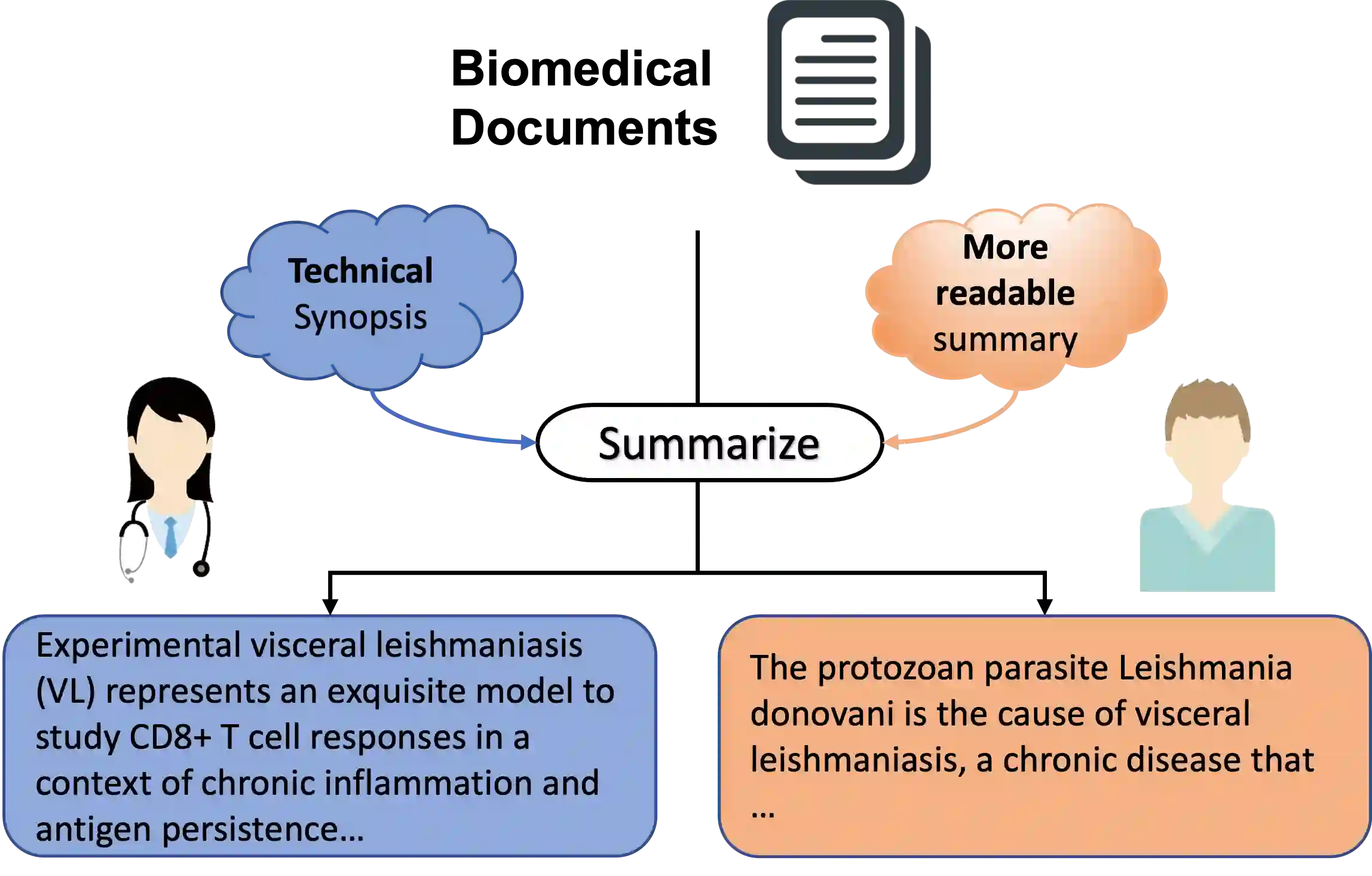
Different from general documents, it is recognised that the ease with which people can understand a biomedical text is eminently varied, owing to the highly technical nature of biomedical documents and the variance of readers' domain knowledge. However, existing biomedical document summarization systems have paid little attention to readability control, leaving users with summaries that are incompatible with their levels of expertise. In recognition of this urgent demand, we introduce a new task of readability controllable summarization for biomedical documents, which aims to recognise users' readability demands and generate summaries that better suit their needs: technical summaries for experts and plain language summaries (PLS) for laymen. To establish this task, we construct a corpus consisting of biomedical papers with technical summaries and PLSs written by the authors, and benchmark multiple advanced controllable abstractive and extractive summarization models based on pre-trained language models (PLMs) with prevalent controlling and generation techniques. Moreover, we propose a novel masked language model (MLM) based metric and its variant to effectively evaluate the readability discrepancy between lay and technical summaries. Experimental results from automated and human evaluations show that though current control techniques allow for a certain degree of readability adjustment during generation, the performance of existing controllable summarization methods is far from desirable in this task.
翻译:与普通文档不同,由于生物医学文档的高度技术性以及读者领域知识的差异,人们理解生物医学文本的难易程度存在显著差异。然而,现有的生物医学文档摘要系统很少关注可读性控制,导致生成的摘要与用户的专业水平不匹配。鉴于这一迫切需求,我们提出了一项新的任务——生物医学文档的可读性可控摘要。该任务旨在识别用户的可读性需求,并生成更符合其需求的摘要:为专家生成技术性摘要,为普通人生成通俗语言摘要。为建立该任务,我们构建了一个语料库,包含生物医学论文及其由作者撰写的技术摘要和通俗语言摘要,并基于预训练语言模型(PLMs)结合主流控制与生成技术,对多种先进的可控抽象式和抽取式摘要模型进行了基准测试。此外,我们提出了一种基于掩码语言模型(MLM)的度量指标及其变体,以有效评估通俗摘要与技术摘要之间的可读性差异。自动化和人工评估的实验结果表明,尽管当前的控制技术允许在生成过程中进行一定程度的可读性调整,但现有可控摘要方法在该任务上的表现远未达到理想水平。