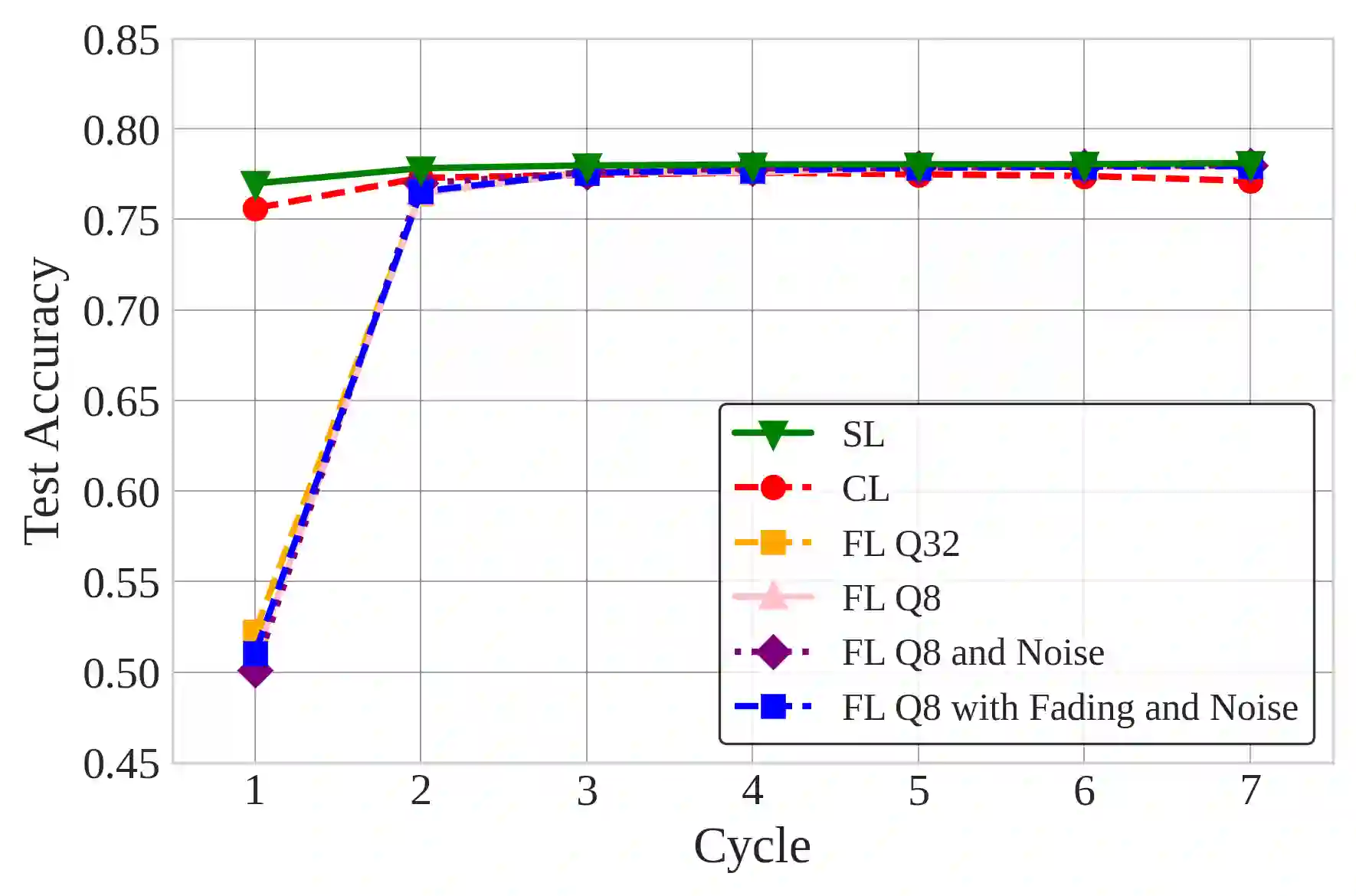
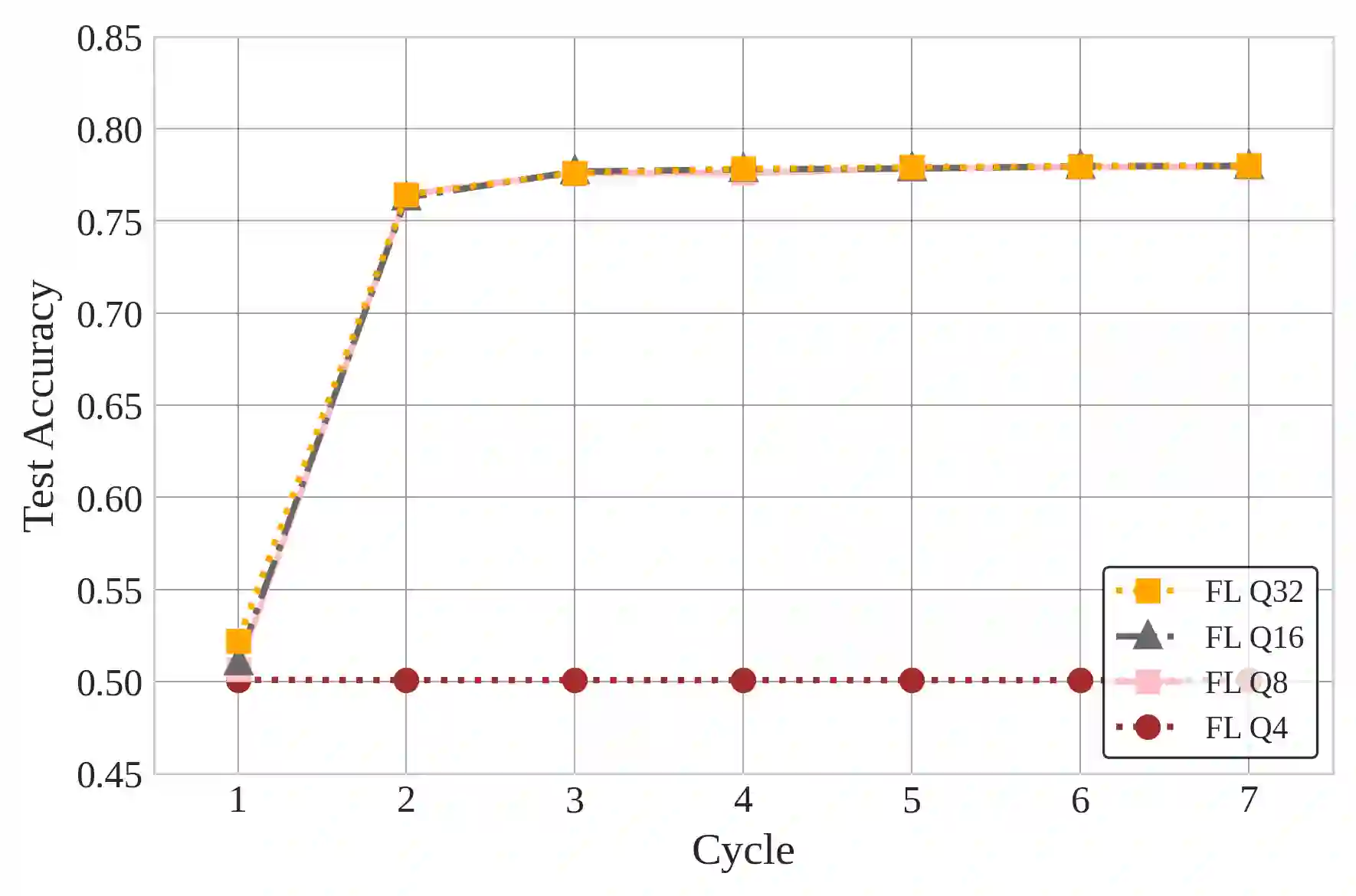
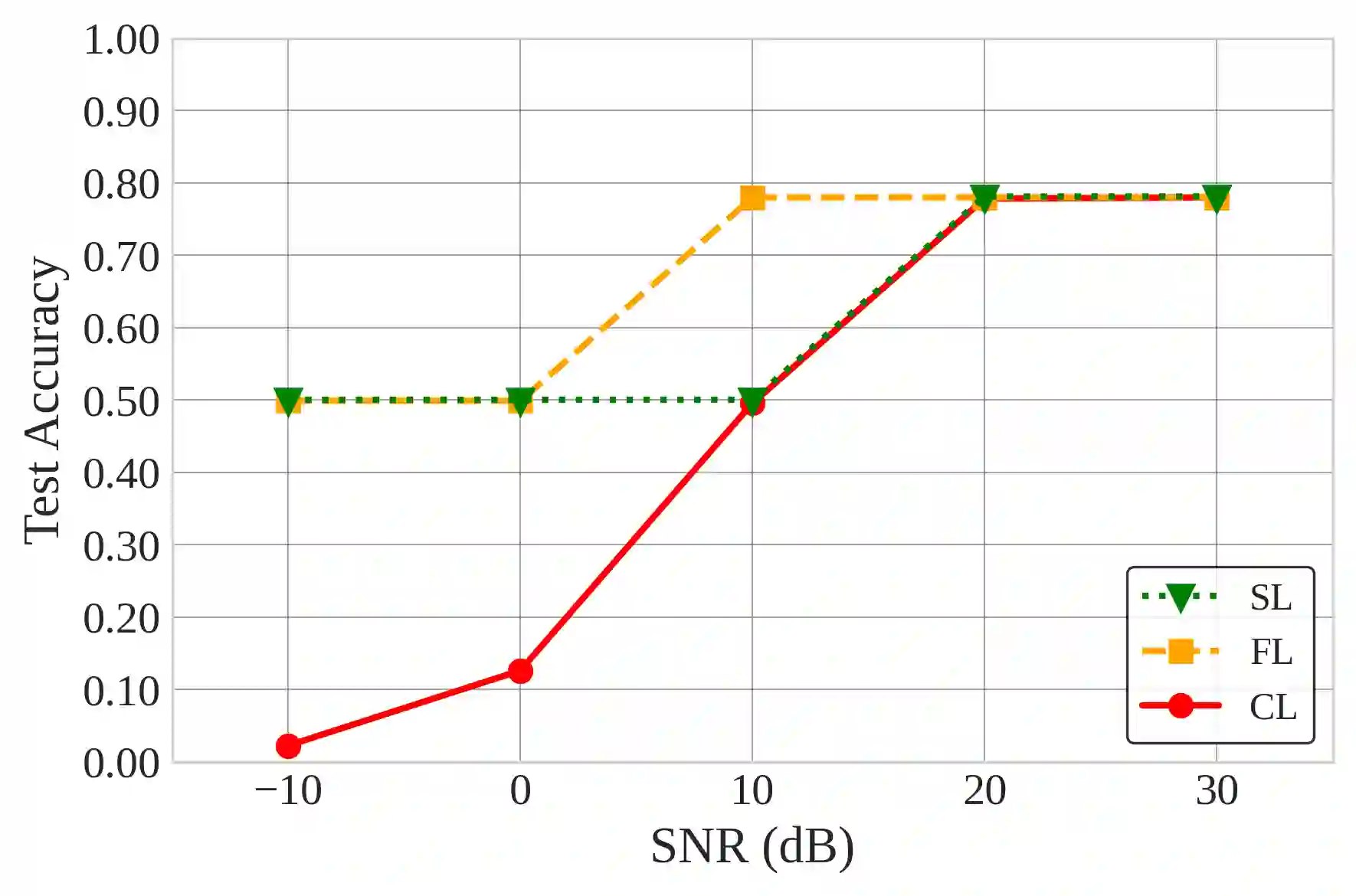
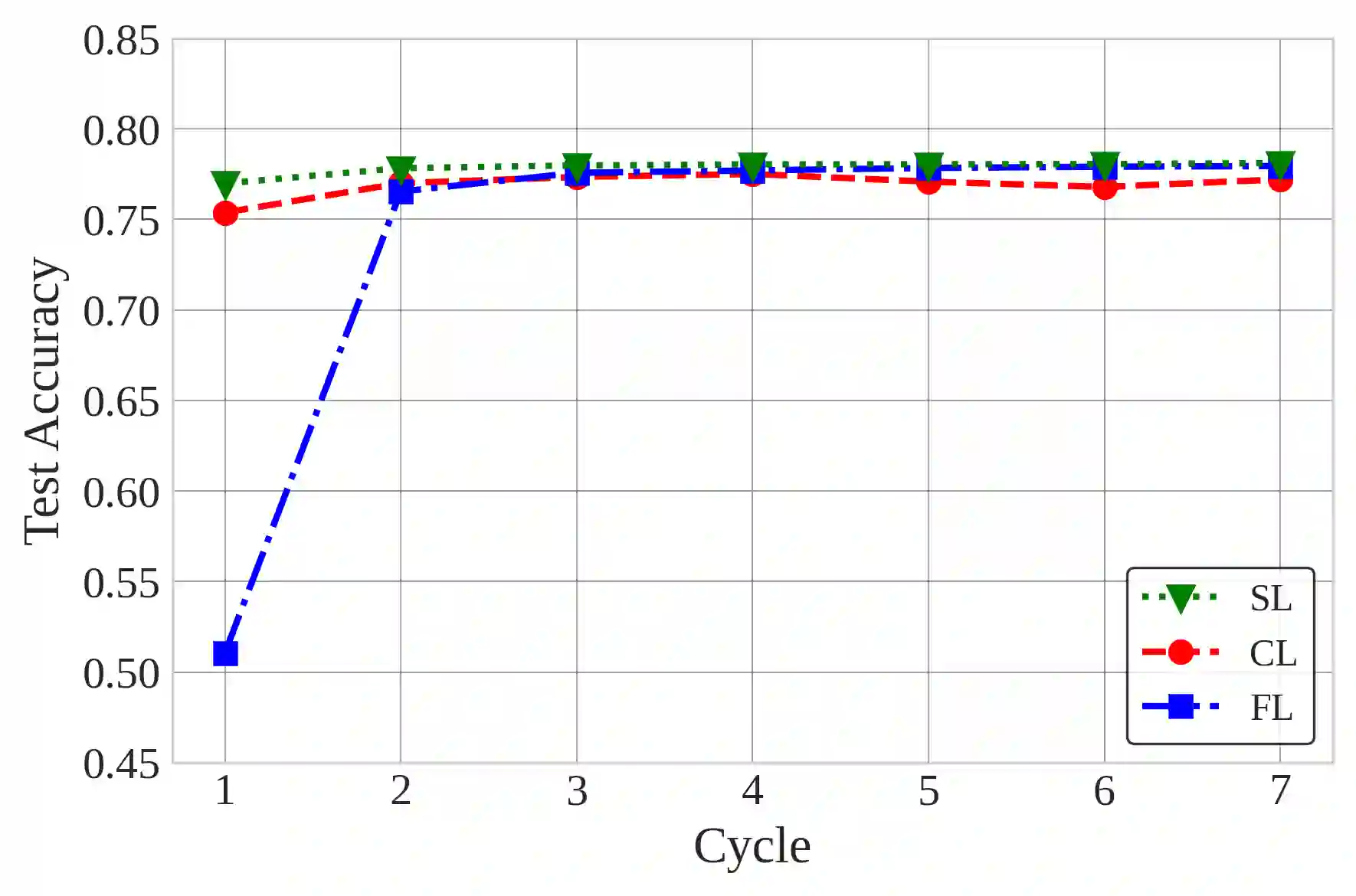
Natural Language Processing (NLP) operations, such as semantic sentiment analysis and text synthesis, often raise privacy concerns and demand significant on-device computational resources. Centralized Learning (CL) on the edge