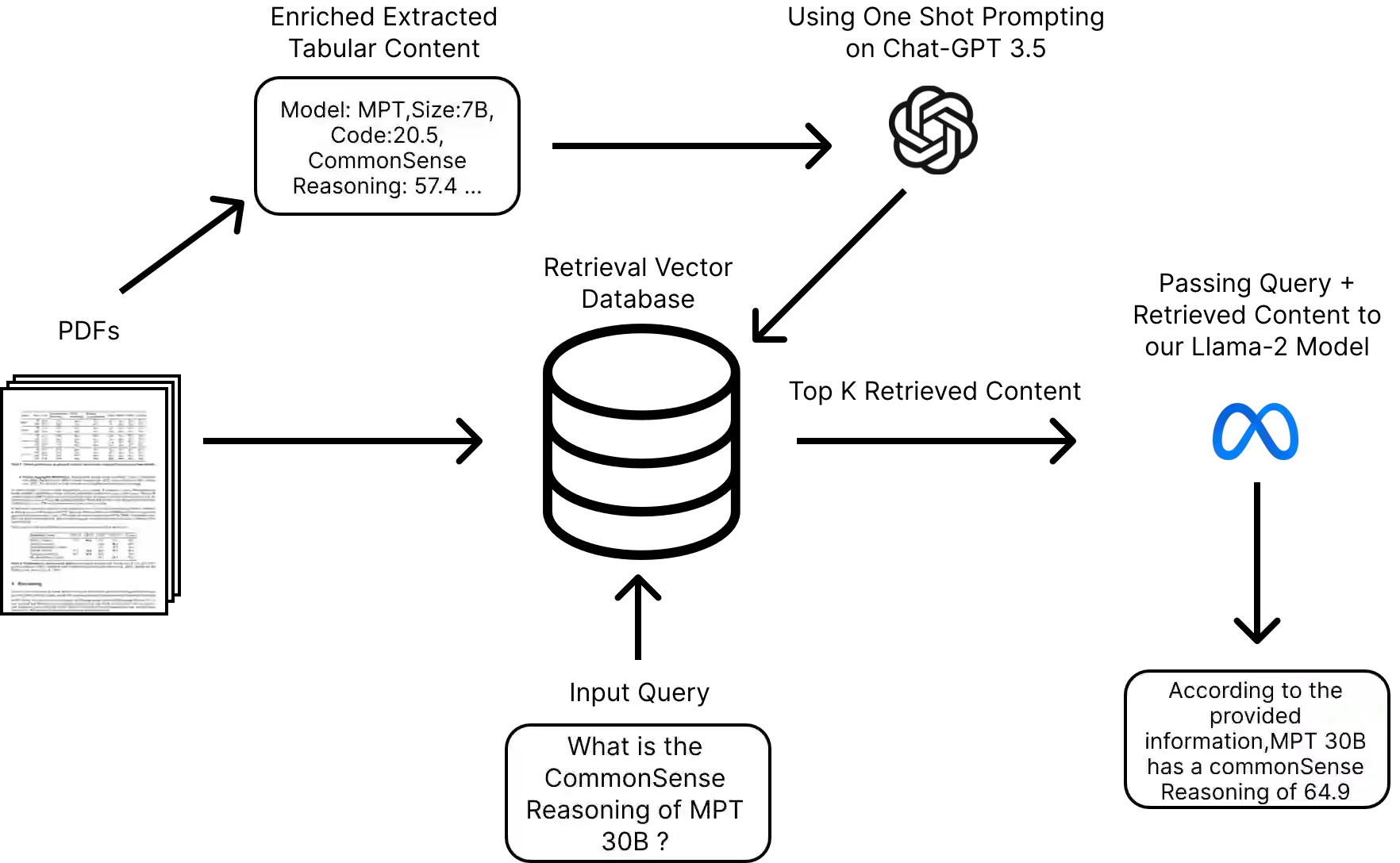
The conventional use of the Retrieval-Augmented Generation (RAG) architecture has proven effective for retrieving information from diverse documents. However, challenges arise in handling complex table queries, especially within PDF documents containing intricate tabular structures.This research introduces an innovative approach to enhance the accuracy of complex table queries in RAG-based systems. Our methodology involves storing PDFs in the retrieval database and extracting tabular content separately. The extracted tables undergo a process of context enrichment, concatenating headers with corresponding values. To ensure a comprehensive understanding of the enriched data, we employ a fine-tuned version of the Llama-2-chat language model for summarisation within the RAG architecture. Furthermore, we augment the tabular data with contextual sense using the ChatGPT 3.5 API through a one-shot prompt. This enriched data is then fed into the retrieval database alongside other PDFs. Our approach aims to significantly improve the precision of complex table queries, offering a promising solution to a longstanding challenge in information retrieval.
翻译:传统上,检索增强生成(RAG)架构被证明能有效从各类文档中获取信息。然而,在处理复杂表格查询时,尤其是涉及PDF文档中结构复杂的表格,仍存在挑战。本研究提出了一种创新方法,旨在提升基于RAG系统的复杂表格查询精度。我们的方法包括:将PDF文件存入检索数据库,并单独提取其中的表格内容。提取的表格经过上下文增强处理,将表头与对应数值进行拼接。为确保对增强数据的全面理解,我们在RAG架构中采用经过微调的Llama-2-chat语言模型进行摘要生成。此外,我们通过单样本提示,利用ChatGPT 3.5 API为表格数据赋予情境语义。这些增强后的数据被重新存入检索数据库,与其他PDF文件共同使用。该方法显著提升了复杂表格查询的精确度,为信息检索领域长期存在的难题提供了有前景的解决方案。