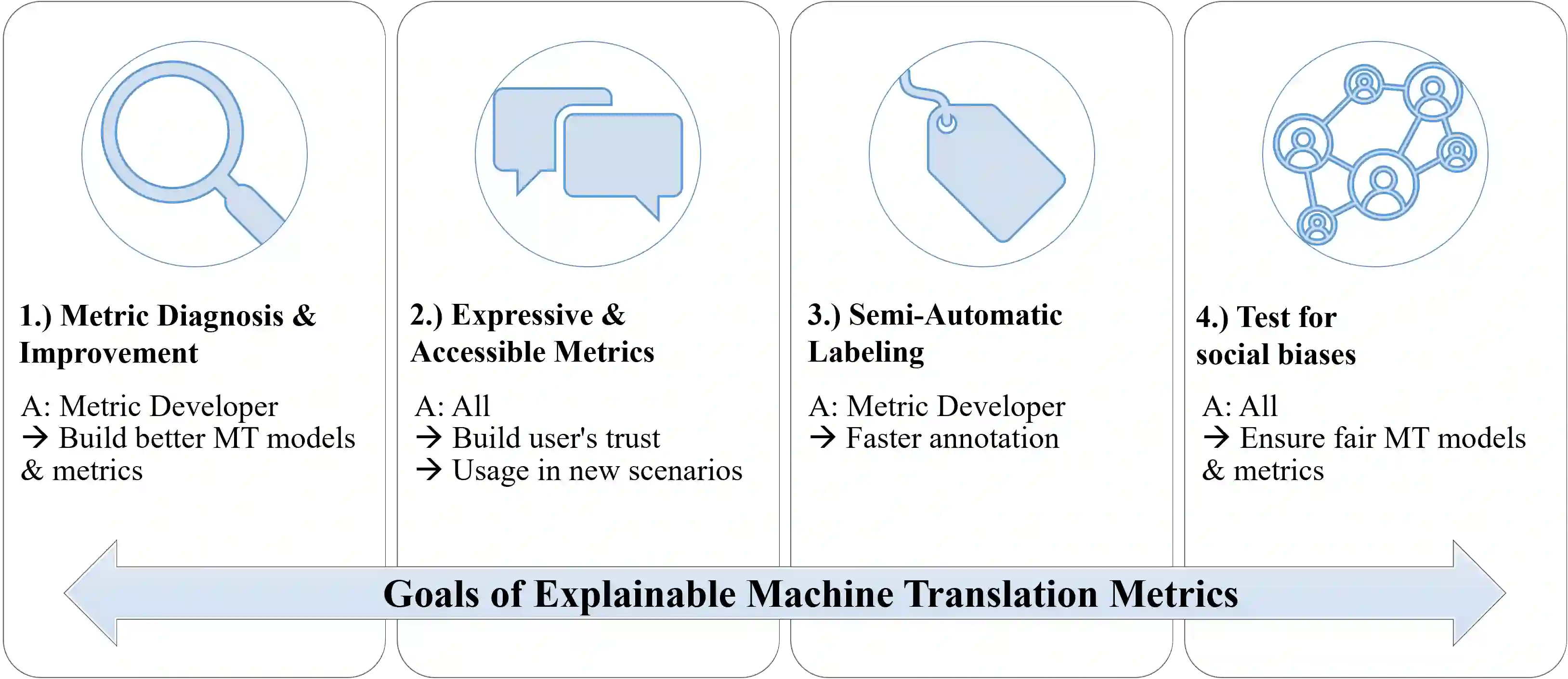
Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics for machine translation (for example, COMET or BERTScore) are based on black-box large language models. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are more transparent. To foster more widespread acceptance of novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties as well as key goals of explainable machine translation metrics and provide a comprehensive synthesis of recent techniques, relating them to our established goals and properties. In this context, we also discuss the latest state-of-the-art approaches to explainable metrics based on generative models such as ChatGPT and GPT4. Finally, we contribute a vision of next-generation approaches, including natural language explanations. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent machine translation systems.
翻译:与BLEU等传统词汇重叠指标不同,当前大多数机器翻译评估指标(例如COMET或BERTScore)均基于黑盒大语言模型。这些指标往往与人工判断高度相关,但近期研究表明,质量较低的传统指标仍占据主导地位,潜在原因之一在于其决策过程更为透明。因此,为促进新型高质量指标获得更广泛认可,可解释性变得至关重要。本文作为概念性论文,首先明确了可解释机器翻译指标的关键属性与核心目标,并对现有相关技术进行了系统性整合,将其与既定目标及属性建立关联。在此基础上,我们进一步探讨了基于生成式模型(如ChatGPT和GPT4)的最新可解释指标前沿方法。最后,我们提出了下一代技术路径的愿景,包括自然语言解释。期望本研究能够推动并引导可解释评估指标的未来研究,间接助力构建更优质、更透明的机器翻译系统。