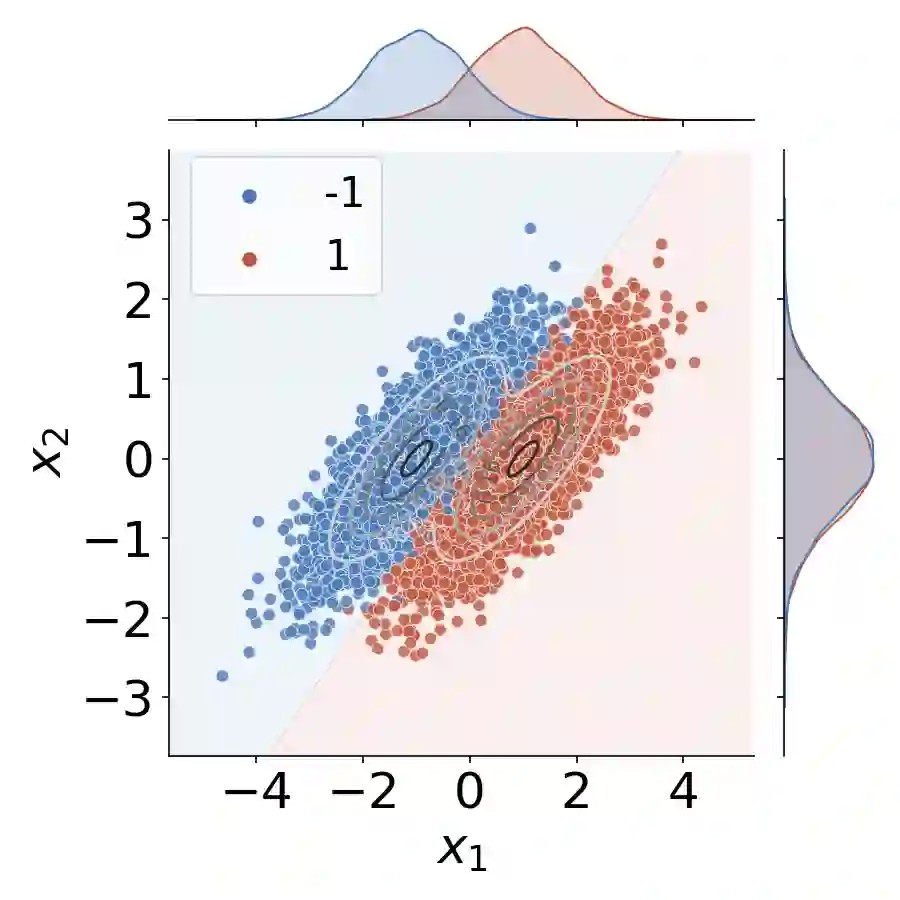
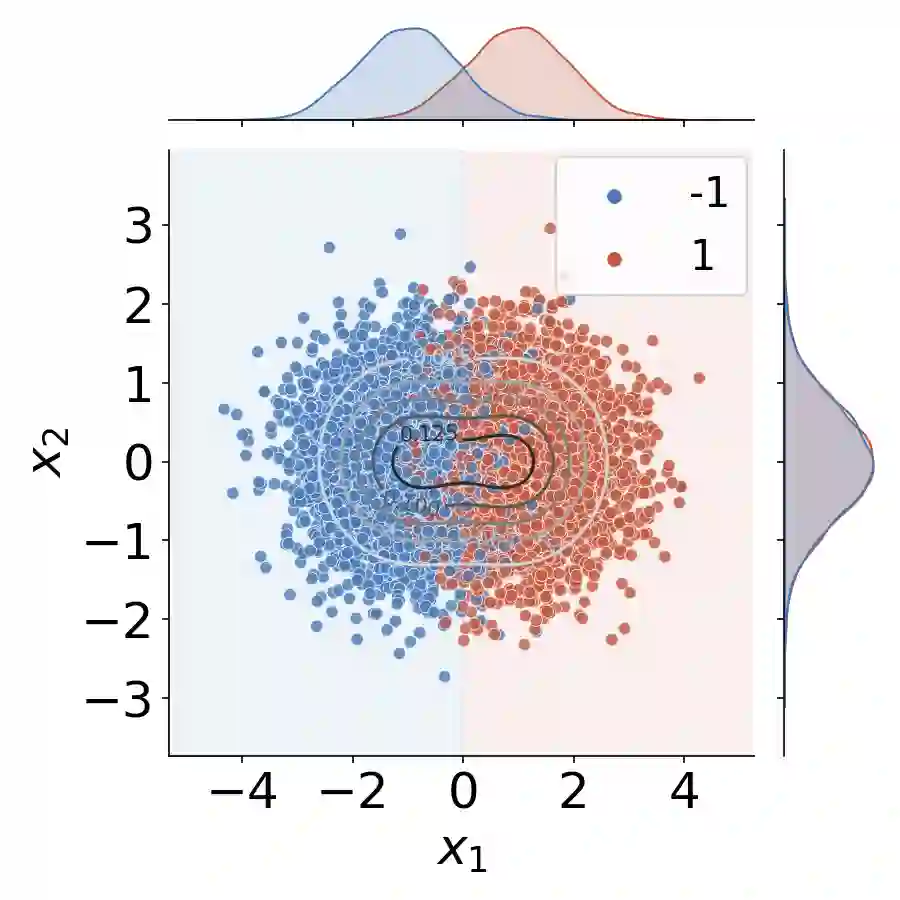
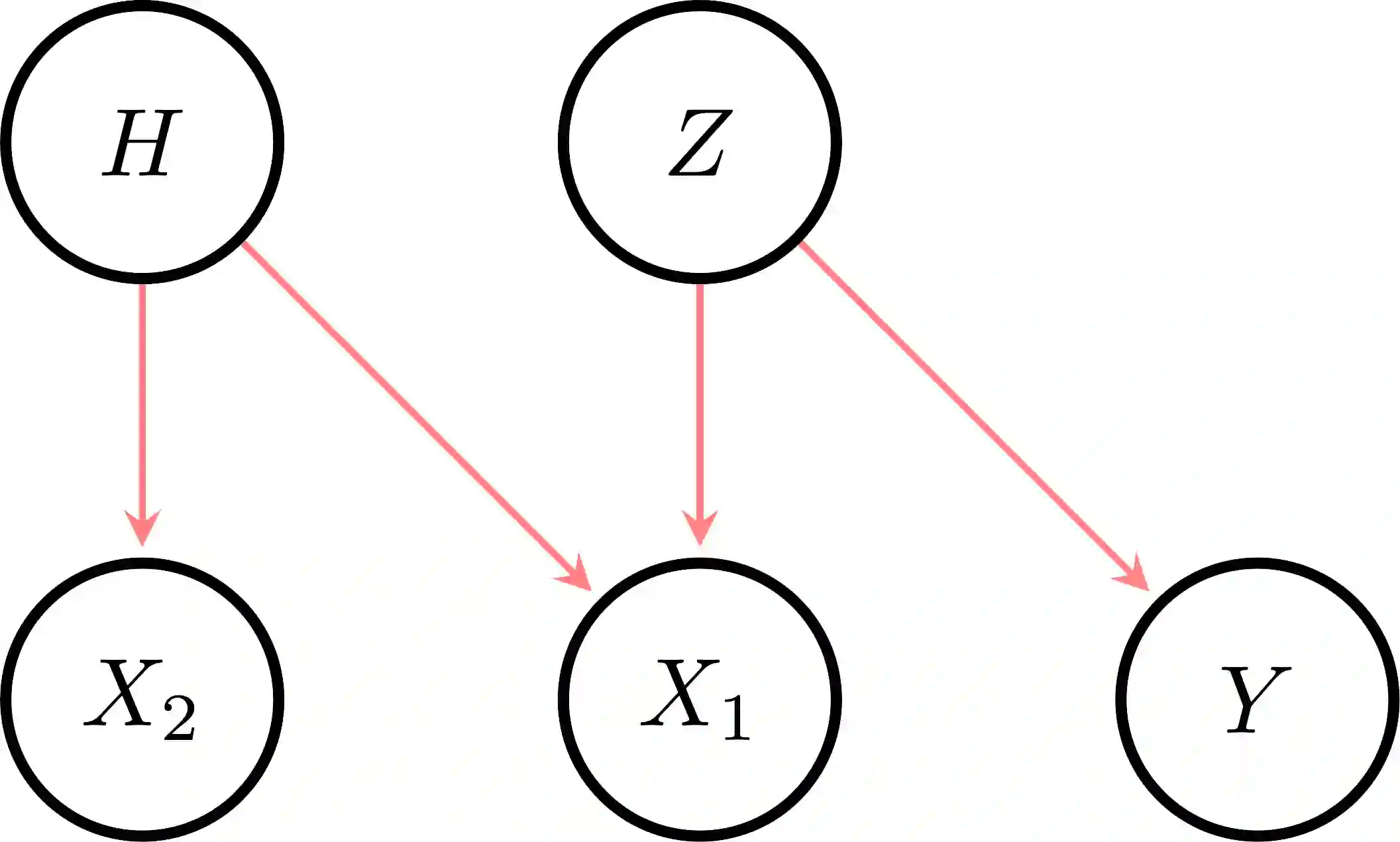
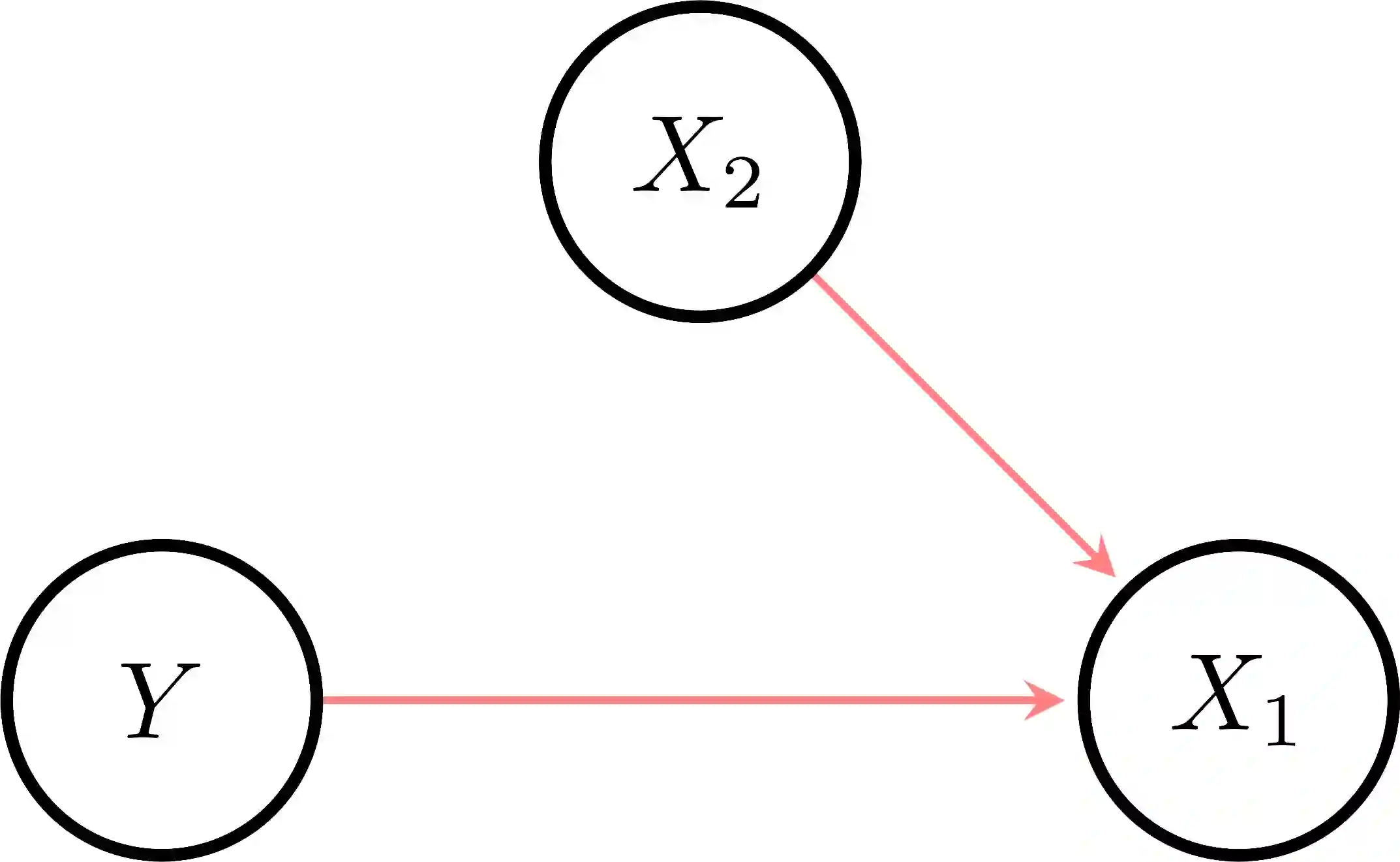
The use of machine learning (ML) in critical domains such as medicine poses risks and requires regulation. One requirement is that decisions of ML systems in high-risk applications should be human-understandable. The field of "explainable artificial intelligence" (XAI) seemingly addresses this need. However, in its current form, XAI is unfit to provide quality control for ML; it itself needs scrutiny. Popular XAI methods cannot reliably answer