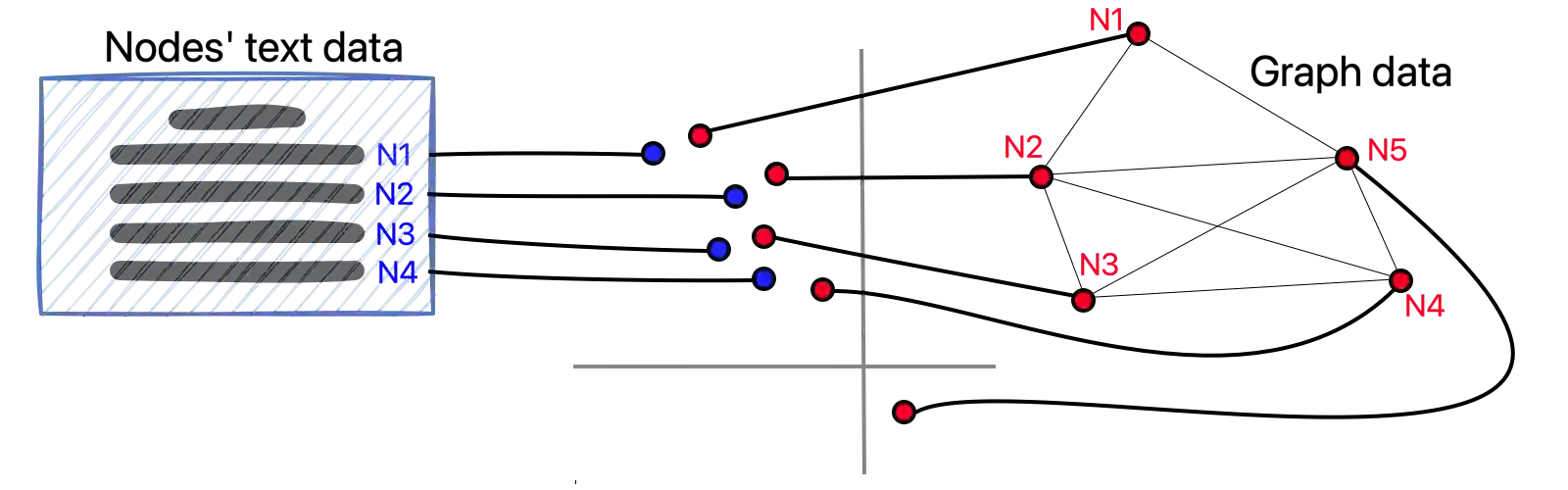
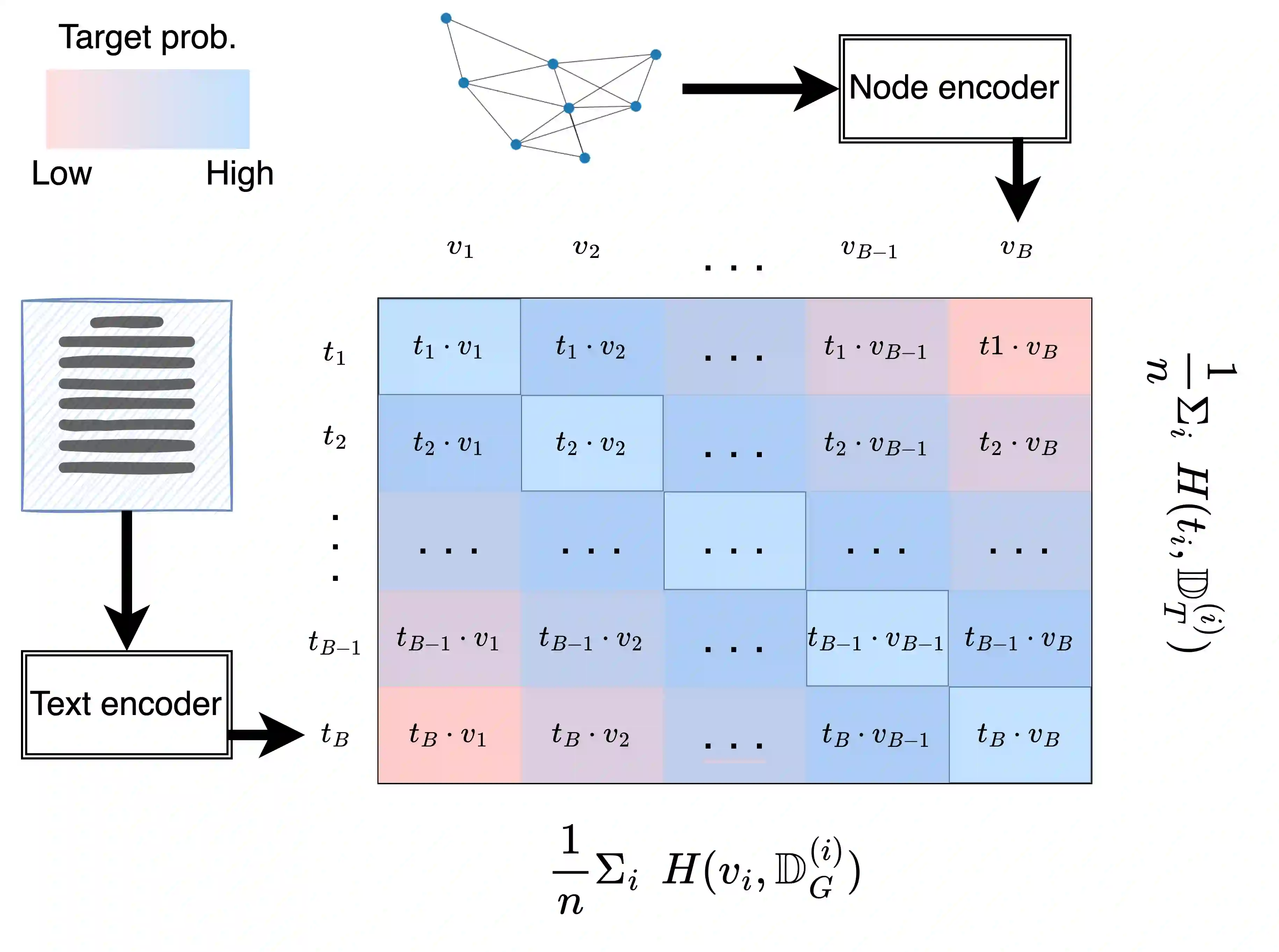
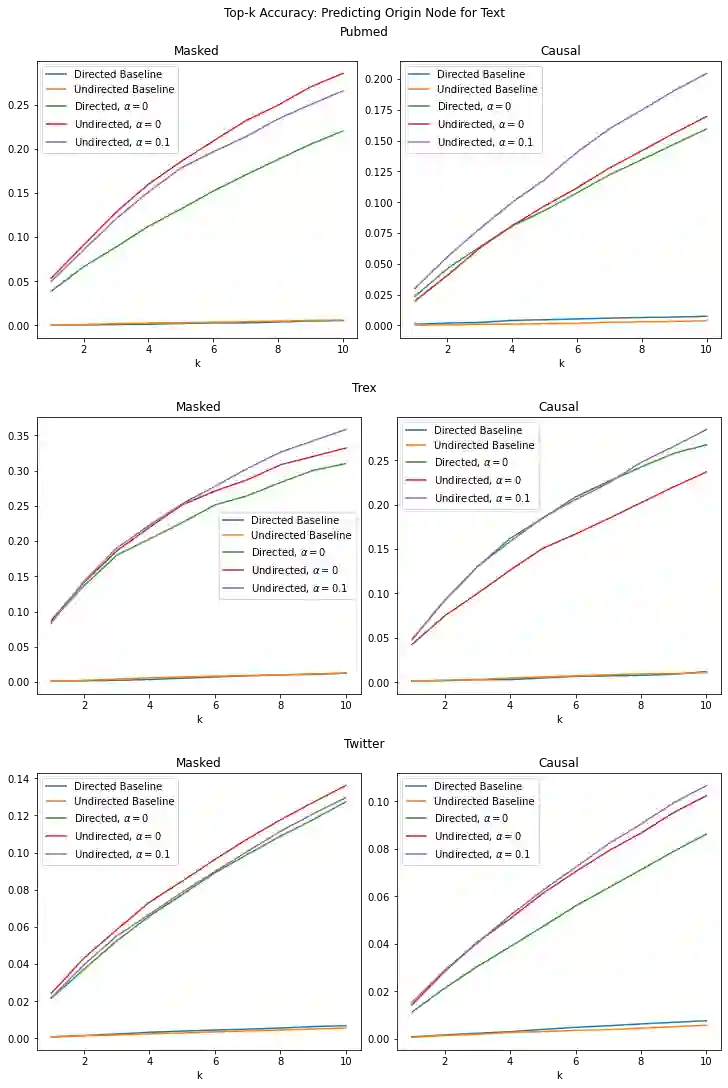
We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
翻译:我们提出ConGraT(对比图-文本预训练),一种通用的自监督方法,用于在父图(或称“上位图”)中联合学习文本与节点的独立表示,其中每个文本与图中某一节点相关联。符合该范式数据集广泛存在,包括社交媒体(用户与帖子)、论文引文网络以及网页链接图。我们扩展了先前工作,提出一种不依赖特定数据集结构或具体任务的通用自监督联合预训练方法。该方法采用两个独立编码器分别处理图节点与文本,通过训练将二者的表示对齐到共同潜空间中。训练过程基于批次化对比学习目标,该目标受先前图文联合编码研究的启发。由于图比图像更具结构化特征,我们进一步扩展了训练目标,在节点与文本匹配过程中融入节点相似性信息及合理的候选预测机制。多数据集实验表明,ConGraT在节点分类、文本分类及链接预测等下游任务中显著优于强基线方法。代码及部分数据集已开源至https://github.com/wwbrannon/congrat。