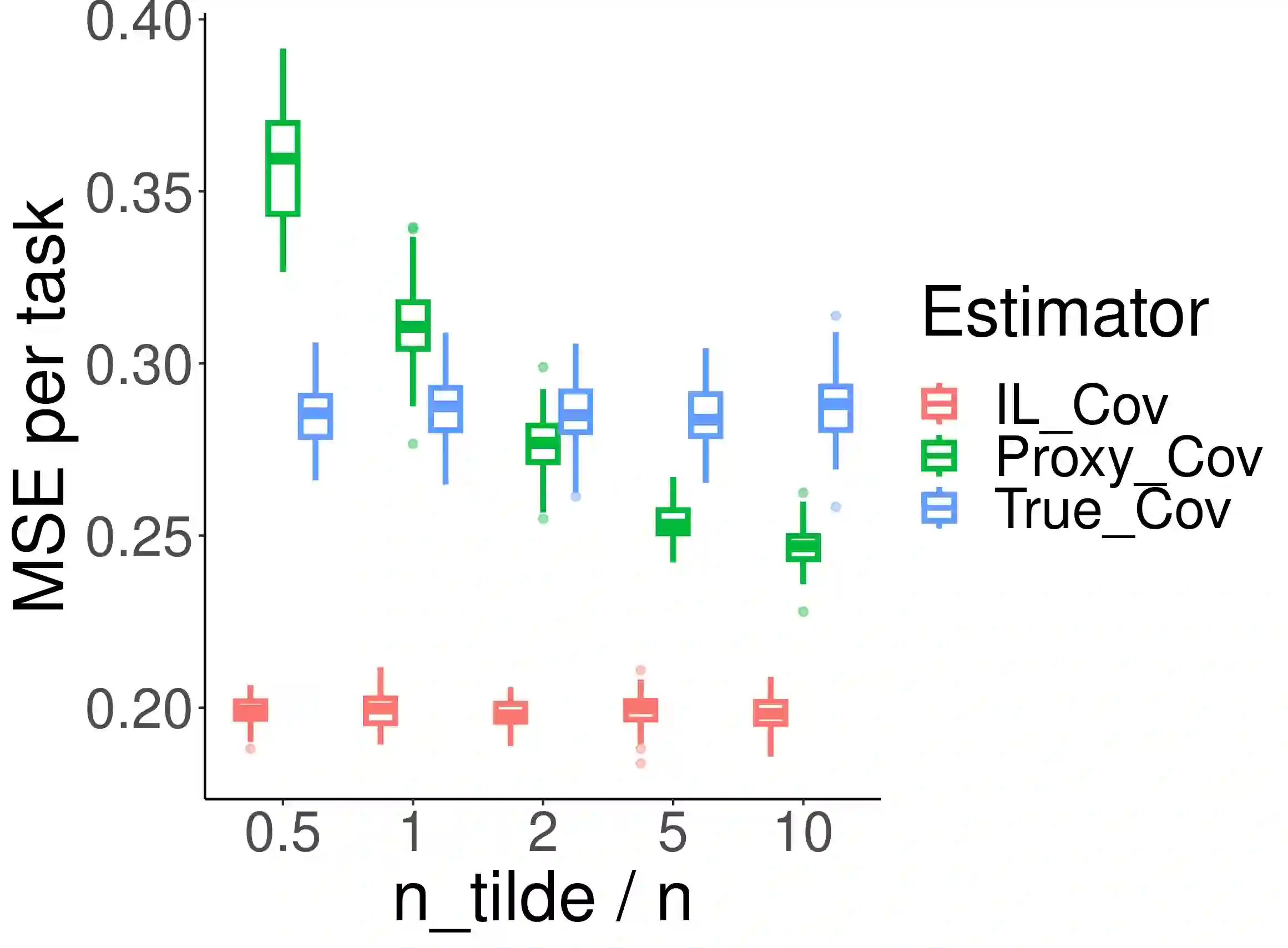
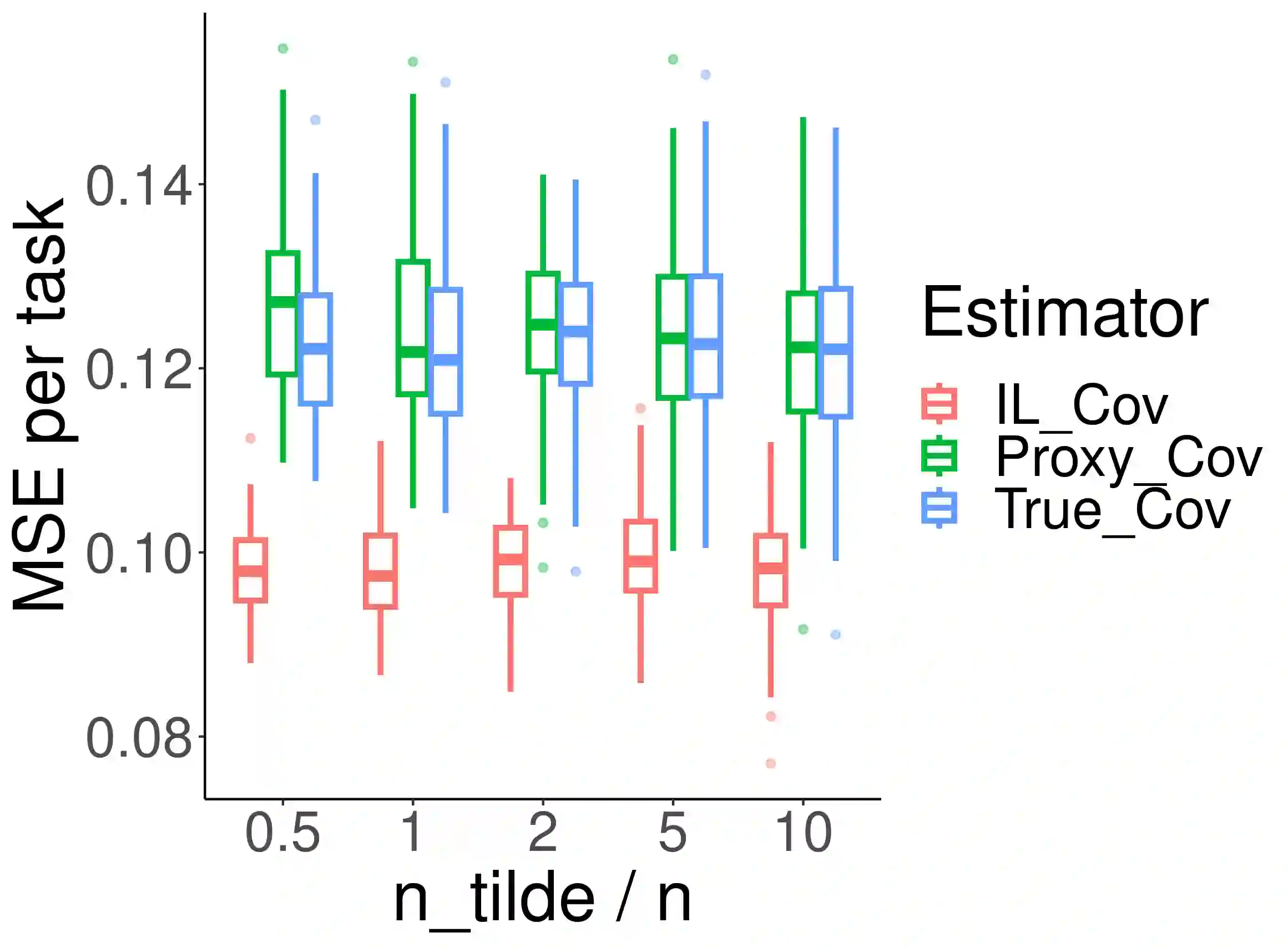
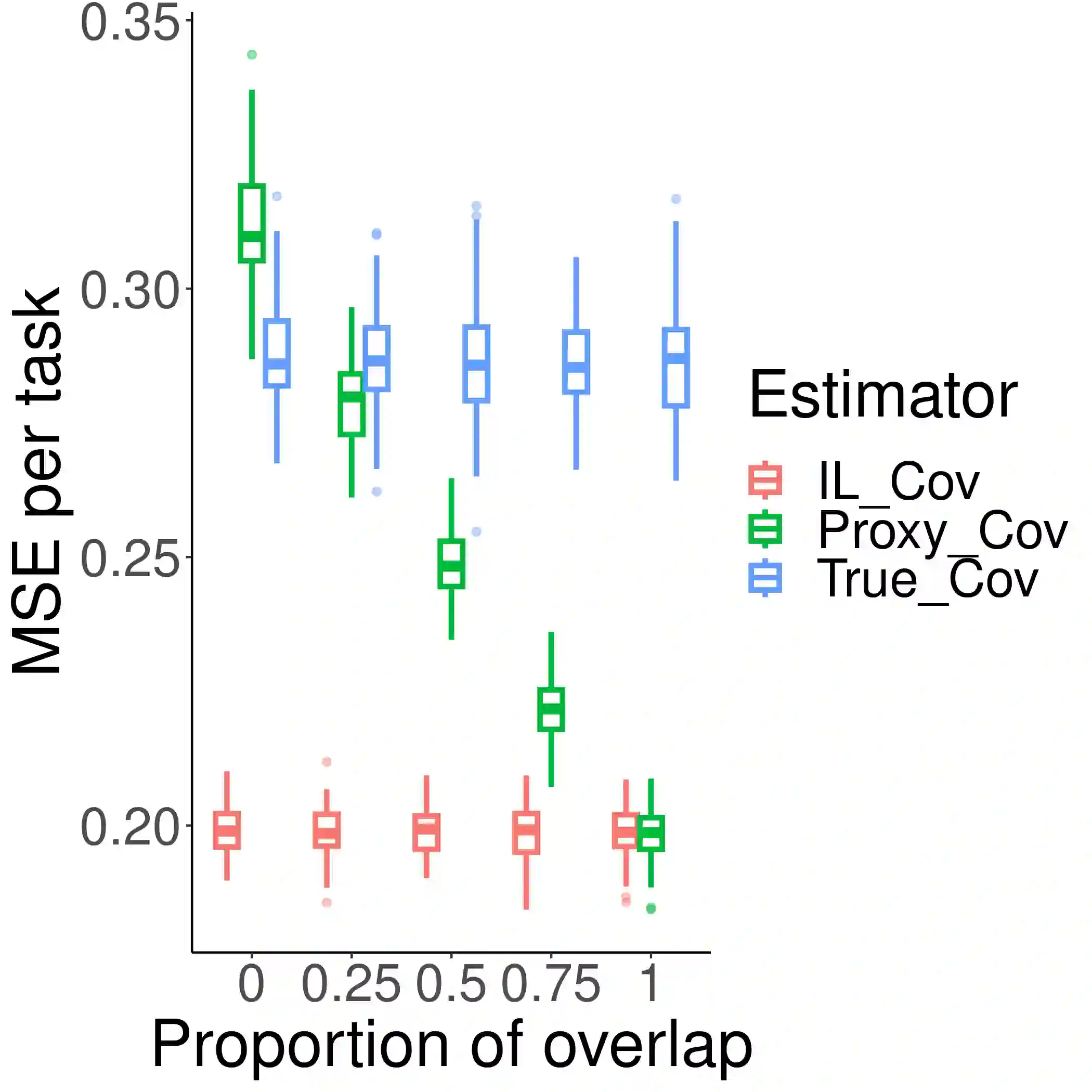
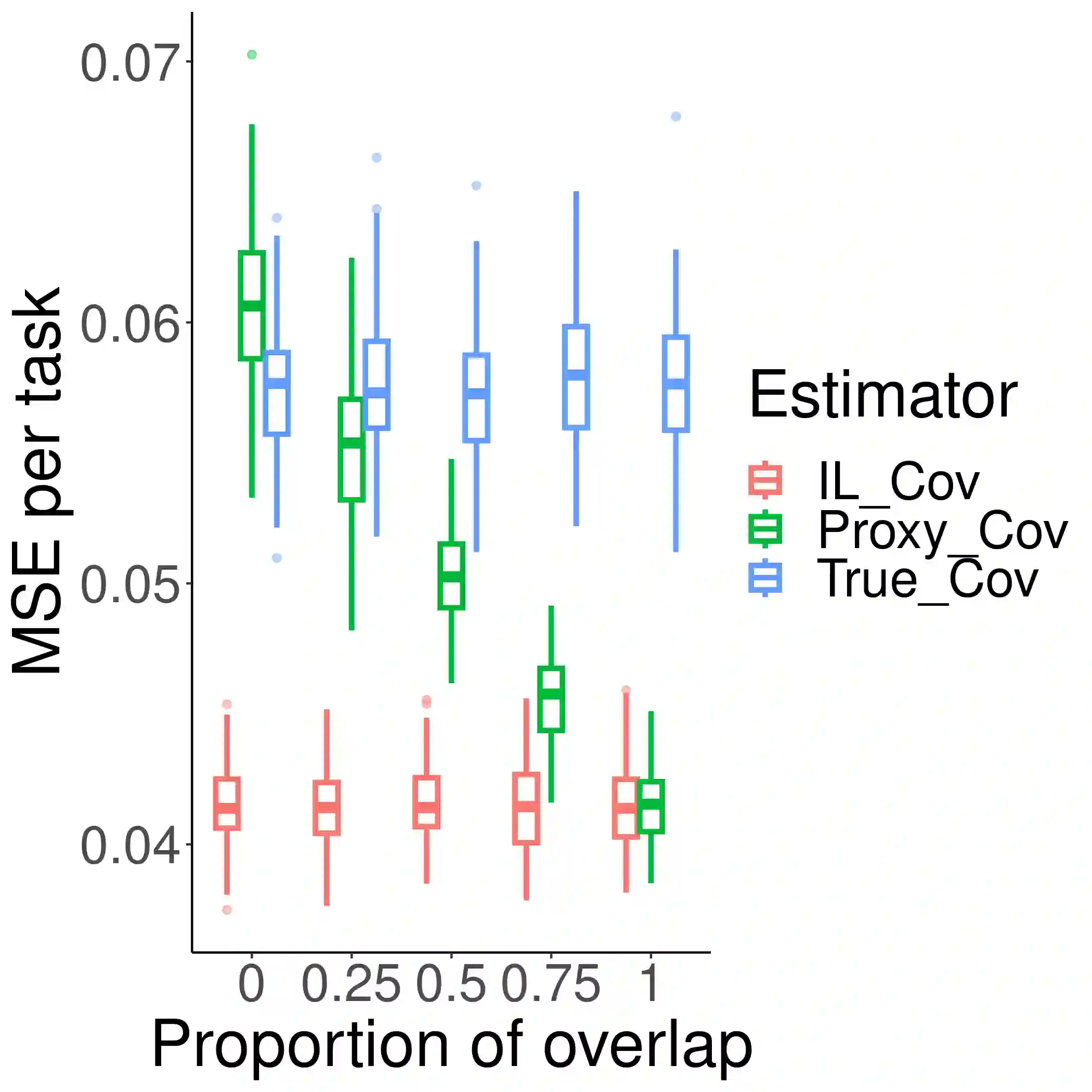
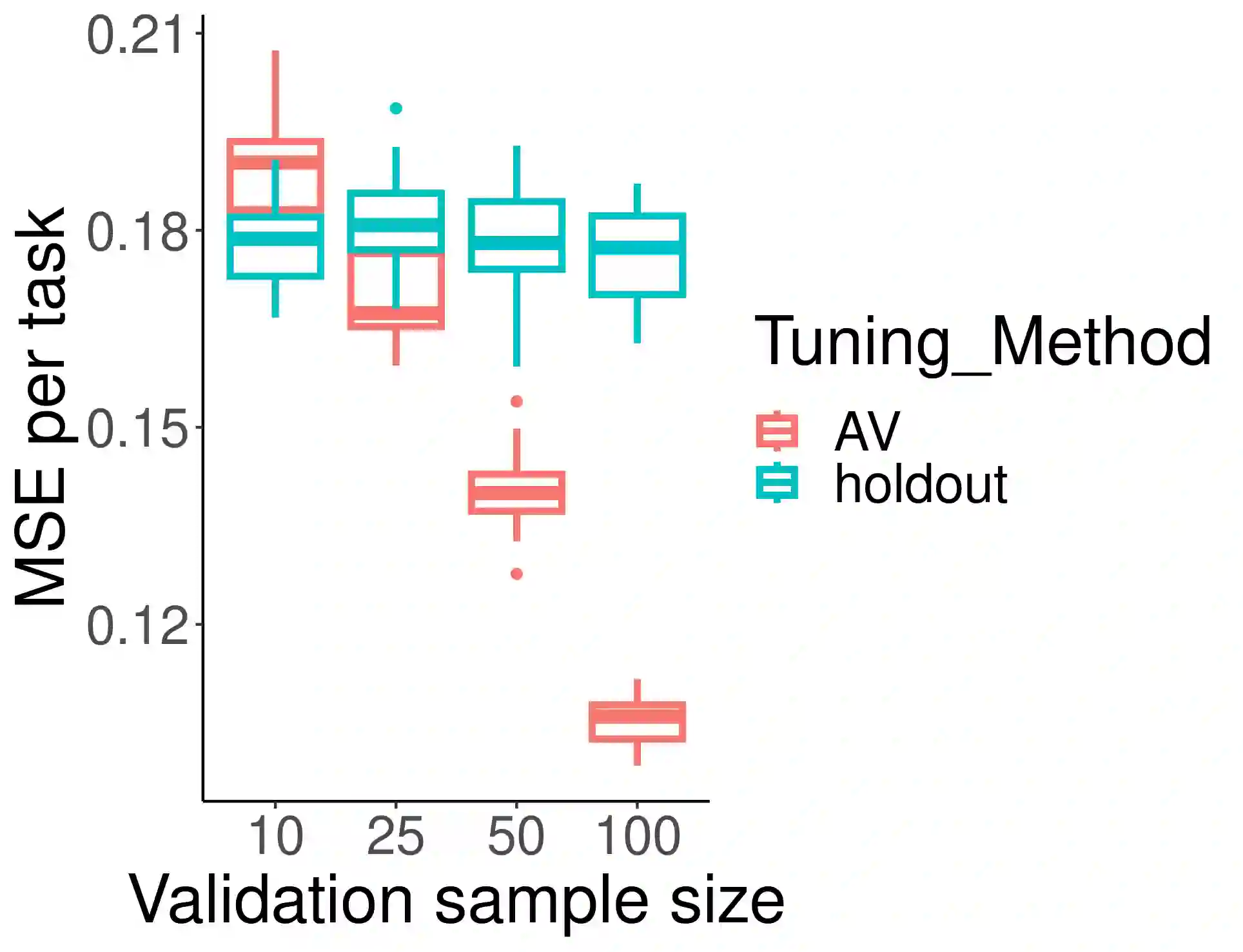
Multi-task learning has emerged as a powerful machine learning paradigm for integrating data from multiple