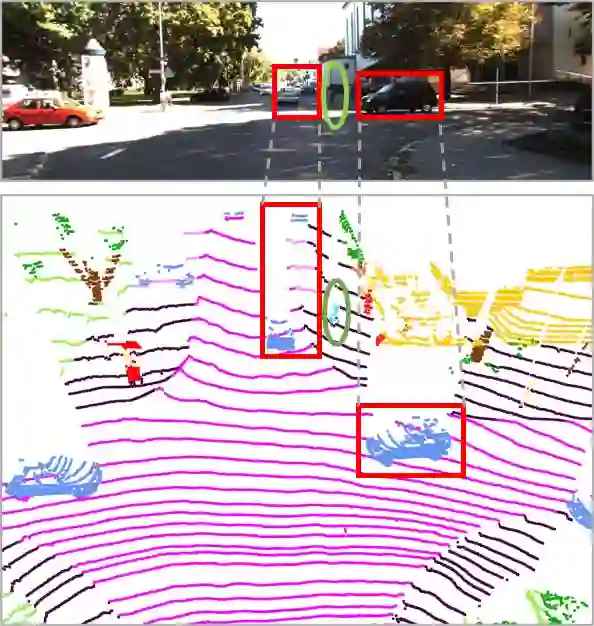
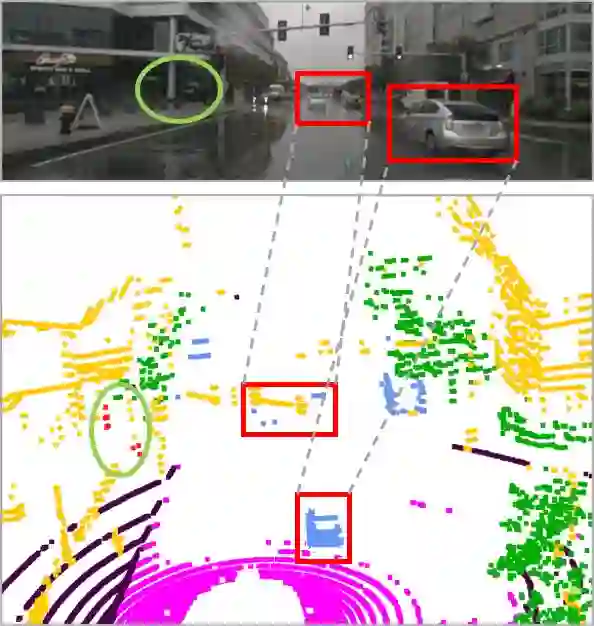
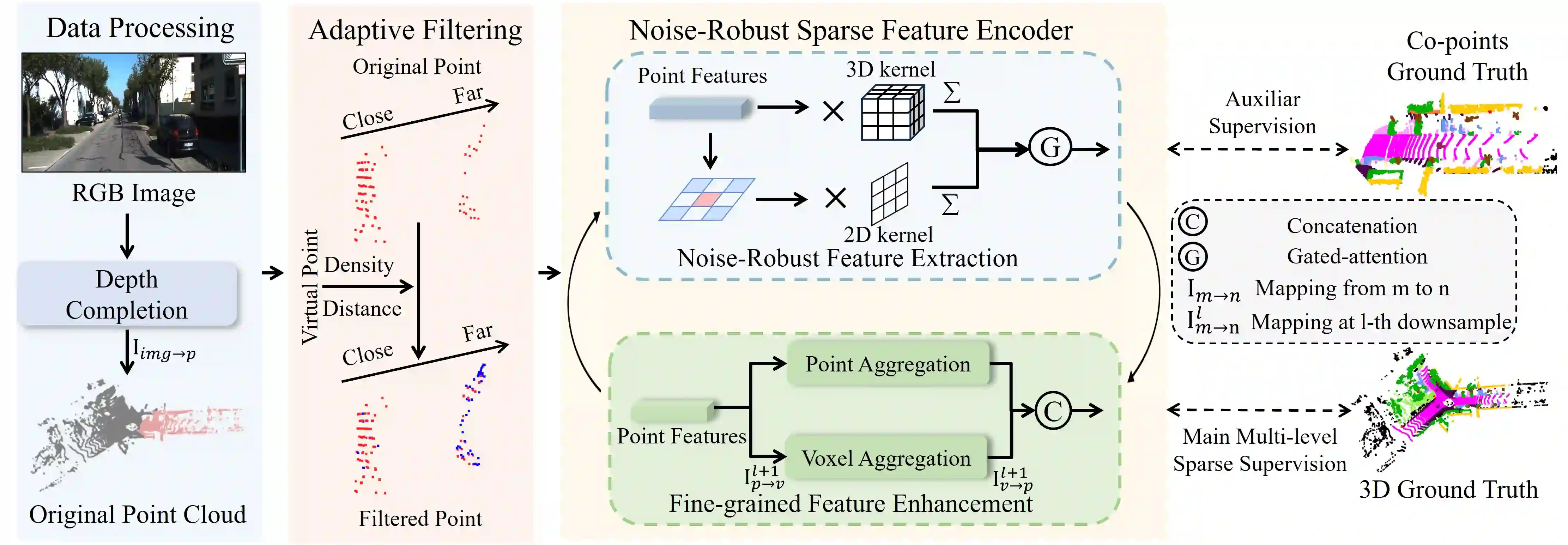
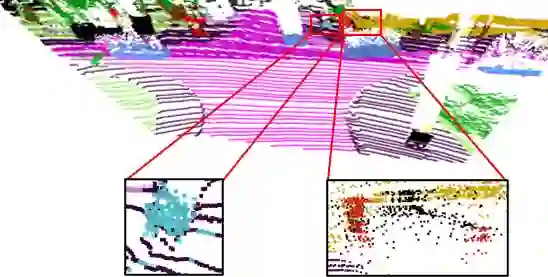
LiDAR-based 3D point cloud recognition has been proven beneficial in various applications. However, the sparsity and varying density pose a significant challenge in capturing intricate details of objects, particularly for medium-range and small targets. Therefore, we propose a multi-modal point cloud semantic segmentation method based on Virtual Point Enhancement (VPE), which integrates virtual points generated from images to address these issues. These virtual points are dense but noisy, and directly incorporating them can increase computational burden and degrade performance. Therefore, we introduce a spatial difference-driven adaptive filtering module that selectively extracts valuable pseudo points from these virtual points based on density and distance, enhancing the density of medium-range targets. Subsequently, we propose a