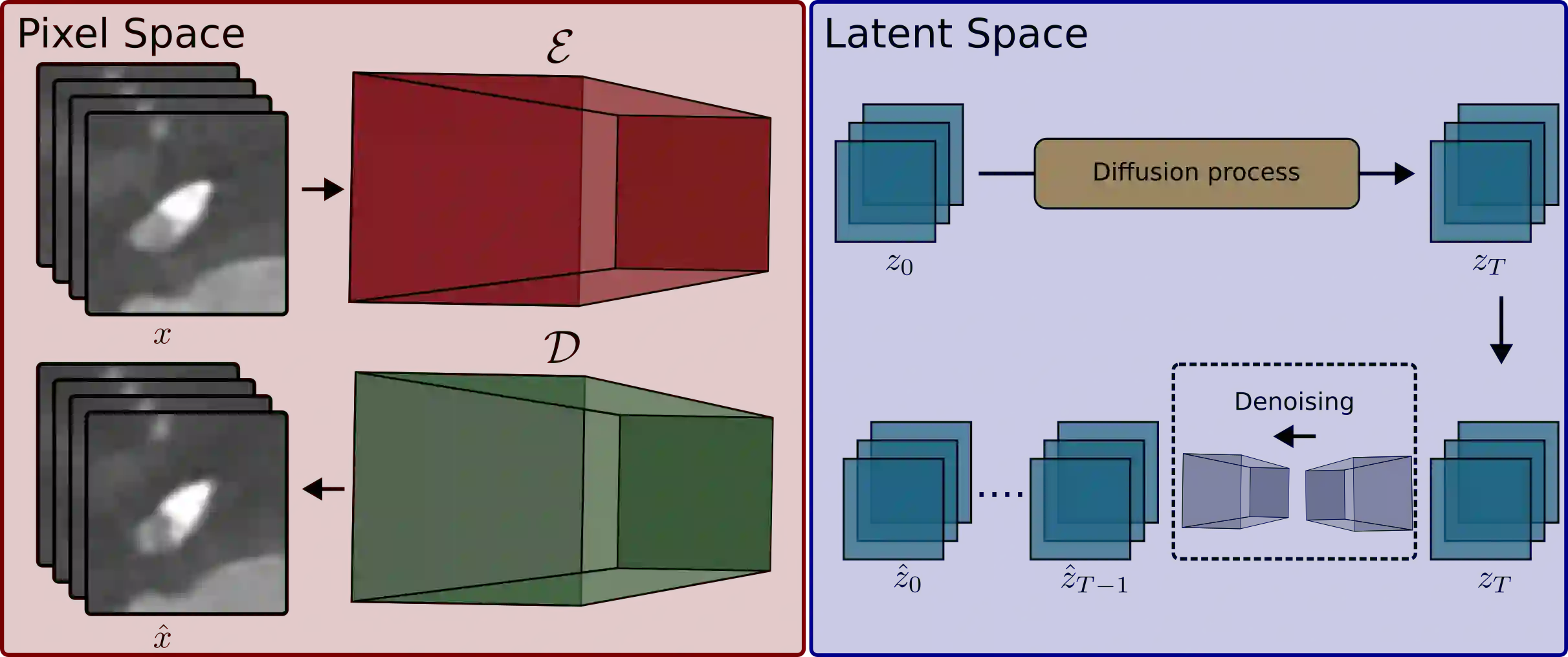
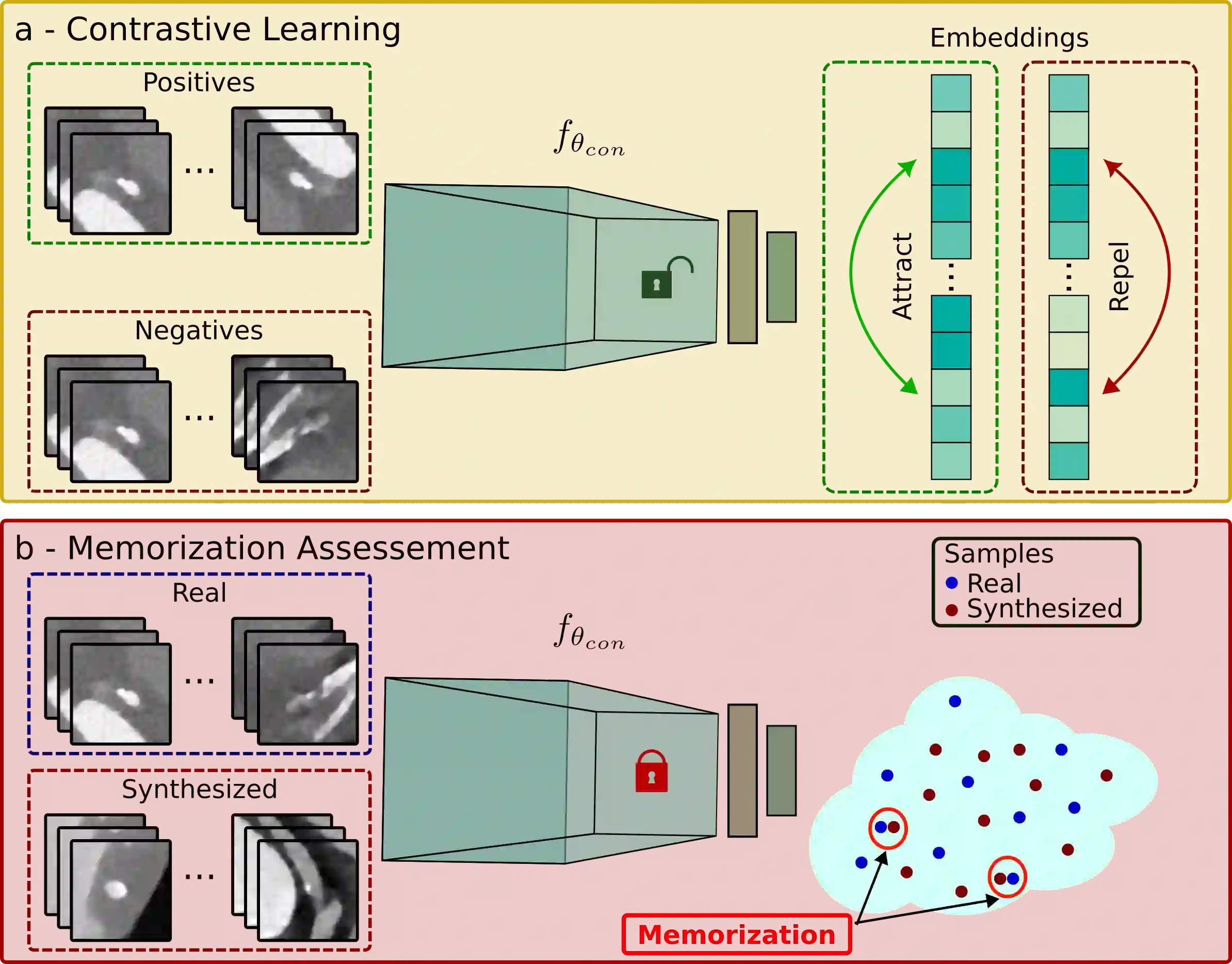
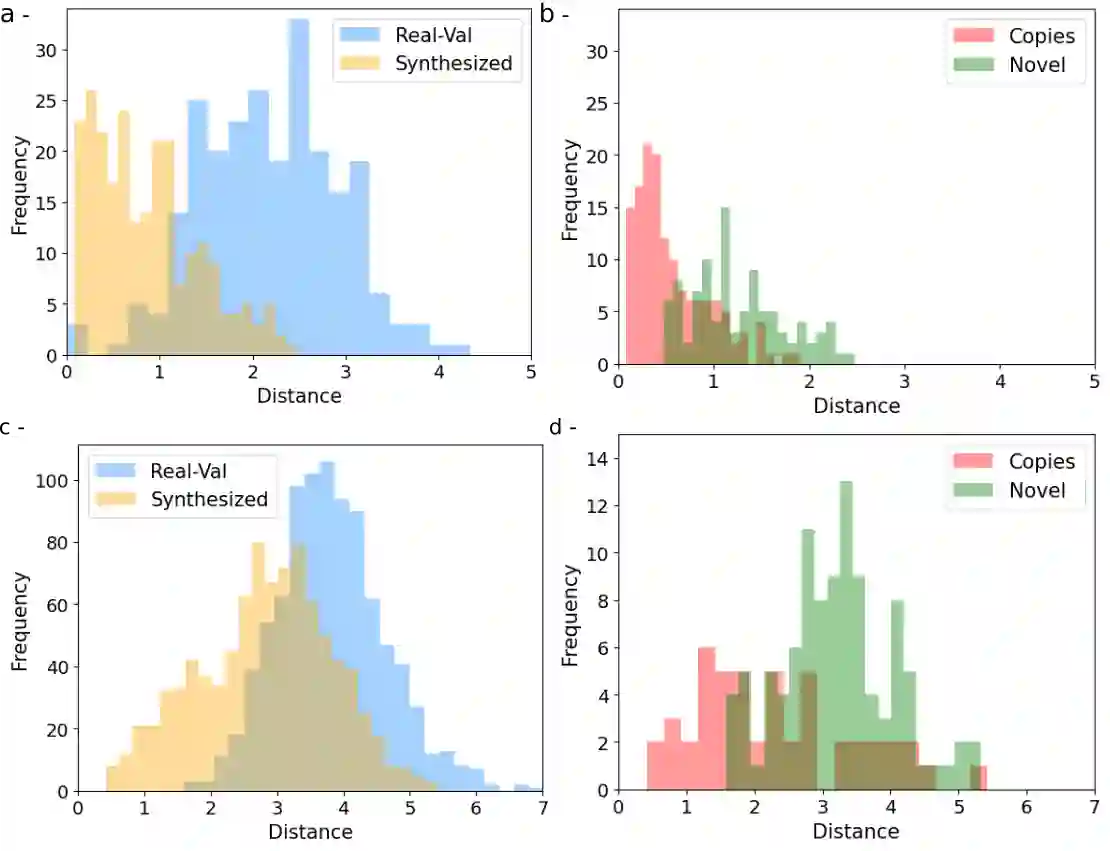
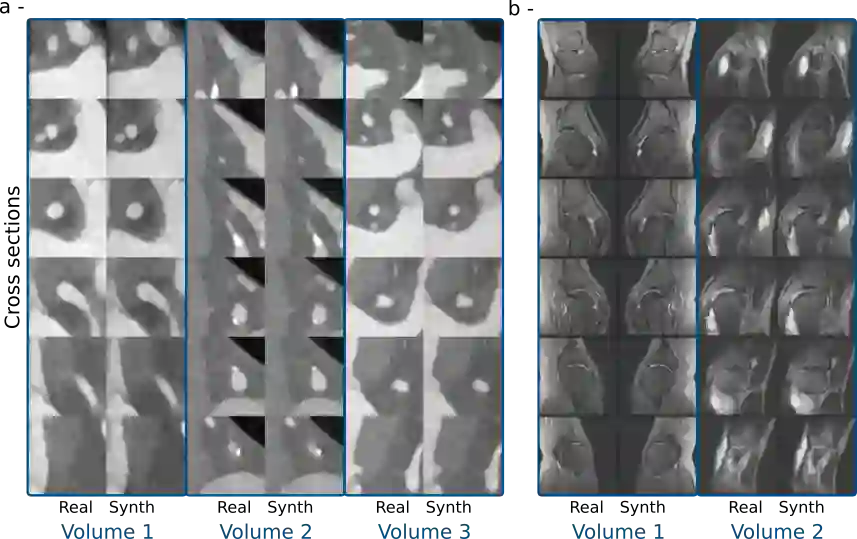
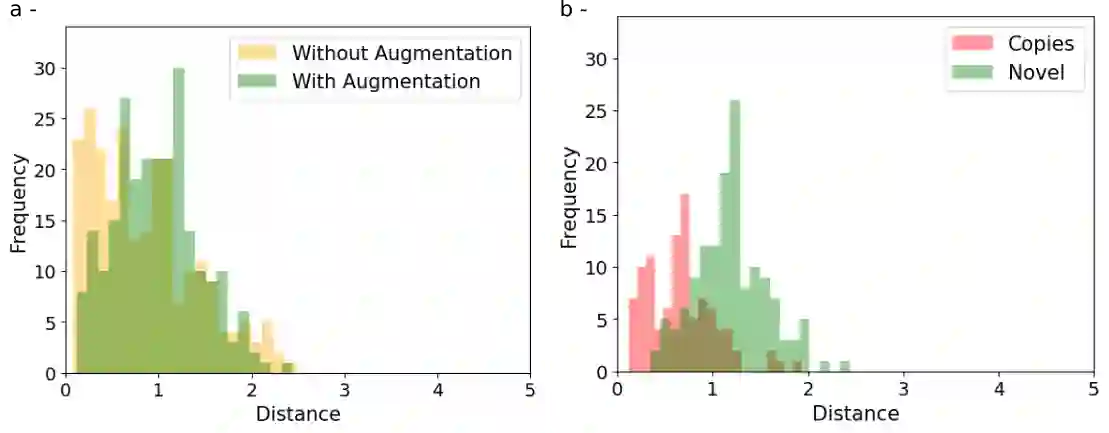
Generative latent diffusion models have been established as state-of-the-art in data generation. One promising application is generation of realistic synthetic medical imaging data for open data sharing without compromising patient privacy. Despite the promise, the capacity of such models to memorize sensitive patient training data and synthesize samples showing high resemblance to training data samples is relatively unexplored. Here, we assess the memorization capacity of 3D latent diffusion models on photon-counting coronary computed tomography angiography and knee magnetic resonance imaging datasets. To detect potential memorization of training samples, we utilize self-supervised models based on contrastive learning. Our results suggest that such latent diffusion models indeed memorize training data, and there is a dire need for devising strategies to mitigate memorization.
翻译:生成式潜在扩散模型已成为数据生成领域的最先进技术。其中一个有前景的应用是生成逼真的合成医学影像数据,以便在开放数据共享中不损害患者隐私。然而,这类模型记忆敏感患者训练数据并生成与训练数据样本高度相似的合成样本的能力尚未得到充分研究。本文在光子计数冠状动脉计算机断层扫描血管造影和膝关节磁共振成像数据集上评估了3D潜在扩散模型的记忆能力。为检测训练样本的潜在记忆,我们采用了基于对比学习的自监督模型。研究结果表明,这类潜在扩散模型确实会记忆训练数据,迫切需要制定策略来减轻记忆效应。