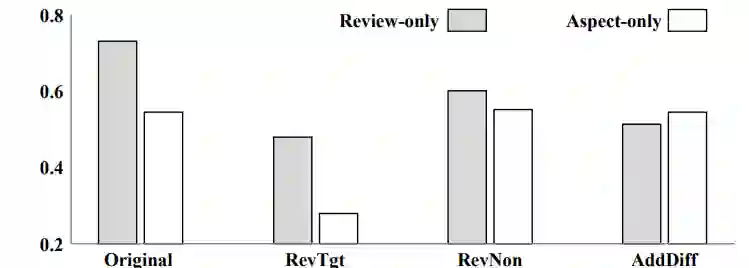
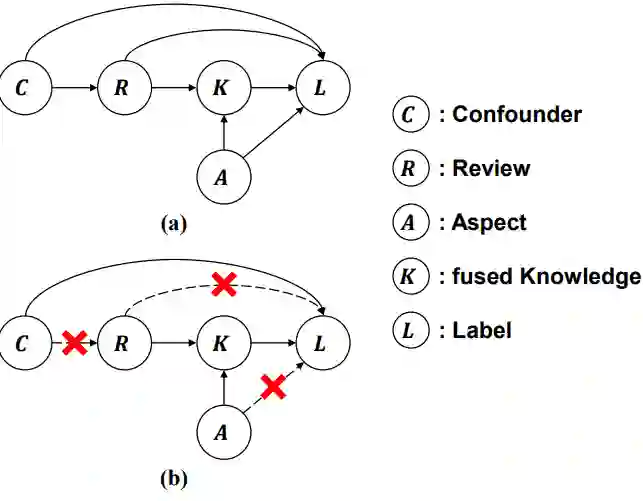
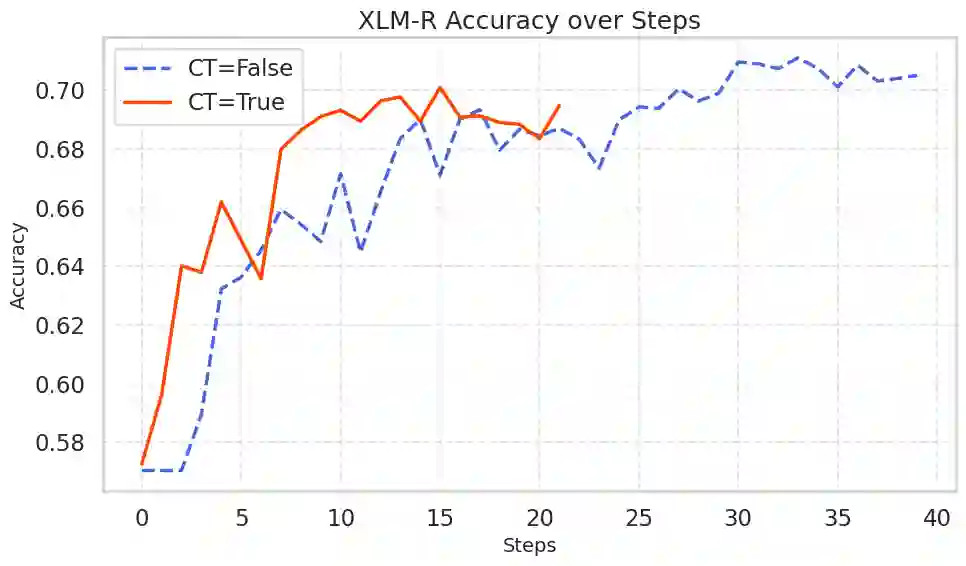
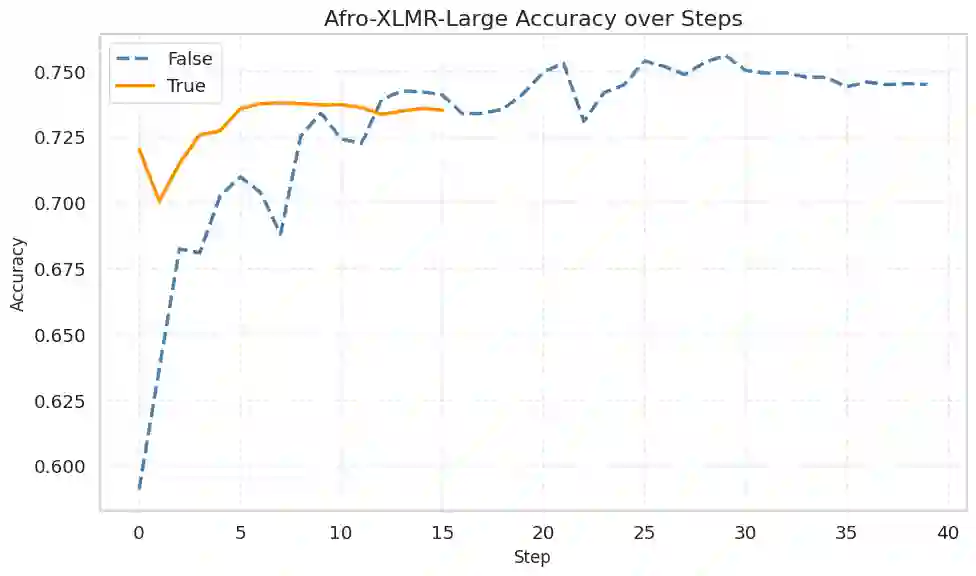
Machine learning models typically assume that training and test data follow the same distribution, an assumption that often fails in real-world scenarios due to distribution shifts. This issue is especially pronounced in low-resource settings, where data scarcity and limited domain diversity hinder robust generalization. Domain generalization (DG) approaches address this challenge by learning features that remain invariant across domains, often using causal mechanisms to improve model robustness. In this study, we examine two distinct causal DG techniques in low-resource natural language tasks. First, we investigate a causal data augmentation (CDA) approach that automatically generates counterfactual examples to improve robustness to spurious correlations. We apply this method to sentiment classification on the NaijaSenti Twitter corpus, expanding the training data with semantically equivalent