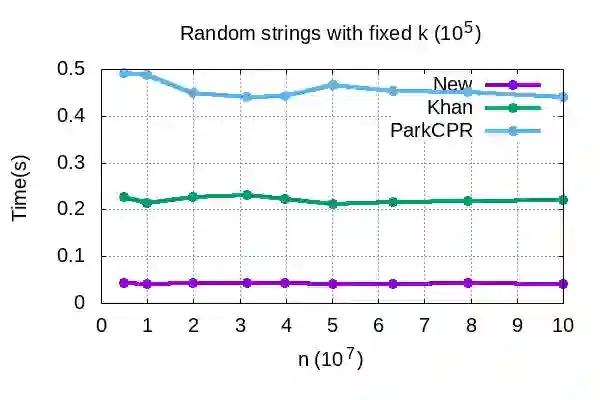
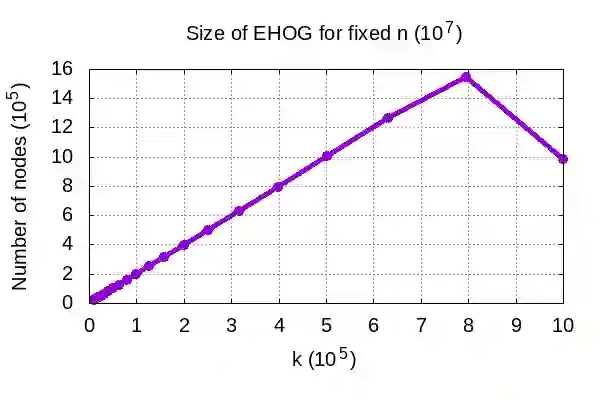
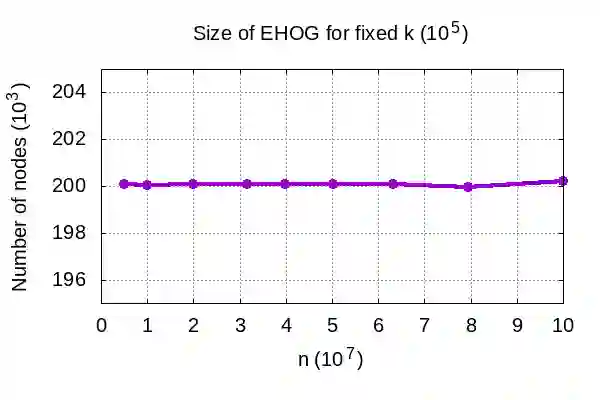
Genome assembly is a prominent problem studied in bioinformatics, which computes the source string using a set of its overlapping substrings. Classically, genome assembly uses assembly graphs built using this set of substrings to compute the source string efficiently, having a tradeoff between scalability and avoiding information loss. The scalable de Bruijn graphs come at the price of losing crucial overlap information. The complete overlap information is stored in overlap graphs using quadratic space. Hierarchical overlap graphs [IPL20] (HOG) overcome these limitations, avoiding information loss despite using linear space. After a series of suboptimal improvements, Khan and Park et al. simultaneously presented two optimal algorithms [CPM2021], where only the former was seemingly practical. We empirically analyze all the practical algorithms for computing HOG, where the optimal algorithm [CPM2021] outperforms the previous algorithms as expected, though at the expense of extra memory. However, it uses non-intuitive approach and non-trivial data structures. We present arguably the most intuitive algorithm, using only elementary arrays, which is also optimal. Our algorithm empirically proves even better for both time and memory over all the algorithms, highlighting its significance in both theory and practice. We further explore the applications of hierarchical overlap graphs to solve various forms of suffix-prefix queries on a set of strings. Loukides et al. [CPM2023] recently presented state-of-the-art algorithms for these queries. However, these algorithms require complex black-box data structures and are seemingly impractical. Our algorithms, despite failing to match the state-of-the-art algorithms theoretically, answer different queries ranging from 0.01-100 milliseconds for a data set having around a billion characters.
翻译:基因组组装是生物信息学中的重要问题,它通过利用一组相互重叠的子串来重构源字符串。经典方法利用基于这组子串构建的组装图高效地计算源字符串,但在可扩展性和信息完整性之间存在权衡。可扩展的de Bruijn图以丢失关键重叠信息为代价。完整重叠信息存储在需要二次空间的叠加图中。分层重叠图[IPL20] (HOG)克服了这些限制,在使用线性空间的同时避免信息丢失。在一系列次优改进之后,Khan和Park等人同时提出了两种最优算法[CPM2021],其中前者在实践中似乎更为可行。我们对所有计算HOG的实用算法进行了实证分析,其中最优算法[CPM2021]按预期优于先前算法,但以额外内存为代价。然而,该算法采用了非直观的方法和非平凡的数据结构。我们提出了据称最直观的算法,仅使用基础数组,且同为最优。所有算法的实证结果表明,我们的算法在时间和内存方面表现更佳,突显了其在理论与实践中的重要意义。我们进一步探索了分层重叠图在解决字符串集合多种后缀-前缀查询中的应用。Loukides等人[CPM2023]近期提出了针对这些查询的最先进算法,但需要复杂的黑盒数据结构,在实践上似乎不可行。我们的算法尽管在理论上未能达到最先进的水平,但对于包含约十亿个字符的数据集,其查询响应时间仅为0.01-100毫秒。