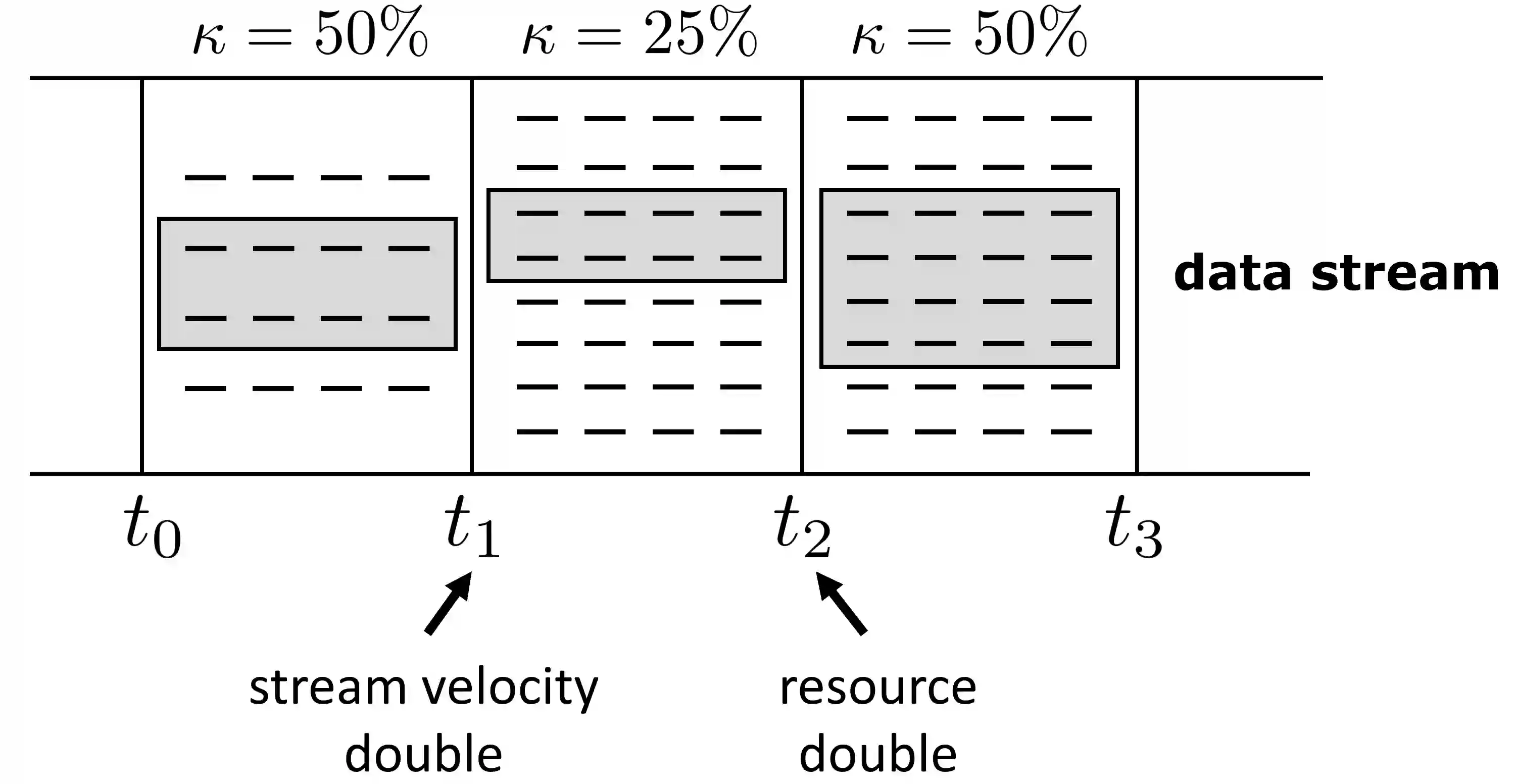
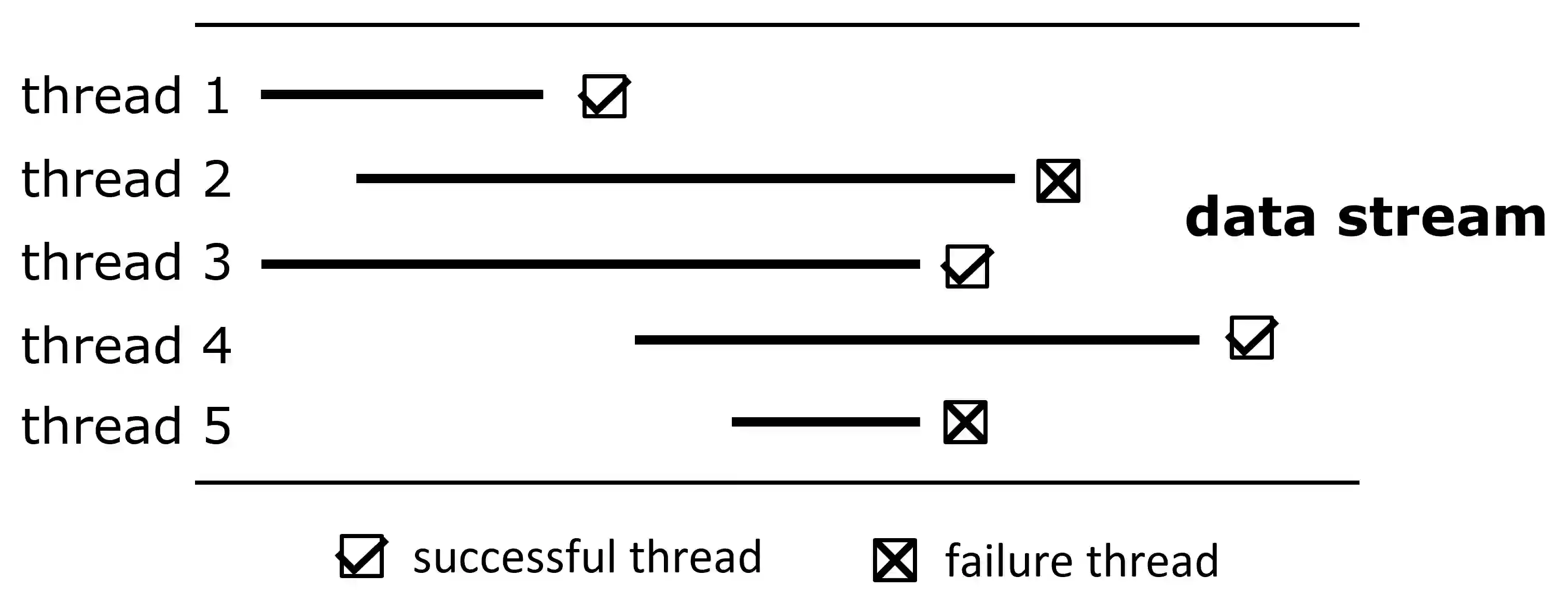
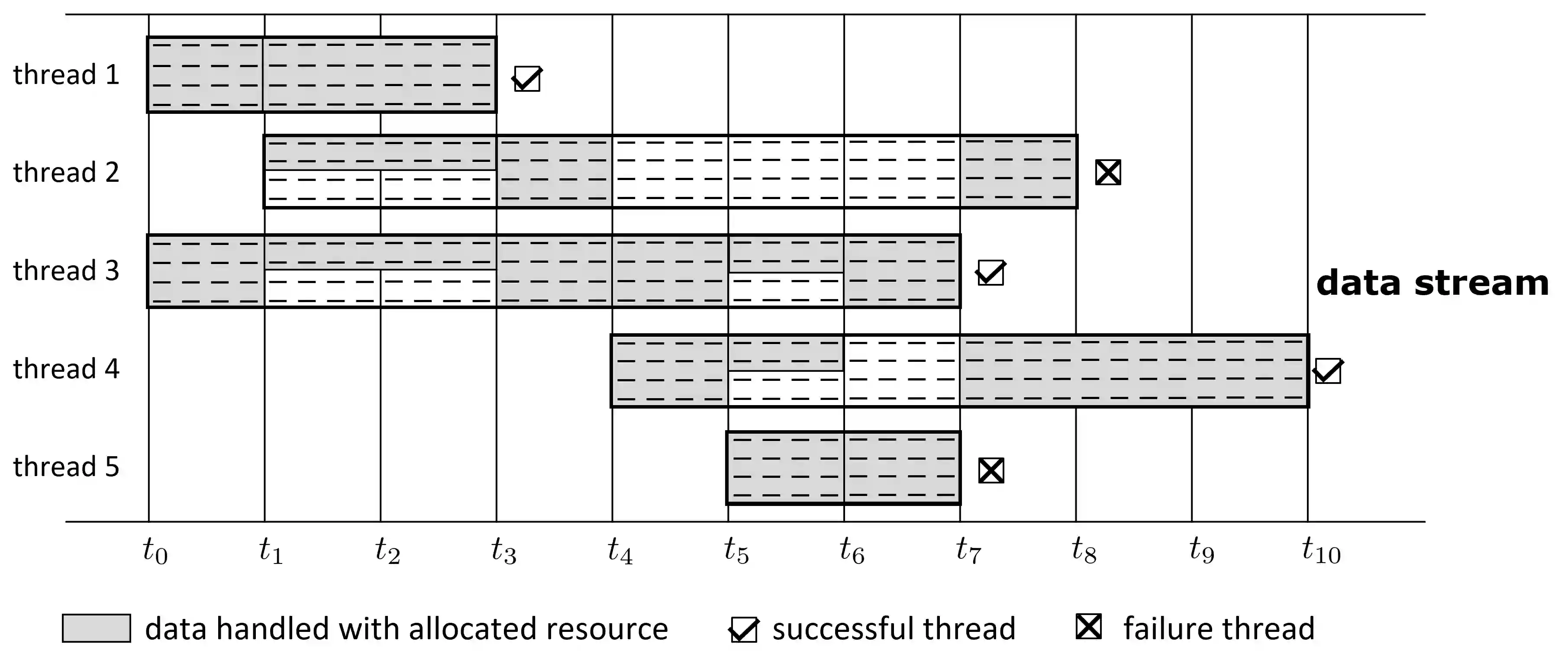
Data in many real-world applications are often accumulated over time, like a stream. In contrast to conventional machine learning studies that focus on learning from a given training data set, learning from data streams cannot ignore the fact that the incoming data stream can be potentially endless with overwhelming size and unknown changes, and it is impractical to assume to have sufficient computational/storage resource such that all received data can be handled in time. Thus, the generalization performance of learning from data streams depends not only on how many data have been received, but also on how many data can be well exploited timely, with resource and rapidity concerns, in addition to the ability of learning algorithm and complexity of the problem. For this purpose, in this article we introduce the notion of machine learning throughput, define Stream Efficient Learning and present a preliminary theoretical framework.
翻译:在许多实际应用中,数据往往随时间累积,如同数据流一般。与专注于从给定训练数据集中学习的传统机器学习研究不同,从数据流中学习无法忽视这样一个事实:传入的数据流可能无穷无尽、规模庞大且存在未知变化,并且假设拥有足够的计算/存储资源以便及时处理所有接收到的数据是不切实际的。因此,从数据流中学习的泛化性能不仅取决于已接收数据的数量,还取决于考虑到资源和速度限制的前提下,能够及时有效利用的数据量,此外还受学习算法的能力以及问题复杂性的影响。为此,本文引入了机器学习吞吐量的概念,定义了流高效学习,并提出了一个初步的理论框架。