noise-robust sparse feature encoder that incorporates noise-robust feature extraction and fine-grained feature enhancement. Noise-robust feature extraction exploits the 2D image space to reduce the impact of noisy points, while fine-grained feature enhancement boosts sparse geometric features through inner-voxel neighborhood point aggregation and downsampled voxel aggregation. The results on the SemanticKITTI and nuScenes, two large-scale benchmark data sets, have validated effectiveness, significantly improving 2.89\% mIoU with the introduction of 7.7\% virtual points on nuScenes.
翻译:基于LiDAR的三维点云识别已被证明在多种应用中具有优势。然而,点云的稀疏性和密度不均对捕获物体精细细节构成了重大挑战,尤其对于中距离和小型目标。为此,我们提出了一种基于虚拟点增强的多模态点云语义分割方法,该方法通过融合由图像生成的虚拟点来解决上述问题。这些虚拟点密集但含有噪声,直接引入会增加计算负担并降低性能。因此,我们引入了一个空间差异驱动的自适应滤波模块,该模块基于密度和距离从虚拟点中有选择地提取有价值的伪点,从而增强中距离目标的点云密度。随后,我们提出了一种噪声鲁棒的稀疏特征编码器,它集成了噪声鲁棒特征提取和细粒度特征增强。噪声鲁棒特征提取利用二维图像空间来降低噪声点的影响,而细粒度特征增强则通过体素内邻域点聚合和下采样体素聚合来增强稀疏几何特征。在SemanticKITTI和nuScenes这两个大规模基准数据集上的结果验证了该方法的有效性,在nuScenes数据集上引入7.7%的虚拟点后,平均交并比显著提升了2.89%。