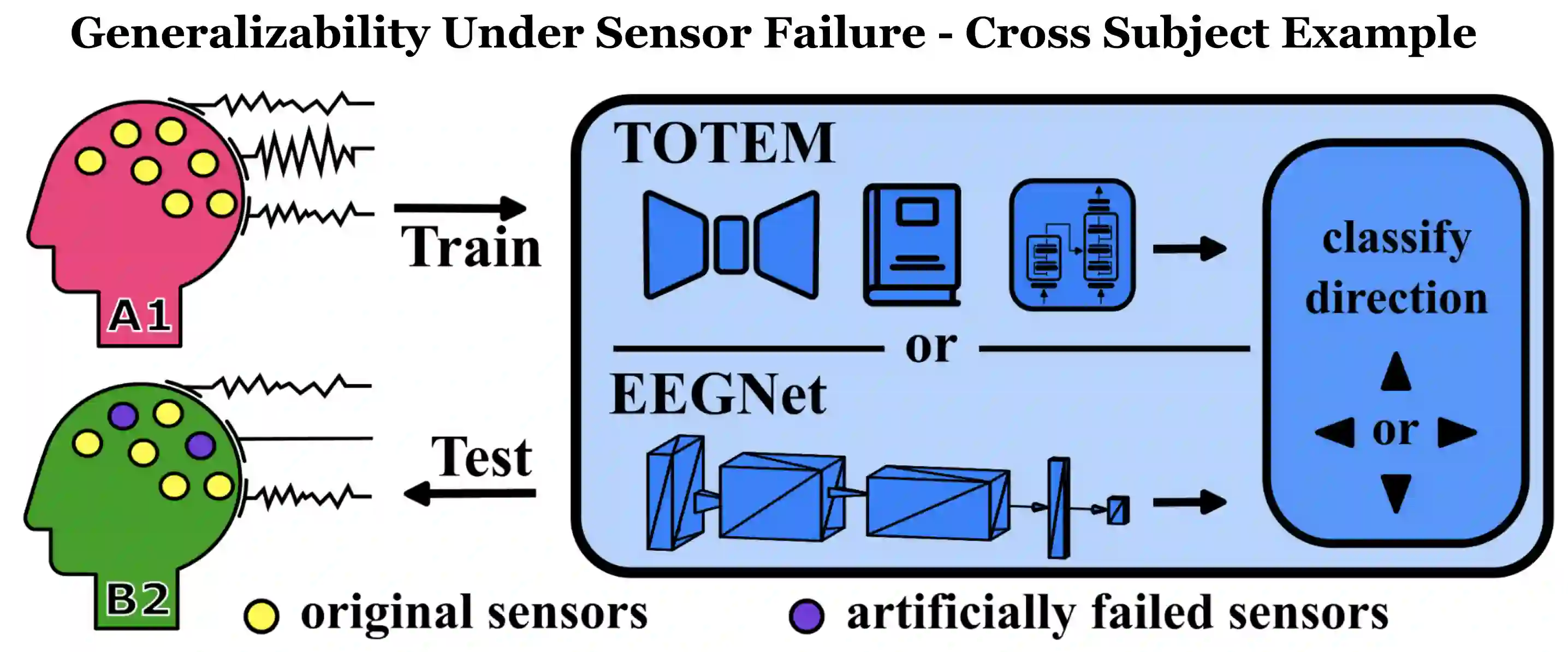
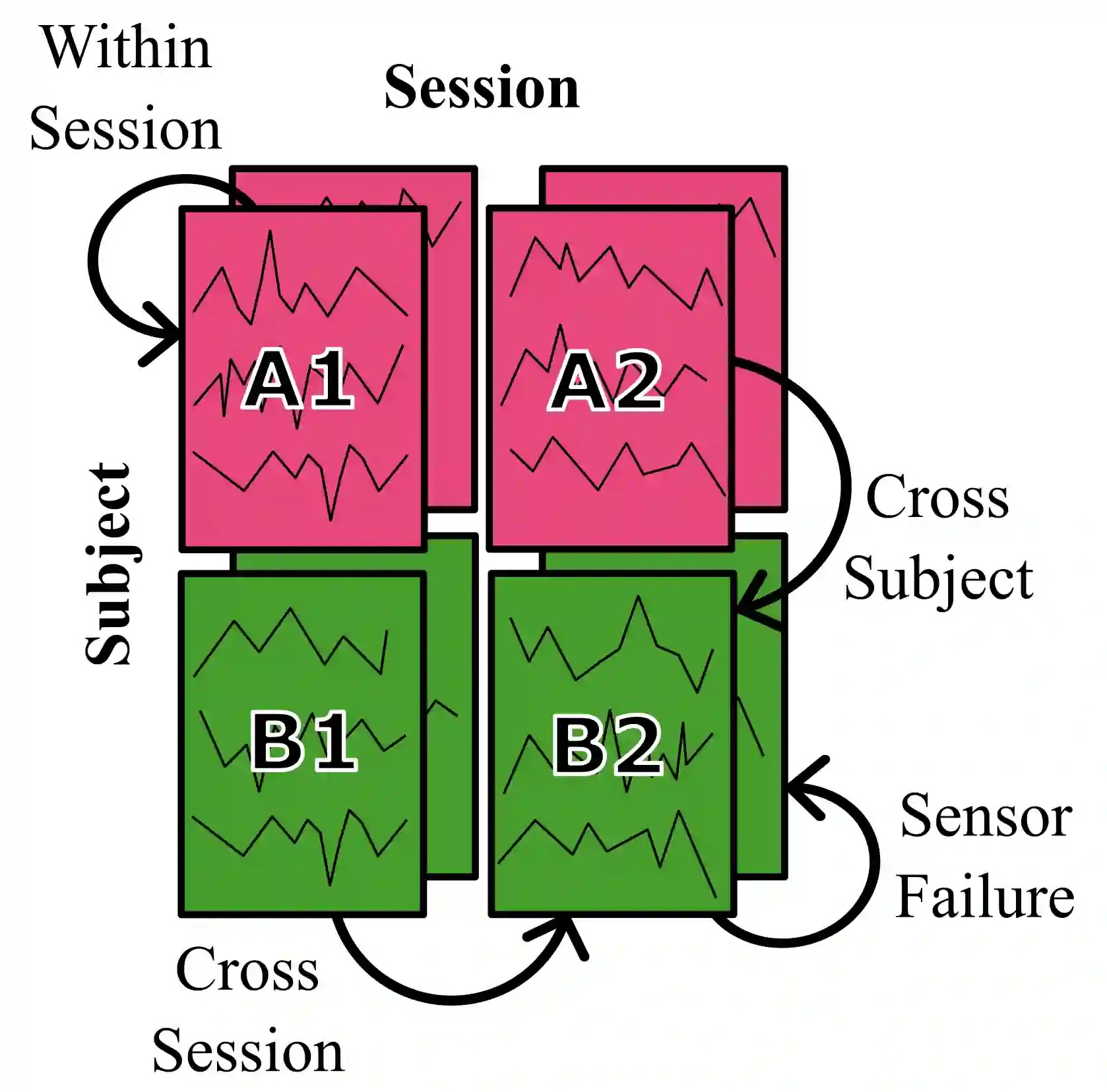
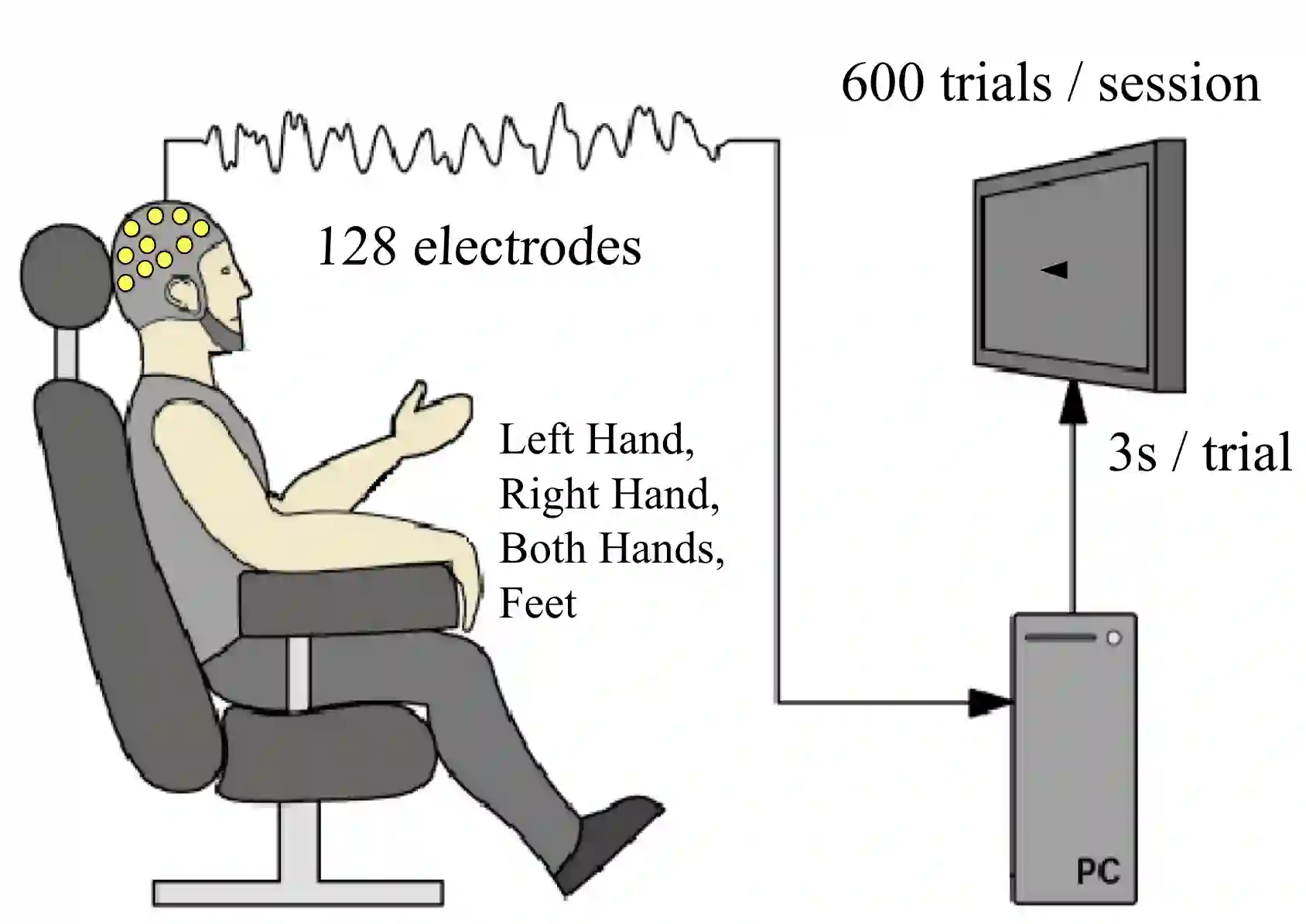
