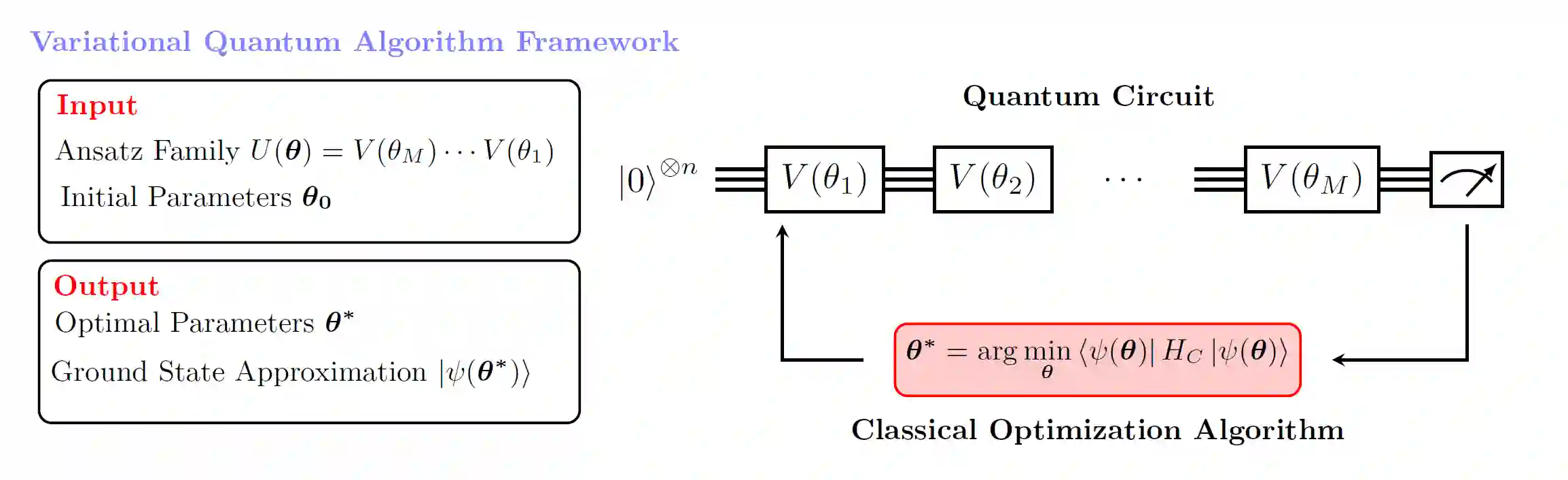
Current quantum hardware prohibits any direct use of large classical datasets. Coresets allow for a succinct description of these large datasets and their solution in a computational task is competitive with the solution on the original dataset. The method of combining coresets with small quantum computers to solve a given task that requires a large number of data points was first introduced by Harrow [arXiv:2004.00026]. In this paper, we apply the coreset method in three different well-studied classical machine learning problems, namely Divisive Clustering, 3-means Clustering, and Gaussian Mixture Model Clustering. We provide a Hamiltonian formulation of the aforementioned problems for which the number of qubits scales linearly with the size of the coreset. Then, we evaluate how the variational quantum eigensolver (VQE) performs on these problems and demonstrate the practical efficiency of coresets when used along with a small quantum computer. We perform noiseless simulations on instances of sizes up to 25 qubits on CUDA Quantum and show that our approach provides comparable performance to classical solvers.
翻译:当前量子硬件无法直接处理大规模经典数据集。核心集(Coresets)能够简洁描述这些大型数据集,且在计算任务中其解与原始数据集上的解具有竞争力。将核心集与小规模量子计算机结合以解决需要大量数据点的给定任务的方法,最初由Harrow提出[arXiv:2004.00026]。本文在三类经典机器学习问题——分裂层次聚类、3均值聚类和高斯混合模型聚类中应用了核心集方法。我们为上述问题提供了哈密顿量表述,其中量子比特数随核心集规模线性增长。随后评估变分量子本征求解器(VQE)在这些问题上的表现,并证明核心集在与小型量子计算机协同使用时具有实际效率。我们在CUDA Quantum平台上对多达25量子比特的实例进行无噪声仿真,结果表明我们的方法能够达到与经典求解器相当的性能。