provides an energy-efficient alternative but requires collecting raw data, compromising user privacy. While Federated Learning (FL) enhances privacy, it imposes high computational energy demands on resource-constrained devices. We introduce Split Learning (SL) as an energy-efficient, privacy-preserving Tiny Machine Learning (TinyML) framework and compare it to FL and CL in the presence of Rayleigh fading and additive noise. Our results show that SL significantly reduces computational power and CO2 emissions while enhancing privacy, as evidenced by a fourfold increase in reconstruction error compared to FL and nearly eighteen times that of CL. In contrast, FL offers a balanced trade-off between privacy and efficiency. This study provides insights into deploying privacy-preserving, energy-efficient NLP models on edge devices.
翻译:自然语言处理(NLP)任务,如语义情感分析和文本合成,常引发隐私担忧,并需要大量的设备端计算资源。边缘侧的集中式学习(CL)提供了一种高能效的替代方案,但需要收集原始数据,从而损害用户隐私。虽然联邦学习(FL)增强了隐私保护,但它对资源受限的设备施加了较高的计算能耗要求。我们引入分割学习(SL)作为一种高能效、保护隐私的微型机器学习(TinyML)框架,并在存在瑞利衰落和加性噪声的情况下,将其与FL和CL进行比较。我们的结果表明,SL显著降低了计算功耗和二氧化碳排放,同时增强了隐私保护,其重建误差相比FL增加了四倍,相比CL增加了近十八倍,这提供了有力证据。相比之下,FL在隐私与效率之间提供了更均衡的权衡。本研究为在边缘设备上部署保护隐私、高能效的NLP模型提供了见解。