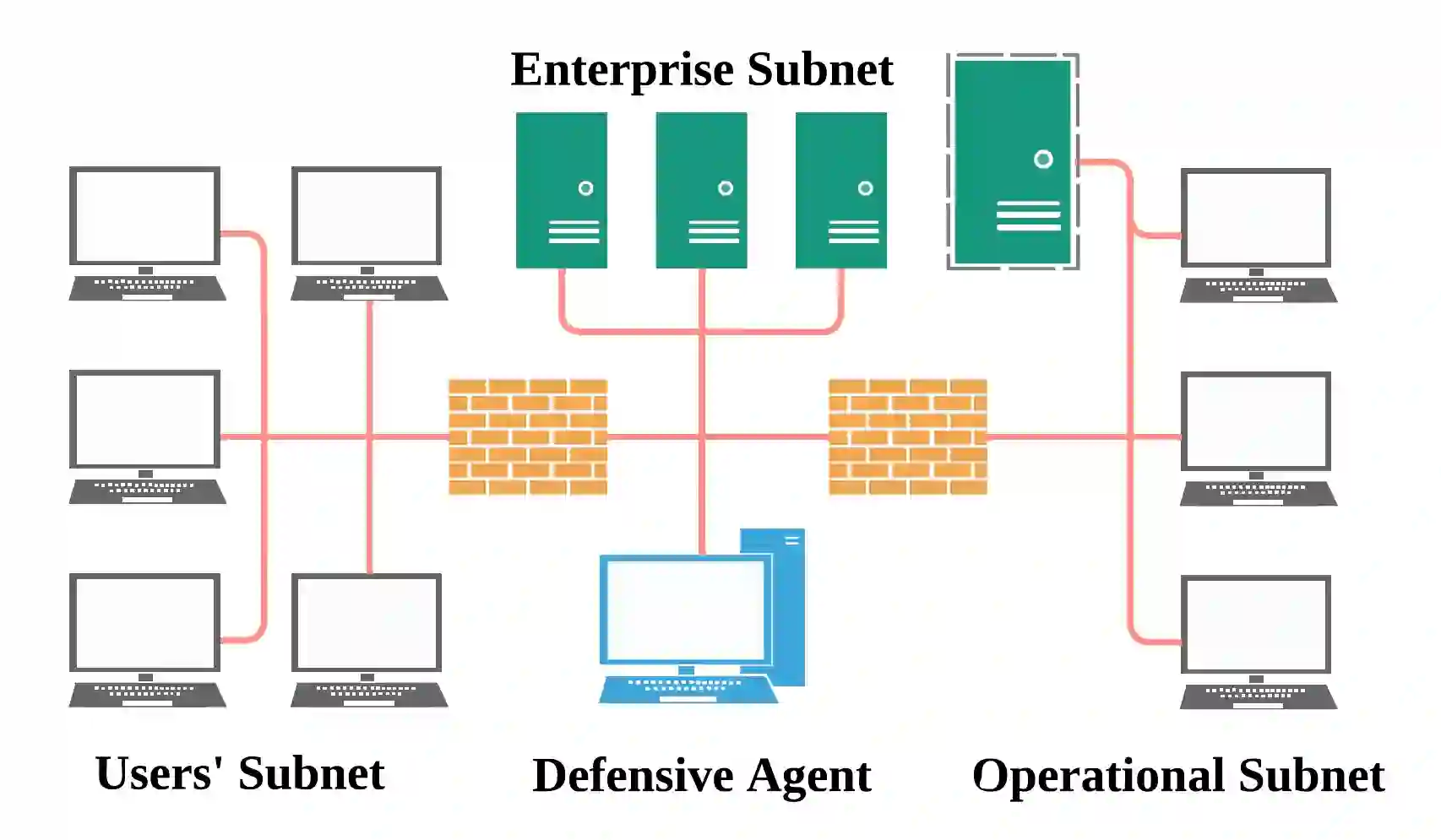
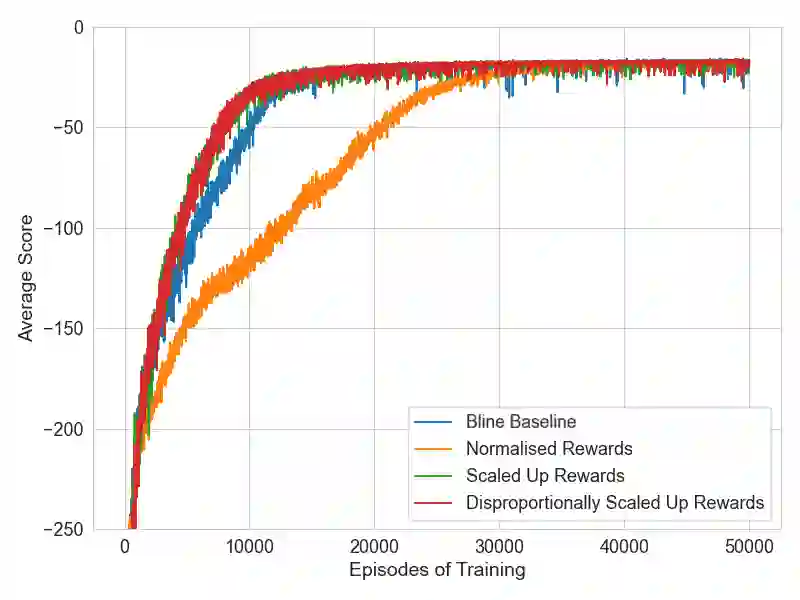
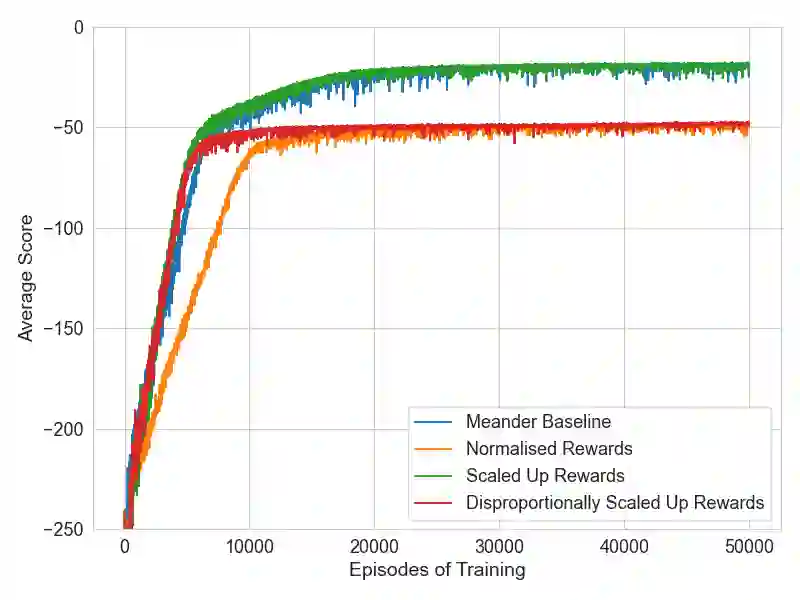
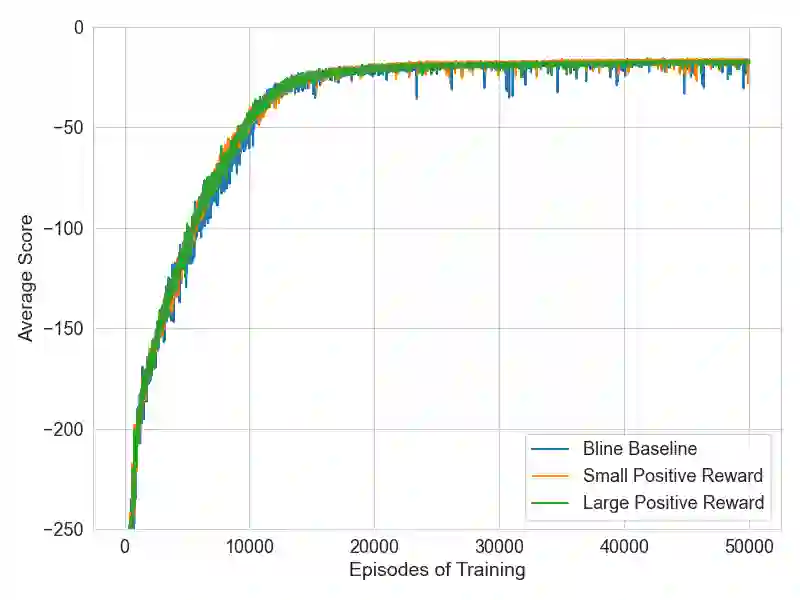
As machine learning models become more capable, they have exhibited increased potential in solving complex tasks. One of the most promising directions uses deep reinforcement learning to train autonomous agents in computer network defense tasks. This work studies the impact of the reward signal that is provided to the agents when training for this task. Due to the nature of cybersecurity tasks, the reward signal is typically 1) in the form of penalties (e.g., when a compromise occurs), and 2) distributed sparsely across each defense episode. Such reward characteristics are atypical of classic reinforcement learning tasks where the agent is regularly rewarded for progress (cf. to getting occasionally penalized for failures). We investigate reward shaping techniques that could