paraphrases to simulate controlled distribution shifts. Second, we explore an invariant causal representation learning (ICRL) approach using the DINER framework, originally proposed for debiasing aspect-based sentiment analysis. We adapt DINER to a multilingual setting. Our findings demonstrate that both approaches enhance robustness to unseen domains: counterfactual data augmentation yields consistent cross-domain accuracy gains in sentiment classification, while causal representation learning with DINER improves out-of-distribution performance in multilingual sentiment analysis, albeit with varying gains across languages.
翻译:机器学习模型通常假设训练数据与测试数据遵循相同分布,这一假设在现实场景中常因分布偏移而失效。该问题在低资源环境中尤为突出,数据稀缺与领域多样性有限阻碍了模型的鲁棒泛化能力。领域泛化方法通过学习跨领域保持不变的特性(常借助因果机制提升模型鲁棒性)应对这一挑战。本研究在低资源自然语言任务中检验了两种不同的因果领域泛化技术。首先,我们探究了一种因果数据增强方法,该方法通过自动生成反事实样本来提升对伪相关性的鲁棒性。我们将此方法应用于NaijaSenti Twitter语料库的情感分类任务,通过添加语义等效的复述句扩展训练数据,以模拟受控的分布偏移。其次,我们探索了基于DINER框架的不变因果表示学习方法(该方法最初用于消除基于方面的情感分析偏差),并将其适配至多语言场景。研究结果表明,两种方法均能增强对未见领域的鲁棒性:反事实数据增强在情感分类中实现了稳定的跨领域准确率提升,而基于DINER的因果表示学习则改善了多语言情感分析中的分布外性能,尽管不同语言间的增益存在差异。