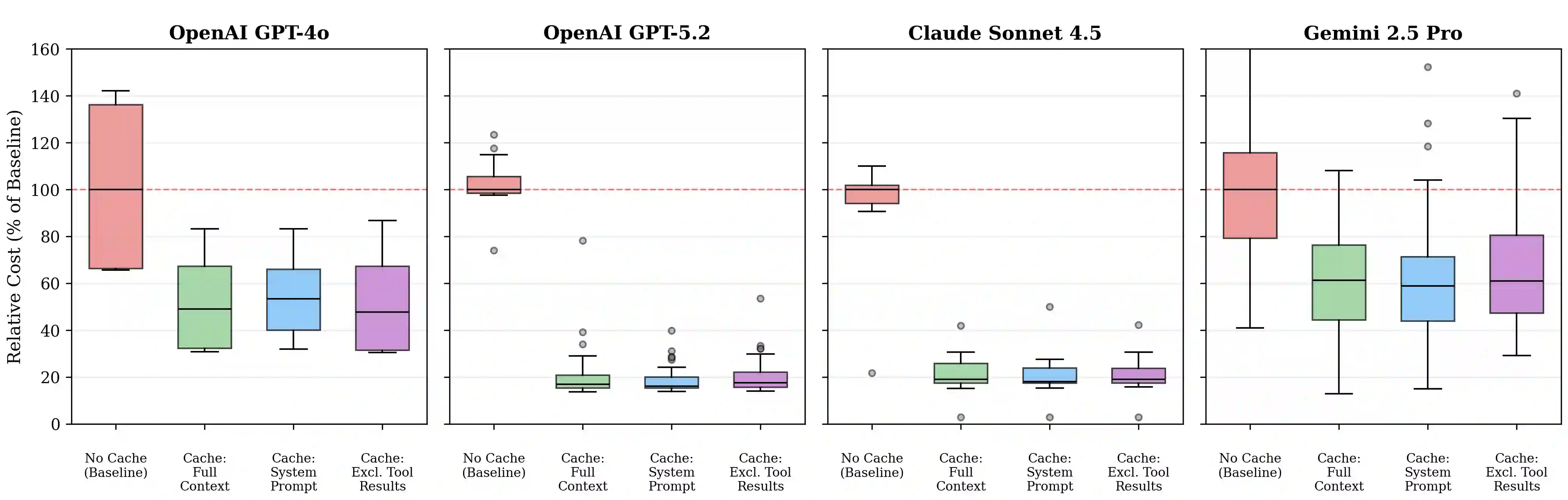
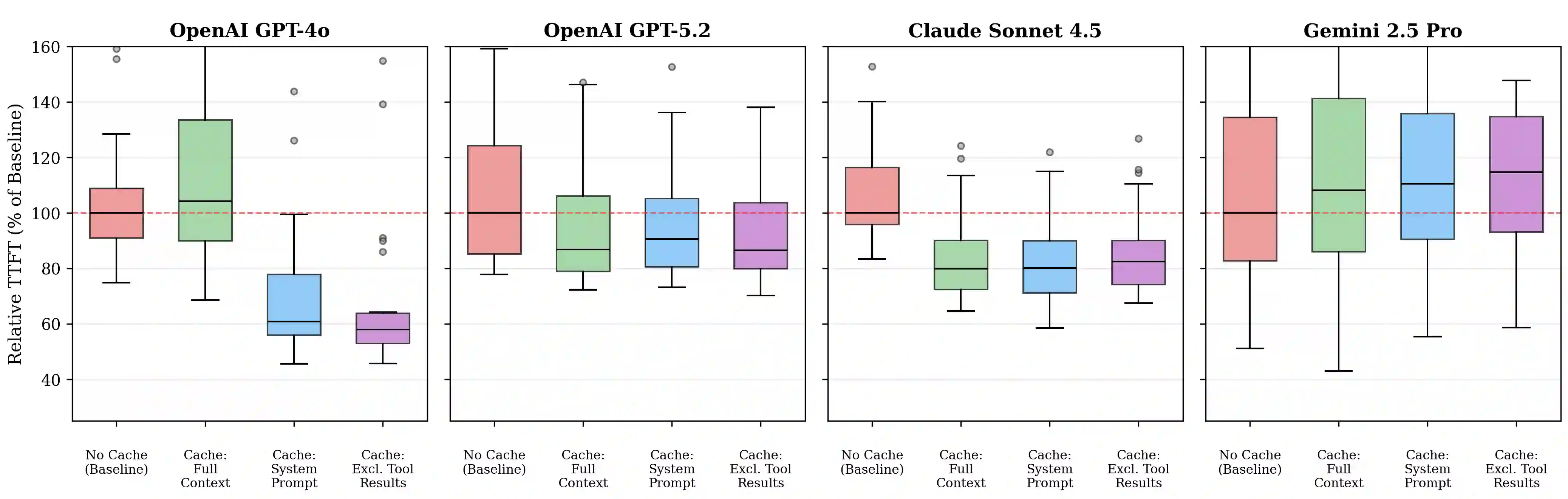
Recent advancements in Large Language Model (LLM) agents have enabled complex multi-turn agentic tasks requiring extensive tool calling, where conversations can span dozens of API calls with increasingly large context windows. However, although major LLM providers offer prompt caching to reduce cost and latency, its benefits for agentic workloads remain underexplored in the research literature. To our knowledge, no prior work quantifies these cost savings or compares caching strategies for multi-turn agentic tasks. We present a comprehensive evaluation of prompt caching across three major LLM providers (OpenAI, Anthropic, and Google) and compare three caching strategies, including full context caching, system prompt only caching, and caching that excludes dynamic tool results. We evaluate on DeepResearchBench, a multi-turn agentic benchmark where agents autonomously execute real-world web search tool calls to answer complex research questions, measuring both API cost and time to first token (TTFT) across over 500 agent sessions with 10,000-token system prompts. Our results demonstrate that