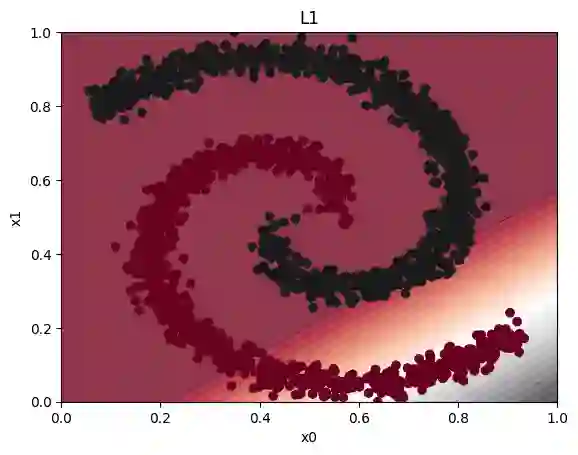
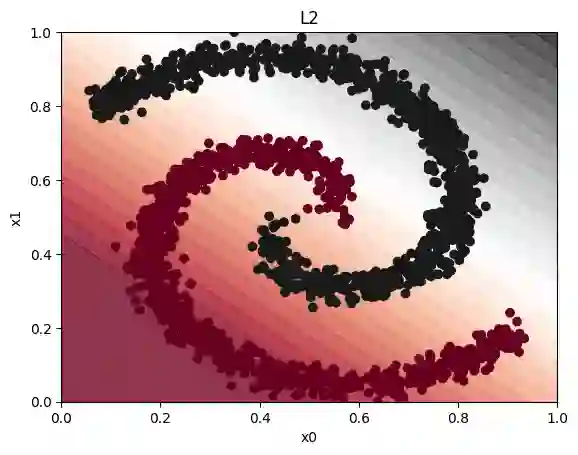
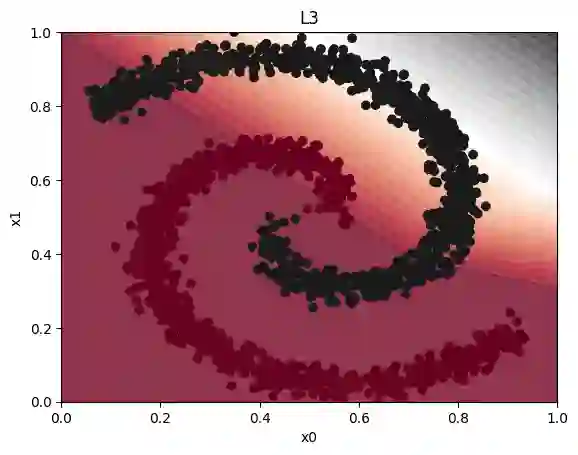
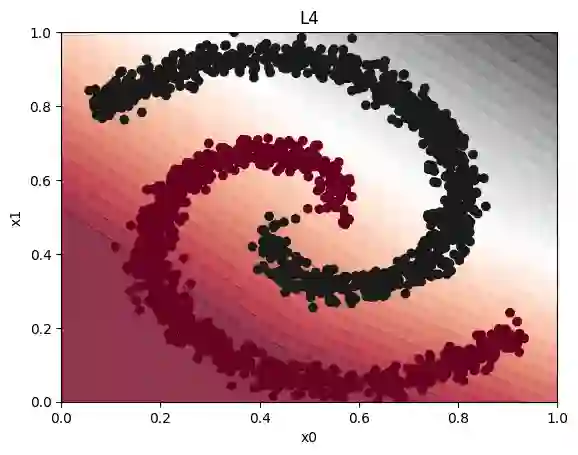
Field-programmable gate arrays (FPGAs) are widely used to implement deep learning inference. Standard deep neural network inference involves the computation of interleaved linear maps and nonlinear activation functions. Prior work for ultra-low latency implementations has hardcoded the combination of linear maps and nonlinear activations inside FPGA lookup tables (LUTs). Our work is motivated by the idea that the LUTs in an FPGA can be used to implement a much greater variety of functions than this. In this paper, we propose a novel approach to training neural networks for FPGA deployment using multivariate polynomials as the basic building block. Our method takes advantage of the flexibility offered by the soft logic, hiding the polynomial evaluation inside the LUTs with minimal overhead. We show that by using polynomial building blocks, we can achieve the same accuracy using considerably fewer layers of soft logic than by using linear functions, leading to significant latency and area improvements. We demonstrate the effectiveness of this approach in three tasks: network intrusion detection, jet identification at the CERN Large Hadron Collider, and handwritten digit recognition using the MNIST dataset.
翻译:现场可编程门阵列(FPGA)被广泛用于实现深度学习推理。标准深度神经网络推理涉及交错线性映射与非线性激活函数的计算。现有超低延迟实现方案将线性映射与非线性激活的组合硬编码至FPGA查找表(LUT)中。本文的动机源于:FPGA中的LUT可用于实现远比此更丰富的函数类型。我们提出一种面向FPGA部署的新型神经网络训练方法——以多元多项式为基本构建单元。该方法充分利用软逻辑的灵活性,将多项式求值隐藏于LUT中且开销极小。研究表明,与使用线性函数相比,采用多项式构建单元只需显著较少的软逻辑层数即可达到同等精度,从而大幅改善延迟与面积效率。我们通过三项任务验证该方法的有效性:网络入侵检测、CERN大型强子对撞机粒子喷注识别,以及基于MNIST数据集的手写数字识别。