sources, leveraging similarities between tasks to improve overall model performance. However, the application of multi-task learning to real-world settings is hindered by data-sharing constraints, especially in healthcare settings. To address this challenge, we propose a flexible multi-task learning framework utilizing summary statistics from various sources. Additionally, we present an adaptive parameter selection approach based on a variant of Lepski's method, allowing for data-driven tuning parameter selection when only summary statistics are available. Our systematic non-asymptotic analysis characterizes the performance of the proposed methods under various regimes of the sample complexity and overlap. We demonstrate our theoretical findings and the performance of the method through extensive simulations. This work offers a more flexible tool for training related models across various domains, with practical implications in genetic risk prediction and many other fields.
翻译:多任务学习已成为一种强大的机器学习范式,能够整合来自多个来源的数据,通过利用任务之间的相似性提升整体模型性能。然而,多任务学习在实际场景——尤其是医疗场景——中的应用受到数据共享约束的阻碍。为解决这一挑战,我们提出了一种灵活的基于多来源汇总统计数据的多任务学习框架。此外,我们提出了一种基于莱普斯基方法变体的自适应参数选择方法,使得在仅有汇总统计数据的条件下能够实现数据驱动的调参选择。通过系统性非渐近分析,我们刻画了所提方法在不同样本复杂度和重叠程度情境下的性能表现。我们通过大量仿真实验验证了理论发现与方法的有效性。本研究为跨领域训练相关模型提供了更灵活的工具,在遗传风险预测及其他诸多领域具有实际应用价值。