prompt caching reduces API costs by 45-80% and improves time to first token by 13-31% across providers. We find that strategic prompt cache block control, such as placing dynamic content at the end of the system prompt, avoiding dynamic traditional function calling, and excluding dynamic tool results, provides more consistent benefits than naive full-context caching, which can paradoxically increase latency. Our analysis reveals nuanced variations in caching behavior across providers, and we provide practical guidance for implementing prompt caching in production agentic systems.
翻译:近年来,大型语言模型(LLM)智能体的进展使得需要大量工具调用的复杂多轮智能体任务成为可能,这类对话可能跨越数十次API调用,且上下文窗口日益增大。然而,尽管主流LLM提供商提供了提示缓存功能以降低成本和延迟,但其在智能体工作负载中的效益在研究文献中仍未得到充分探索。据我们所知,尚无先前工作量化此类成本节约效果,亦未针对多轮智能体任务比较不同缓存策略。本研究对三大主流LLM提供商(OpenAI、Anthropic和Google)的提示缓存进行了全面评估,并比较了三种缓存策略,包括完整上下文缓存、仅系统提示缓存以及排除动态工具结果的缓存。我们在DeepResearchBench基准上开展评估——这是一个多轮智能体基准测试平台,智能体通过自主执行真实网络搜索工具调用来回答复杂研究问题。我们在超过500次智能体会话中(使用10,000词元的系统提示)测量了API成本和首词元生成时间(TTFT)。实验结果表明:提示缓存可使API成本降低45-80%,并将首词元生成时间提升13-31%(不同提供商间存在差异)。研究发现,采用策略性的提示缓存块控制(例如将动态内容置于系统提示末尾、避免动态传统函数调用、排除动态工具结果)相比简单的完整上下文缓存能带来更稳定的效益,而后者反而可能增加延迟。我们的分析揭示了不同提供商间缓存行为的细微差异,并为在生产级智能体系统中实施提示缓存提供了实用指导。