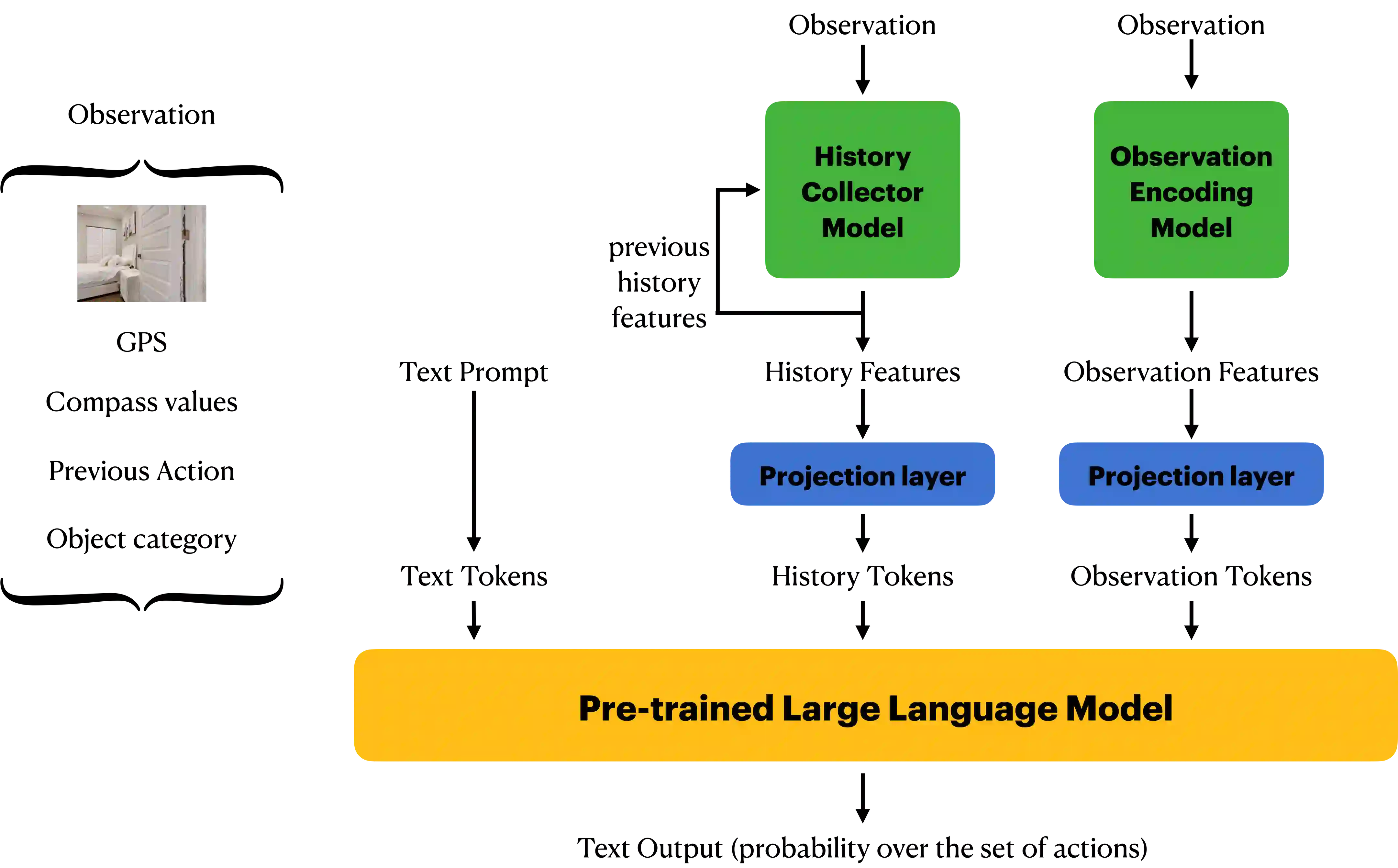
Recent efforts to enable visual navigation using large language models have mainly focused on developing complex prompt systems. These systems incorporate instructions, observations, and history into massive text prompts, which are then combined with pre-trained large language models to facilitate visual navigation. In contrast, our approach aims to fine-tune large language models for visual navigation without extensive prompt engineering. Our design involves a simple text prompt, current observations, and a history collector model that gathers information from previous observations as input. For output, our design provides a probability distribution of possible actions that the agent can take during navigation. We train our model using human demonstrations and collision signals from the Habitat-Matterport 3D Dataset (HM3D). Experimental results demonstrate that our method outperforms state-of-the-art behavior cloning methods and effectively reduces collision rates.
翻译:近期,利用大语言模型实现视觉导航的研究主要聚焦于开发复杂的提示系统。这些系统将指令、观测结果和历史信息整合到海量文本提示中,再结合预训练的大语言模型以辅助视觉导航。相比之下,我们的方法旨在直接微调大语言模型用于视觉导航,而无需复杂的提示工程。我们的设计采用简单的文本提示、当前观测结果以及一个历史收集器模型——该模型从先前的观测中提取信息作为输入。在输出端,我们的设计提供智能体在导航过程中可执行动作的概率分布。我们使用人类示范数据和来自Habitat-Matterport 3D数据集(HM3D)的碰撞信号训练模型。实验结果表明,我们的方法优于当前最优的行为克隆方法,并能有效降低碰撞率。