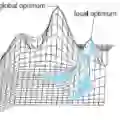
Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.
翻译:开发者越来越多地依赖将预训练模型适配到自定义任务,而非从零构建深度学习模型。然而,强大的预训练模型可能被滥用于不道德或非法的任务,例如隐私推断与不安全内容生成。本文提出一种开创性的学习范式——不可微调学习,该范式既能阻止预训练模型被微调至不当任务,又能保持其在原任务上的性能。为实现这一目标,我们提出保护框架SOPHON,该框架使给定预训练模型对预定义受限域内的微调操作具备抵抗力。然而,由于对手可能采用多种复杂的微调策略,实现此目标极具挑战性。受模型无关元学习启发,我们通过设计精密的微调模拟算法与微调评估算法来克服这一难题。此外,我们精心设计了优化过程,使预训练模型在受限域上陷入难以逃逸的局部最优。我们在两种深度学习模式(分类与生成)、七个受限域及六种模型架构上开展了广泛实验,验证了SOPHON的有效性。实验结果表明,对SOPHON保护的模型进行微调产生的开销可比肩甚至超过从零训练。此外,我们确认了SOPHON对三种微调方法、五种优化器、不同学习率与批大小均具有鲁棒性。SOPHON有望推动安全与负责任人工智能的进一步研究。