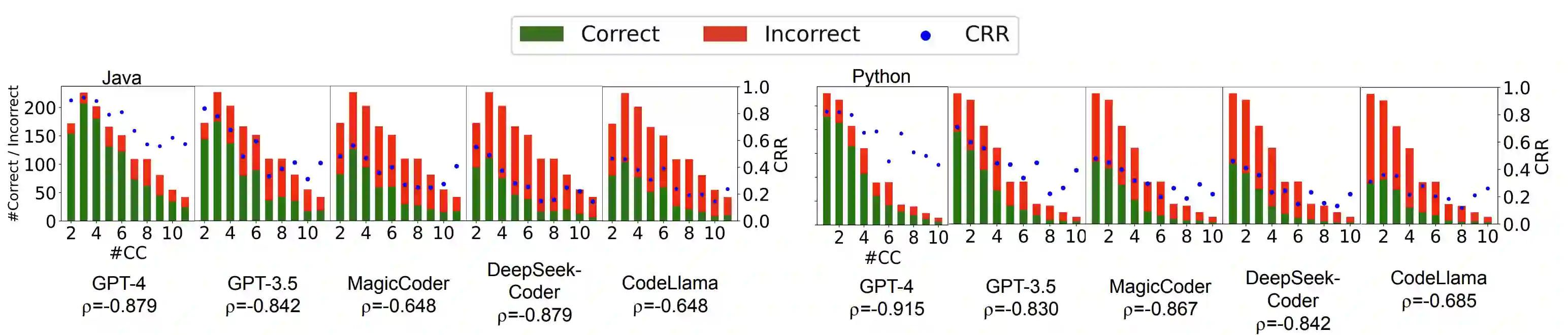
Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
翻译:单纯依赖测试通过率来评估大语言模型(LLM)的代码合成能力,可能导致不公平的评价或助长存在数据泄露的模型。为此,我们提出CodeMind——一个旨在衡量LLM代码推理能力的框架。CodeMind当前支持三种代码推理任务:独立执行推理(IER)、依赖执行推理(DER)和规约推理(SR)。前两项任务评估模型预测任意代码或模型能正确合成的代码的执行输出的能力;第三项任务评估LLM实现指定预期行为的程度。我们使用CodeMind对九个LLM在五种基准测试及两种编程语言中进行了广泛评估,结果表明:LLM能较好遵循控制流结构,并能大致解释输入如何演变为输出,尤其对简单程序及其能正确合成的程序。然而,当代码复杂度较高、涉及非平凡逻辑与算术运算符、非原始类型及API调用时,其性能会显著下降。此外,我们观察到,虽然规约推理(对代码合成至关重要)与执行推理(对测试、调试等更广泛的编程任务至关重要)存在相关性,但前者并不必然意味着后者:基于测试通过率的LLM排名可能与基于代码推理能力的排名存在差异。