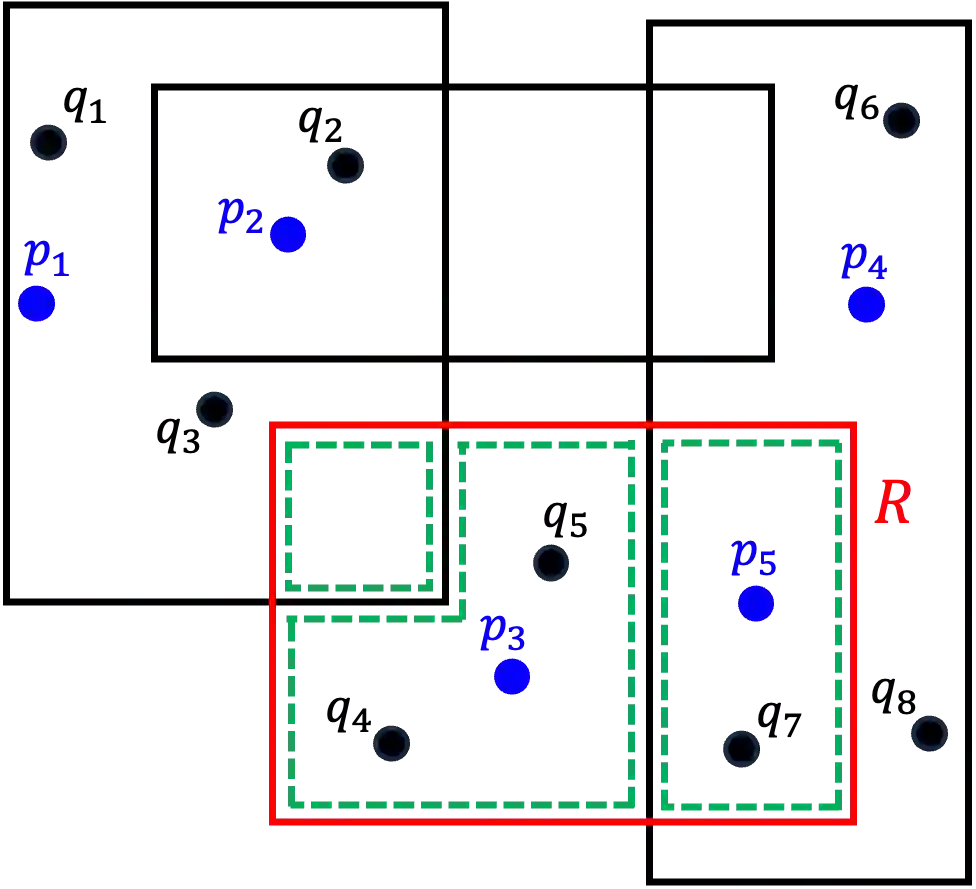
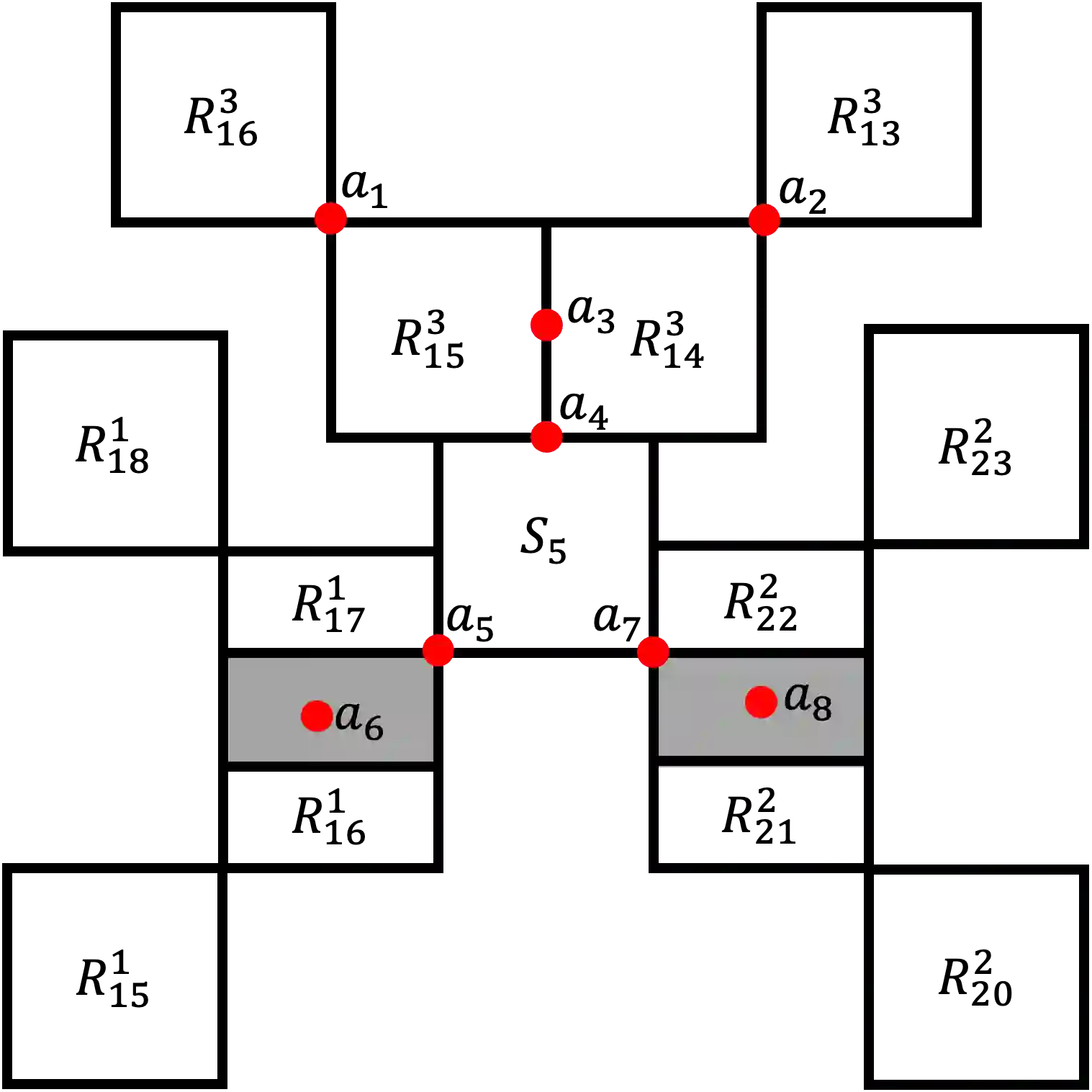
We are given a set $\mathcal{Z}=\{(R_1,s_1),\ldots, (R_n,s_n)\}$, where each $R_i$ is a \emph{range} in $\Re^d$, such as rectangle or ball, and $s_i \in [0,1]$ denotes its \emph{selectivity}. The goal is to compute a small-size \emph{discrete data distribution} $\mathcal{D}=\{(q_1,w_1),\ldots, (q_m,w_m)\}$, where $q_j\in \Re^d$ and $w_j\in [0,1]$ for each $1\leq j\leq m$, and $\sum_{1\leq j\leq m}w_j= 1$, such that $\mathcal{D}$ is the most \emph{consistent} with $\mathcal{Z}$, i.e., $\mathrm{err}_p(\mathcal{D},\mathcal{Z})=\frac{1}{n}\sum_{i=1}^n\! \lvert{s_i-\sum_{j=1}^m w_j\cdot 1(q_j\in R_i)}\rvert^p$ is minimized. In a database setting, $\mathcal{Z}$ corresponds to a workload of range queries over some table, together with their observed selectivities (i.e., fraction of tuples returned), and $\mathcal{D}$ can be used as compact model for approximating the data distribution within the table without accessing the underlying contents. In this paper, we obtain both upper and lower bounds for this problem. In particular, we show that the problem of finding the best data distribution from selectivity queries is $\mathsf{NP}$-complete. On the positive side, we describe a Monte Carlo algorithm that constructs, in time $O((n+\delta^{-d})\delta^{-2}\mathop{\mathrm{polylog}})$, a discrete distribution $\tilde{\mathcal{D}}$ of size $O(\delta^{-2})$, such