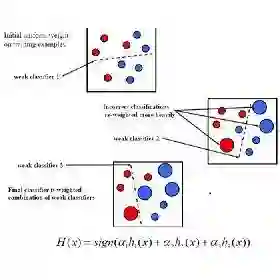
Machine learning methods based on AdaBoost have been widely applied to various classification problems across many mission-critical applications including healthcare, law and finance. However, there is a growing concern about the unfairness and discrimination of data-driven classification models, which is inevitable for classical algorithms including AdaBoost. In order to achieve fair classification, a novel fair AdaBoost (FAB) approach is proposed that is an interpretable fairness-improving variant of AdaBoost. We mainly investigate binary classification problems and focus on the fairness of three different indicators (i.e., accuracy, false positive rate and false negative rate). By utilizing a fairness-aware reweighting technique for base classifiers, the proposed FAB approach can achieve fair classification while maintaining the advantage of AdaBoost with negligible sacrifice of predictive performance. In addition, a hyperparameter is introduced in FAB to show preferences for the fairness-accuracy trade-off. An upper bound for the target loss function that quantifies error rate and unfairness is theoretically derived for FAB, which provides a strict theoretical support for the fairness-improving methods designed for AdaBoost. The effectiveness of the proposed method is demonstrated on three real-world datasets (i.e., Adult, COMPAS and HSLS) with respect to the three fairness indicators. The results are accordant with theoretic analyses, and show that (i) FAB significantly improves classification fairness at a small cost of accuracy compared with AdaBoost; and (ii) FAB outperforms state-of-the-art fair classification methods including equalized odds method, exponentiated gradient method, and disparate mistreatment method in terms of the fairness-accuracy trade-off.
翻译:基于AdaBoost的机器学习方法已广泛应用于医疗、法律和金融等众多关键应用领域的分类问题。然而,数据驱动分类模型的不公平性和歧视性问题日益受到关注,这在包括AdaBoost在内的经典算法中难以避免。为实现公平分类,本文提出一种新颖的公平AdaBoost(FAB)方法,它是AdaBoost的可解释性公平改进变体。我们主要研究二分类问题,并关注三种不同指标(即准确率、假阳性率和假阴性率)的公平性。通过利用公平感知重加权技术对基分类器进行处理,所提出的FAB方法能在保持AdaBoost优势的同时实现公平分类,且预测性能损失可忽略。此外,FAB中引入了一个超参数以体现对公平-准确率权衡的偏好。理论上推导了FAB中量化错误率与不公平性的目标损失函数的上界,为针对AdaBoost设计的公平改进方法提供了严格的理论支撑。基于三种公平性指标,在三个真实数据集(即Adult、COMPAS和HSLS)上验证了所提方法的有效性。结果与理论分析一致,表明:(i)与AdaBoost相比,FAB在牺牲少量准确率的代价下显著提升了分类公平性;(ii)在公平-准确率权衡方面,FAB优于当前最先进的公平分类方法,包括均衡几率法、指数梯度法和差异误治法。