important questions about ML models, their training data, or a given test input. We recapitulate results demonstrating that popular XAI methods systematically attribute importance to input features that are independent of the prediction target. This limits their utility for purposes such as model and data (in)validation, model improvement, and scientific discovery. We argue that the fundamental reason for this limitation is that current XAI methods do not address well-defined problems and are not evaluated against objective criteria of explanation correctness. Researchers should formally define the problems they intend to solve first and then design methods accordingly. This will lead to notions of explanation correctness that can be theoretically verified and objective metrics of explanation performance that can be assessed using ground-truth data.
翻译:在医学等关键领域应用机器学习(ML)存在风险且需要监管。一项核心要求是高风险应用中的ML系统决策应具备人类可理解性。"可解释人工智能"(XAI)领域看似能满足这一需求。然而,当前形态的XAI并不适合为ML提供质量控制;其自身也需要接受严格审查。流行的XAI方法无法可靠回答关于ML模型、训练数据或特定测试输入的关键问题。我们通过研究结果证明,主流XAI方法会系统性地将重要性归因于与预测目标无关的输入特征,这限制了其在模型与数据(无效)验证、模型改进及科学发现等场景的实用性。我们认为根本原因在于现有XAI方法既未针对明确定义的问题,也缺乏基于解释正确性客观标准的评估机制。研究者应当首先形式化定义待解决的问题,再据此设计方法。这将催生可通过理论验证的解释正确性概念,以及能借助真实数据评估解释性能的客观度量标准。