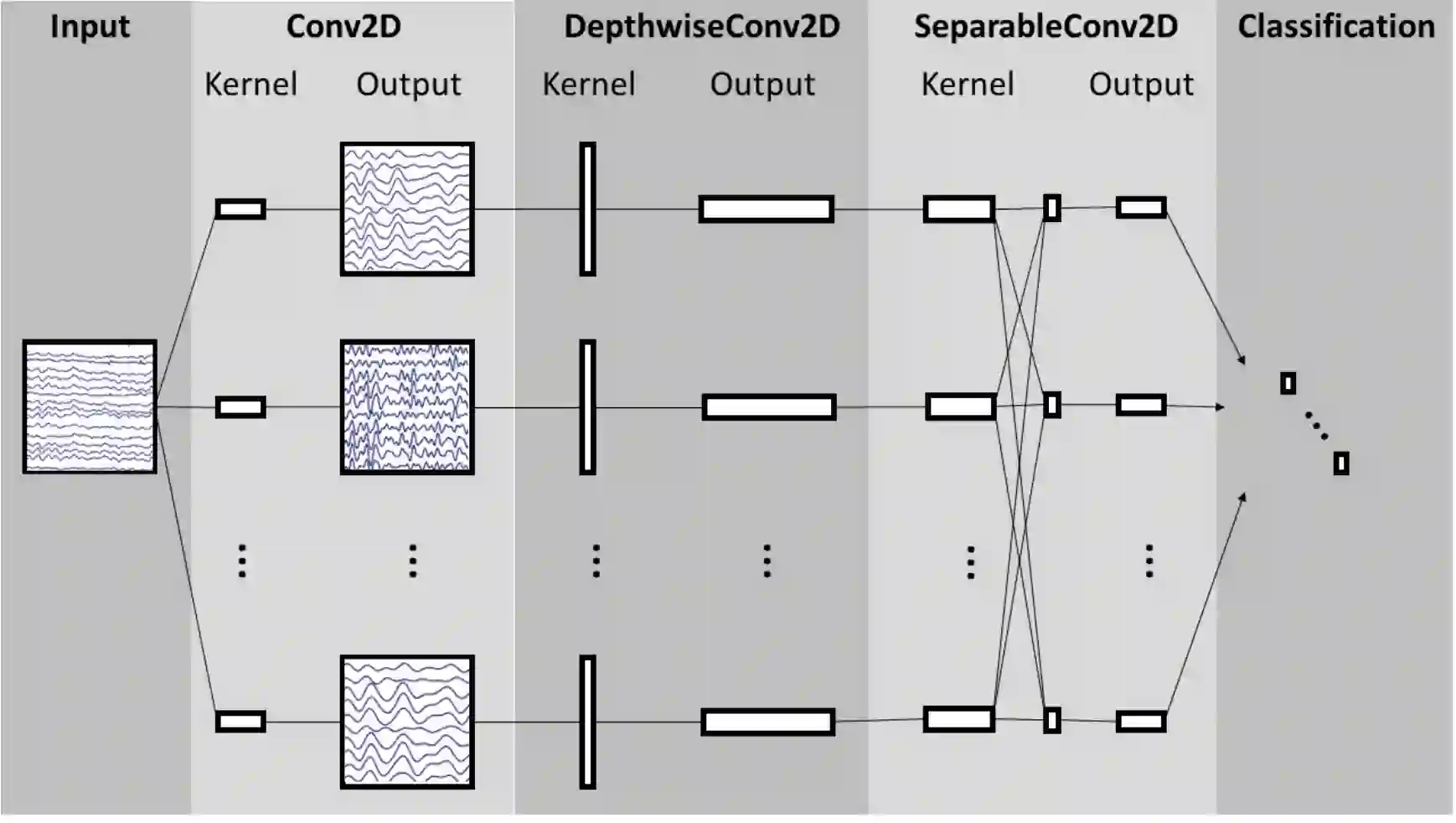
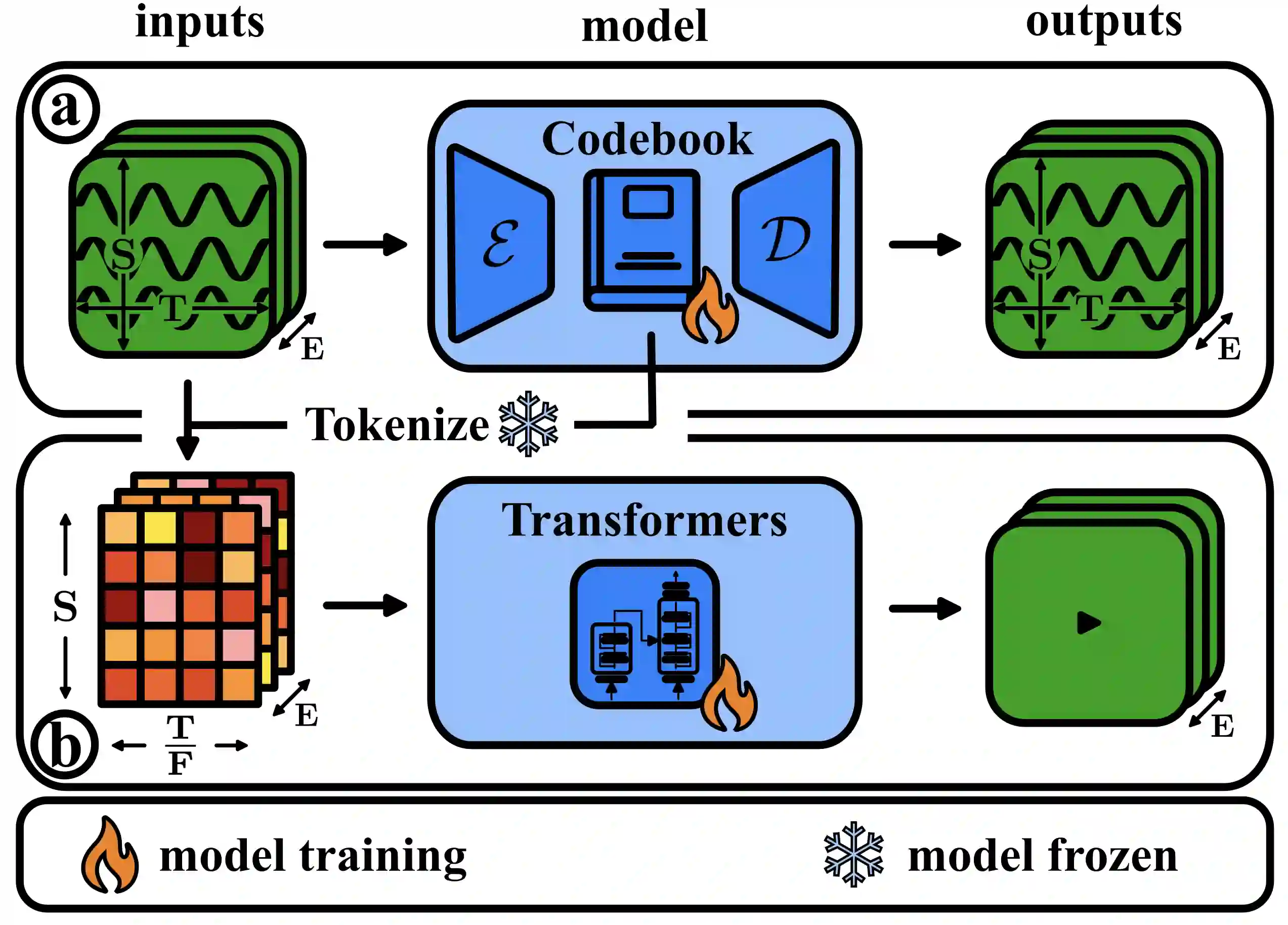
A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization.
翻译:神经科学的核心目标之一是发现可泛化的神经数据表征。这一目标面临来自记录过程(如环境)、受试者(如神经结构差异)及传感器(如噪声)等多维度变异性的挑战。近年研究已开始探索跨记录会话与跨受试者的泛化问题,但针对神经科学实验中高频出现的传感器失效鲁棒性研究仍属空白。为应对这些泛化维度挑战,我们首先采集了包含多会话、多受试者及多传感器的脑电图数据集(自有数据),继而研究了两种时序模型:EEGNet(Lawhern等,2018)与TOTEM(Talukder等,2024)。EEGNet是广泛应用的卷积神经网络,而TOTEM则是一种离散时序分词器—变换器模型。实验表明,在所有泛化测试场景中TOTEM的表现优于或持平于EEGNet。通过对TOTEM潜在编码本的分析,我们揭示了分词化机制是实现泛化能力的关键。