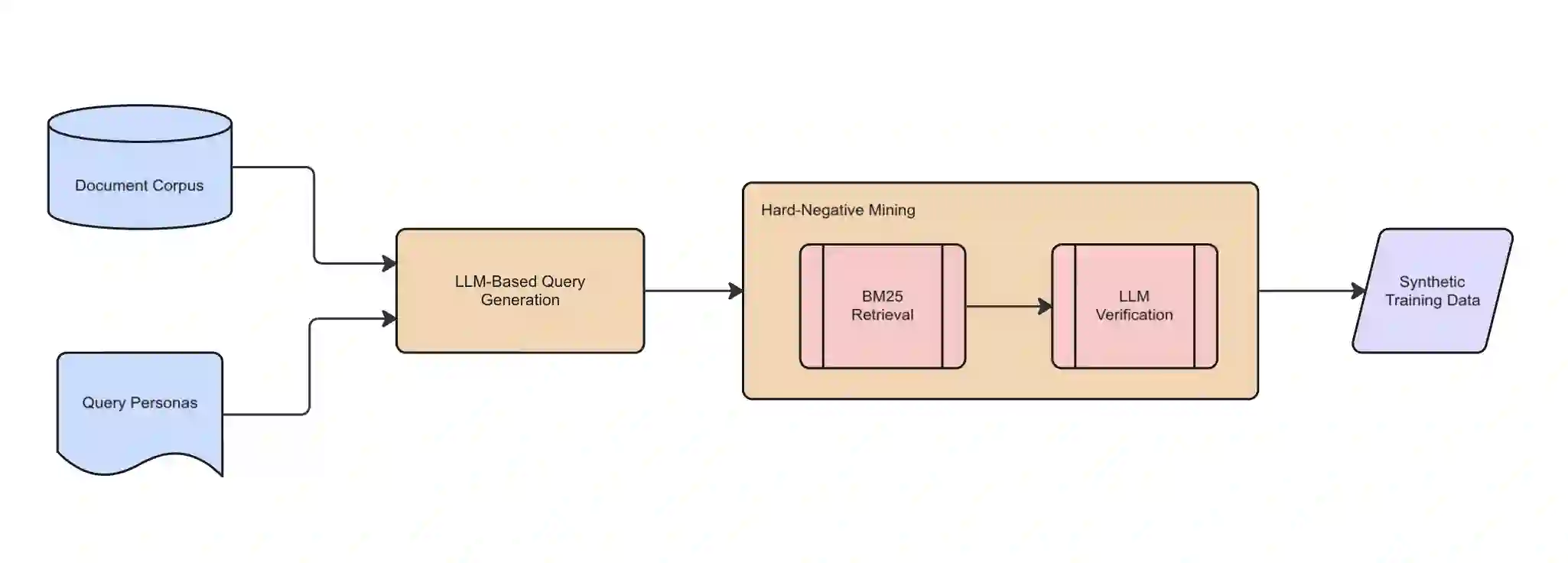
Dense embedding models have become critical for modern information retrieval, particularly in RAG pipelines, but their performance often degrades when applied to specialized corpora outside their pre-training distribution. To address thi we introduce CustomIR, a framework for unsupervised adaptation of pre-trained language embedding models to domain-specific corpora using synthetically generated query-document pairs. CustomIR leverages large language models (LLMs) to create diverse queries grounded in a known target corpus, paired with LLM-verified hard negatives, eliminating the need for costly human annotation. Experiments on enterprise email and messaging datasets show that CustomIR consistently improves retrieval effectiveness with small models gaining up to 2.3 points in Recall@10. This performance increase allows these small models to rival the performance of much larger alternatives, allowing for cheaper RAG deployments. These results highlight that targeted synthetic fine-tuning offers a scalable and cost-efficient strategy for increasing domain-specific performance.
翻译:密集嵌入模型已成为现代信息检索的关键技术,尤其在RAG(检索增强生成)流程中,但当应用于预训练分布之外的专业语料库时,其性能往往下降。为解决这一问题,我们提出了CustomIR框架,该框架通过使用合成生成的查询-文档对,对预训练语言嵌入模型进行无监督自适应,以适应特定领域语料库。CustomIR利用大型语言模型(LLMs)基于已知目标语料库生成多样化查询,并配对经LLM验证的困难负样本,从而无需昂贵的人工标注。在企业电子邮件和消息数据集上的实验表明,CustomIR持续提升了检索效果,小型模型在Recall@10指标上最高提升了2.3个百分点。这一性能提升使得这些小型模型能够媲美更大规模替代模型的性能,从而降低RAG部署成本。这些结果凸显了定向合成微调为提升领域特定性能提供了一种可扩展且经济高效的策略。