bridge this gap so as to enable agents to train more sample-efficiently and potentially converge to a better performance. We first show that deep reinforcement learning algorithms are sensitive to the magnitude of the penalties and their relative size. Then, we combine penalties with positive external rewards and study their effect compared to penalty-only training. Finally, we evaluate intrinsic curiosity as an internal positive reward mechanism and discuss why it might not be as advantageous for high-level network monitoring tasks.
翻译:随着机器学习模型能力的提升,其在解决复杂任务方面展现出日益增长的潜力。其中最具前景的研究方向之一是利用深度强化学习,在计算机网络防御任务中训练自主智能体。本研究探讨了在此类任务训练中,提供给智能体的奖励信号所产生的影响。由于网络安全任务的性质,其奖励信号通常具有以下特点:1)以惩罚形式呈现(例如,当发生入侵时);2)在每个防御回合中分布稀疏。这种奖励特征与经典强化学习任务不同——在经典任务中,智能体会因取得进展而定期获得奖励(而非偶尔因失败受到惩罚)。我们研究了能够弥合这一差距的奖励塑形技术,从而使智能体能够更高效地利用样本进行训练,并可能收敛到更优的性能。我们首先证明深度强化学习算法对惩罚幅度及其相对大小具有敏感性。随后,我们将惩罚与外部正向奖励相结合,研究其相较于纯惩罚训练的效果。最后,我们评估了内在好奇心作为内部正向奖励机制的作用,并探讨为何该机制在高级网络监控任务中可能不具备显著优势。