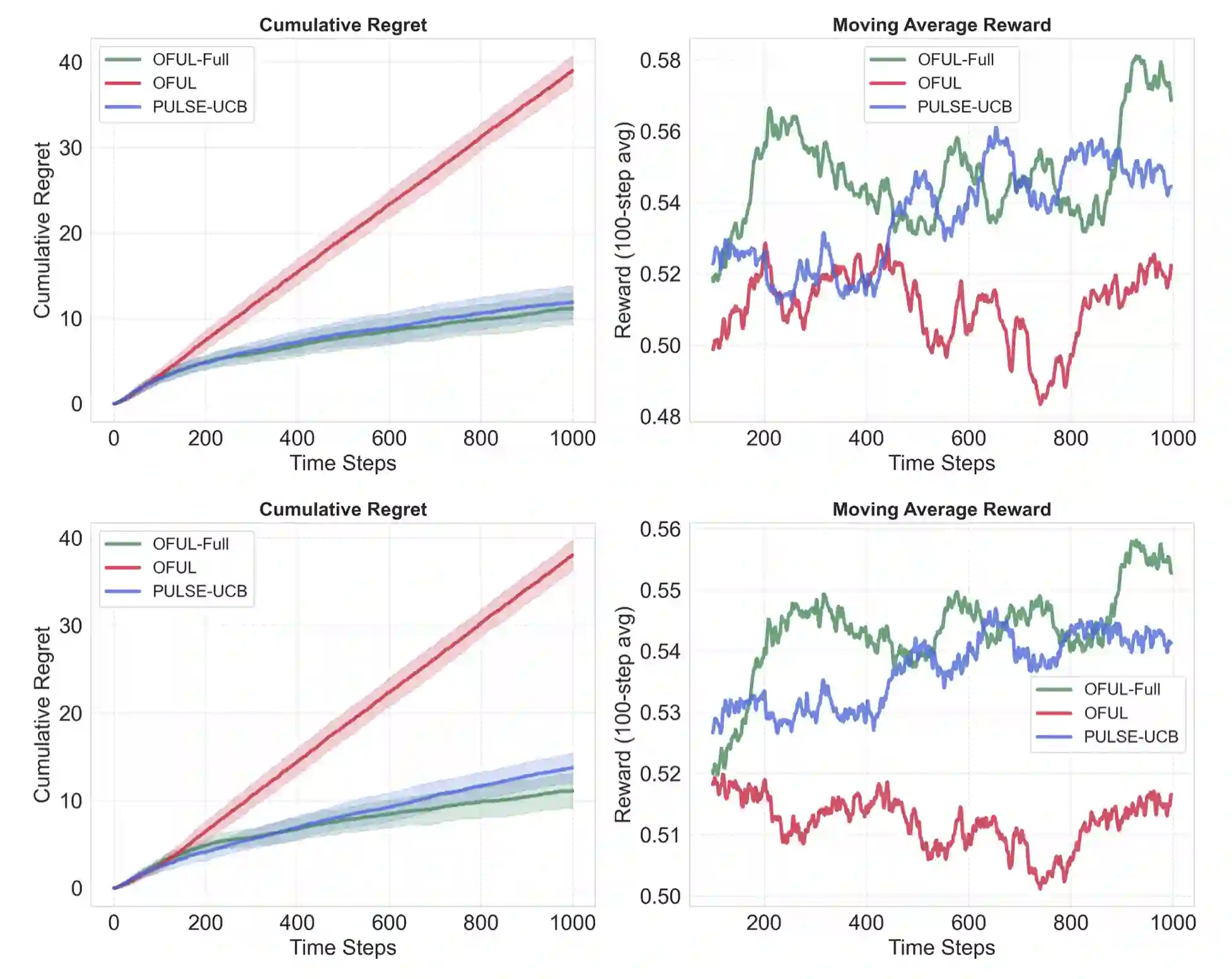
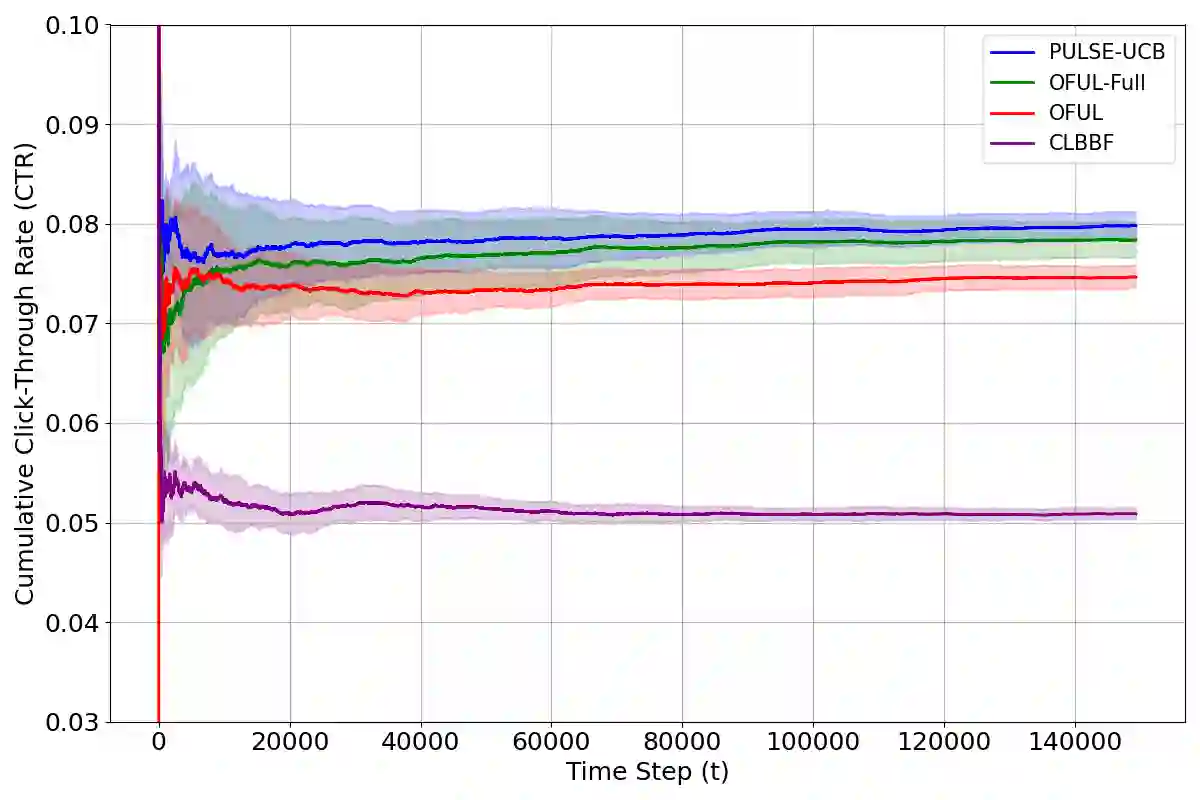
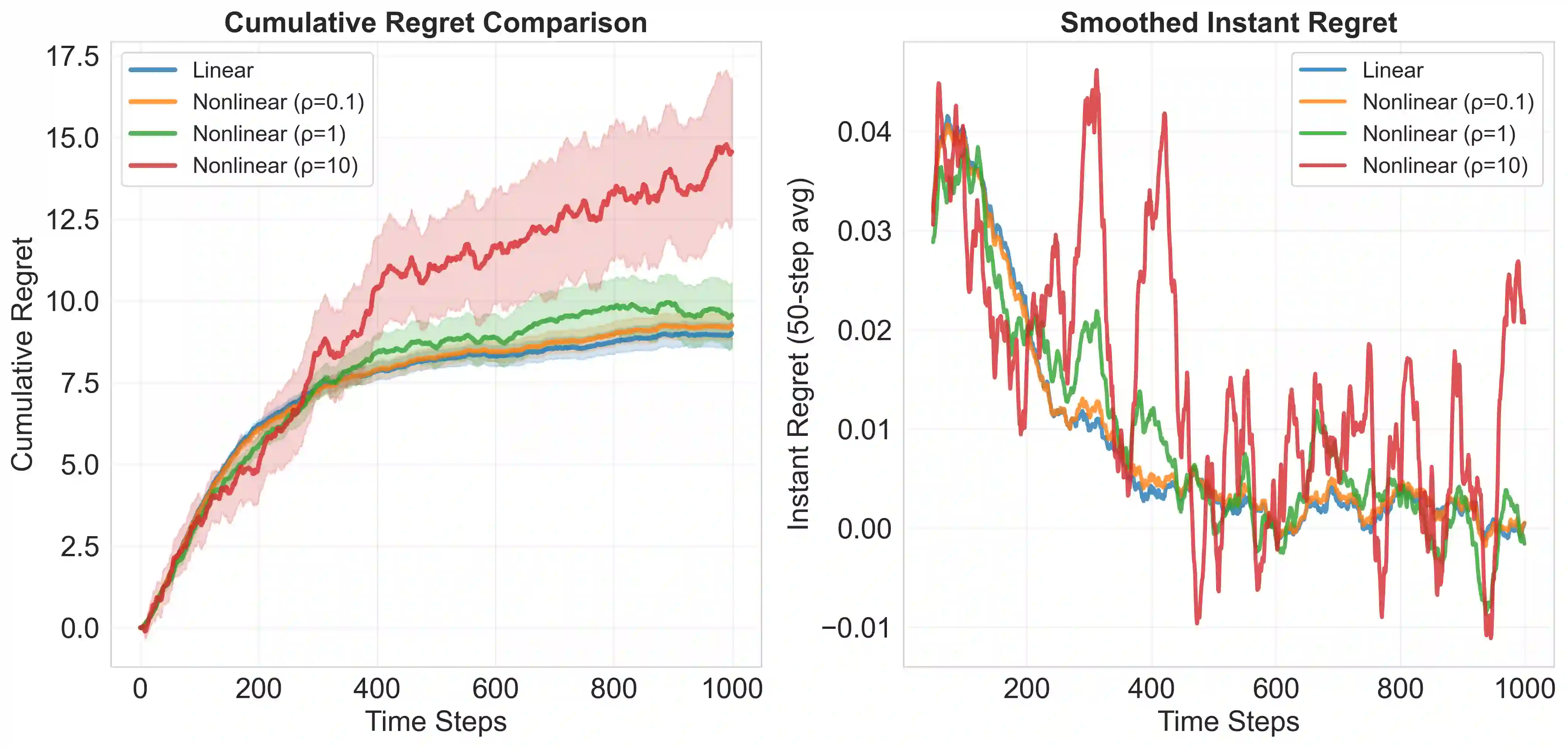
The rise of large-scale pretrained models has made it feasible to generate predictive or synthetic features at low cost, raising the question of how to incorporate such surrogate predictions into downstream decision-making. We study this problem in the setting of online linear contextual bandits, where contexts may be complex, nonstationary, and only partially observed. In addition to bandit data, we assume access to an