that $\mathrm{err}_p(\tilde{\mathcal{D}},\mathcal{Z})\leq \min_{\mathcal{D}}\mathrm{err}_p(\mathcal{D},\mathcal{Z})+\delta$ (for $p=1,2,\infty$) where the minimum is taken over all discrete distributions. We also establish conditional lower bounds, which strongly indicate the infeasibility of relative approximations as well as removal of the exponential dependency on the dimension for additive approximations. This suggests that significant improvements to our algorithm are unlikely.
翻译:给定集合$\mathcal{Z}=\{(R_1,s_1),\ldots, (R_n,s_n)\}$,其中每个$R_i$是$\Re^d$空间中的\emph{范围}(如矩形或球体),$s_i \in [0,1]$表示其\emph{选择性}。目标是计算一个规模较小的\emph{离散数据分布}$\mathcal{D}=\{(q_1,w_1),\ldots, (q_m,w_m)\}$,其中$q_j\in \Re^d$,$w_j\in [0,1]$(对每个$1\leq j\leq m$),且$\sum_{1\leq j\leq m}w_j= 1$,使得$\mathcal{D}$与$\mathcal{Z}$\emph{一致性}最强,即最小化$\mathrm{err}_p(\mathcal{D},\mathcal{Z})=\frac{1}{n}\sum_{i=1}^n\! \lvert{s_i-\sum_{j=1}^m w_j\cdot 1(q_j\in R_i)}\rvert^p$。在数据库场景中,$\mathcal{Z}$对应某个表上的范围查询工作负载及其观测选择性(即返回元组比例),而$\mathcal{D}$可作为紧凑模型,在不访问底层数据内容的情况下近似表内数据分布。本文针对该问题给出了上界与下界。具体而言,我们证明从选择性查询中寻找最优数据分布问题是$\mathsf{NP}$完全的。从积极方面,我们提出一种蒙特卡洛算法,能在$O((n+\delta^{-d})\delta^{-2}\mathop{\mathrm{polylog}})$时间内构造出规模为$O(\delta^{-2})$的离散分布$\tilde{\mathcal{D}}$,使得对于$p=1,2,\infty$有$\mathrm{err}_p(\tilde{\mathcal{D}},\mathcal{Z})\leq \min_{\mathcal{D}}\mathrm{err}_p(\mathcal{D},\mathcal{Z})+\delta$(其中最小值取遍所有离散分布)。我们还建立了条件性下界,强有力地表明相对近似以及消除加性近似中维度指数依赖性的不可行性。这表明我们的算法很难有显著改进。