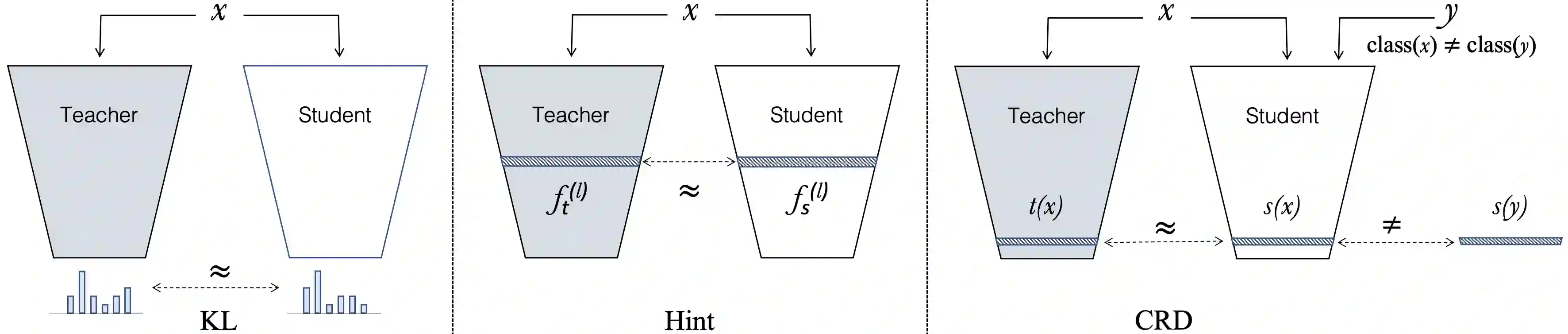
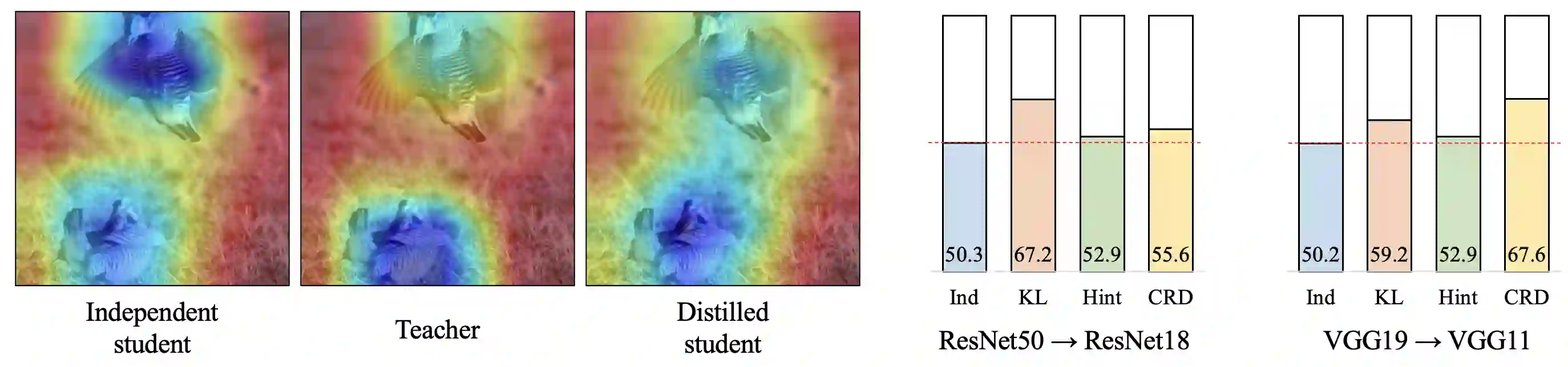
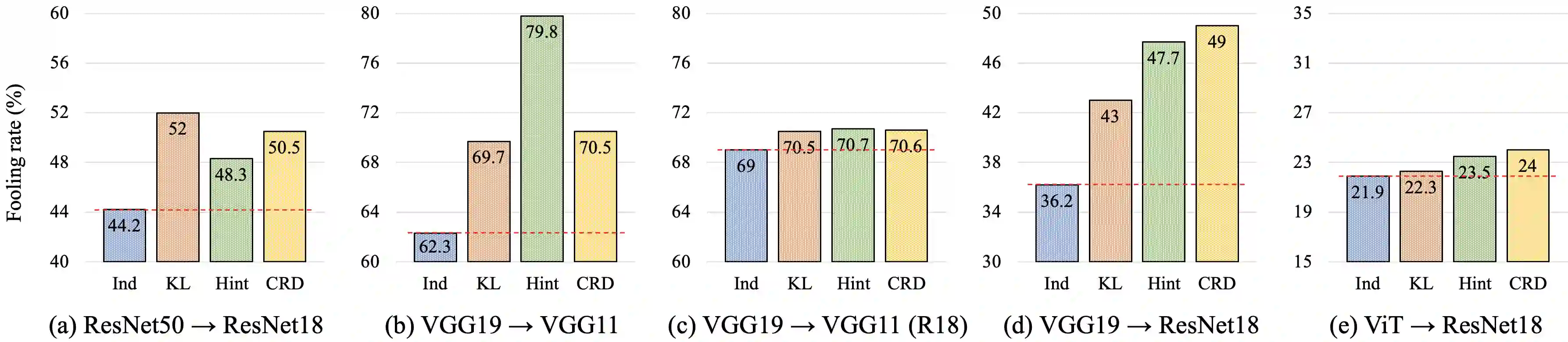
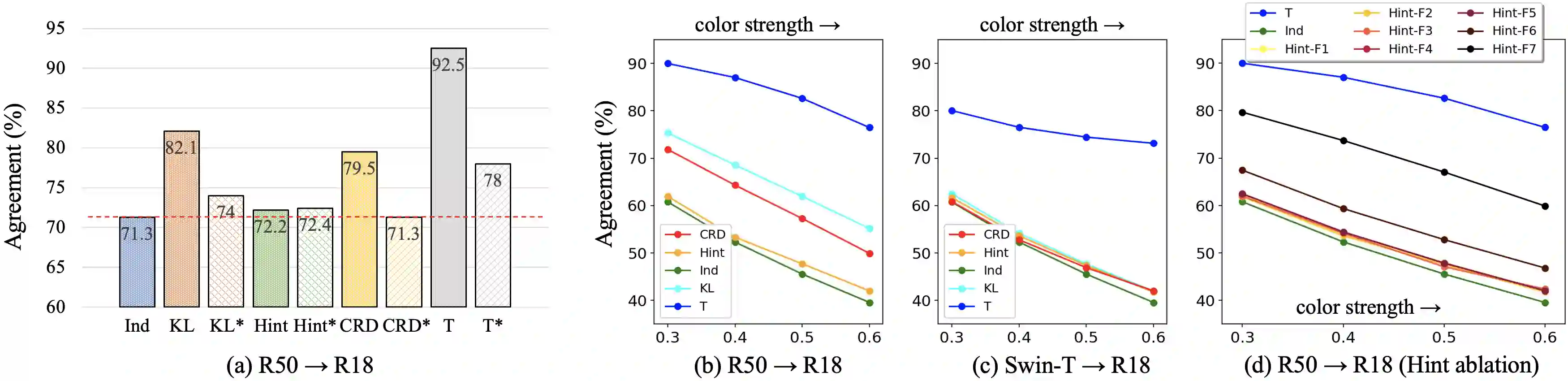
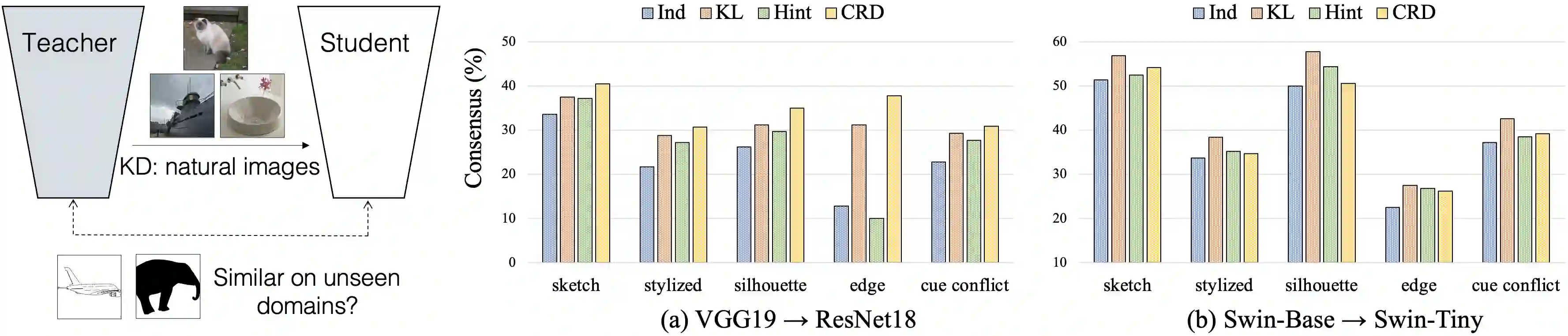
Knowledge distillation aims to transfer useful information from a teacher network to a student network, with the primary goal of improving the student's performance for the task at hand. Over the years, there has a been a deluge of novel techniques and use cases of knowledge distillation. Yet, despite the various improvements, there seems to be a glaring gap in the community's fundamental understanding of the process. Specifically, what is the knowledge that gets distilled in knowledge distillation? In other words, in what ways does the student become similar to the teacher? Does it start to localize objects in the same way? Does it get fooled by the same adversarial samples? Does its data invariance properties become similar? Our work presents a comprehensive study to try to answer these questions. We show that existing methods can indeed indirectly distill these properties beyond improving task performance. We further study why knowledge distillation might work this way, and show that our findings have practical implications as well.
翻译:知识蒸馏旨在将教师网络中的有用信息迁移至学生网络,其主要目标是提升学生网络在目标任务上的性能。多年来,关于知识蒸馏的新型技术和应用案例层出不穷。然而,尽管取得了诸多改进,学术界对该过程的根本理解似乎仍存在显著空白——具体而言,知识蒸馏所蒸馏的"知识"究竟是什么?换言之,学生网络在哪些方面变得与教师网络相似?它是否会以相同方式定位目标?是否会被相同的对抗样本所迷惑?其数据不变性特征是否趋于一致?本研究通过系统性实验尝试解答上述问题。我们证明,现有方法在提升任务性能之外,确实能间接蒸馏这些特征。进一步地,我们探讨了知识蒸馏可能产生这种效应的深层原因,并表明我们的发现具有重要的实践意义。