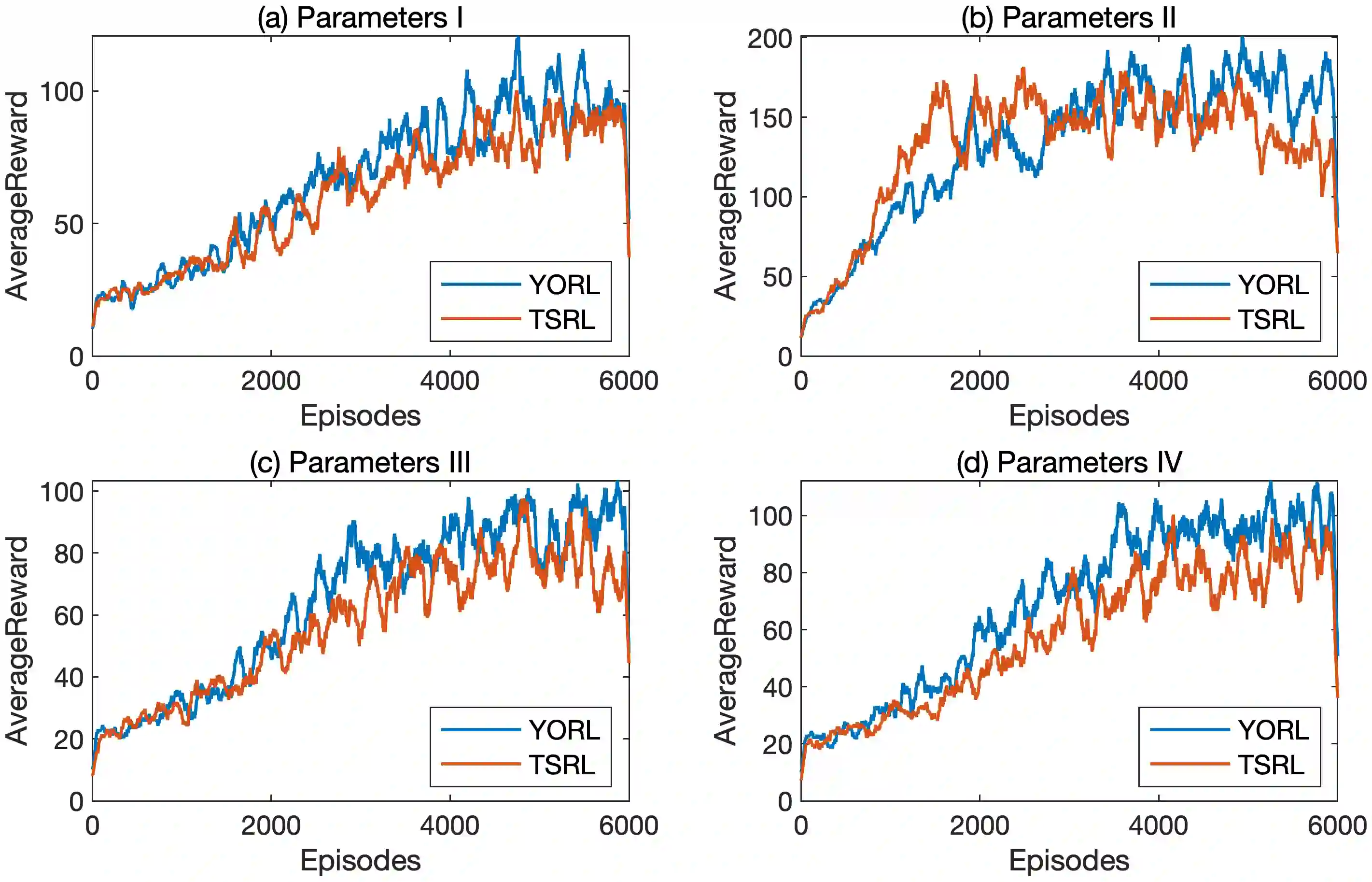
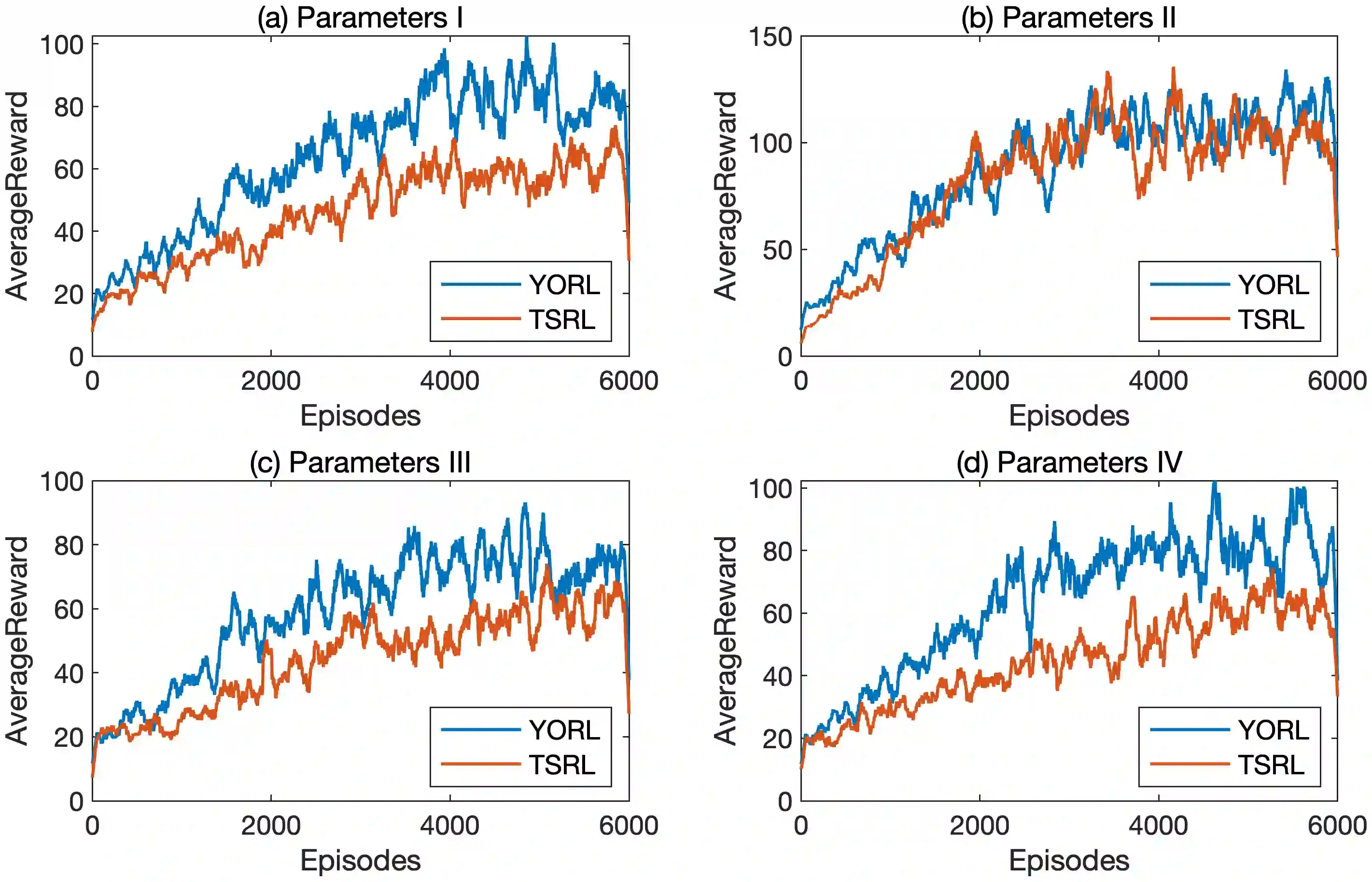
This paper introduces a novel operator, termed the Y operator, to elevate control performance in Actor-Critic(AC) based reinforcement learning for systems governed by stochastic differential equations(SDEs). The Y operator ingeniously integrates the stochasticity of a class of child-mother system into the Critic network's loss function, yielding substantial advancements in the control performance of RL algorithms.Additionally, the Y operator elegantly reformulates the challenge of solving partial differential equations for the state-value function into a parallel problem for the drift and diffusion functions within the system's SDEs.A rigorous mathematical proof confirms the operator's validity.This transformation enables the Y Operator-based Reinforcement Learning(YORL) framework to efficiently tackle optimal control problems in both model-based and data-driven systems.The superiority of YORL is demonstrated through linear and nonlinear numerical examples showing its enhanced performance over existing methods post convergence.
翻译:本文提出一种新颖的Y算子,用于提升受随机微分方程驱动的系统中基于Actor-Critic(AC)强化学习的控制性能。该算子巧妙地将一类母子系统的随机性融入Critic网络的损失函数中,显著提升了强化学习算法的控制性能。此外,Y算子将状态值函数的偏微分方程求解问题优雅地转化为系统随机微分方程中漂移函数与扩散函数的并行求解问题,并通过严格的数学证明验证了其有效性。这一变换使基于Y算子的强化学习框架能够高效处理基于模型和数据驱动系统的最优控制问题。线性与非线性数值算例表明,YORL框架在收敛后展现出优于现有方法的控制性能。