auxiliary dataset containing fully observed contexts--common in practice since such data are collected without adaptive interventions. We propose PULSE-UCB, an algorithm that leverages pretrained models trained on the auxiliary data to impute missing features during online decision-making. We establish regret guarantees that decompose into a standard bandit term plus an additional component reflecting pretrained model quality. In the i.i.d. context case with H\"older-smooth missing features, PULSE-UCB achieves near-optimal performance, supported by matching lower bounds. Our results quantify how uncertainty in predicted contexts affects decision quality and how much historical data is needed to improve downstream learning.
翻译:大规模预训练模型的兴起使得以低成本生成预测性或合成特征成为可能,这引发了如何将此类代理预测纳入下游决策的问题。我们在在线线性上下文赌博机框架下研究该问题,其中上下文可能复杂、非平稳且仅被部分观测。除了赌博机数据,我们假设可访问一个包含完整观测上下文的辅助数据集——这在实践中很常见,因为此类数据收集无需自适应干预。我们提出PULSE-UCB算法,该算法利用在辅助数据上训练的预训练模型,在在线决策过程中对缺失特征进行插补。我们建立了遗憾保证,可分解为标准赌博机项加上反映预训练模型质量的附加项。在具有H\"older光滑缺失特征的独立同分布上下文情形下,PULSE-UCB实现了接近最优的性能,并通过匹配下界得到支撑。我们的结果量化了预测上下文中的不确定性如何影响决策质量,以及需要多少历史数据来改进下游学习。