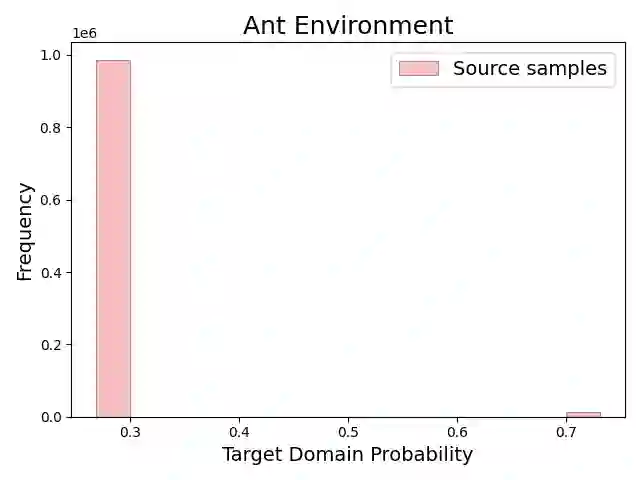
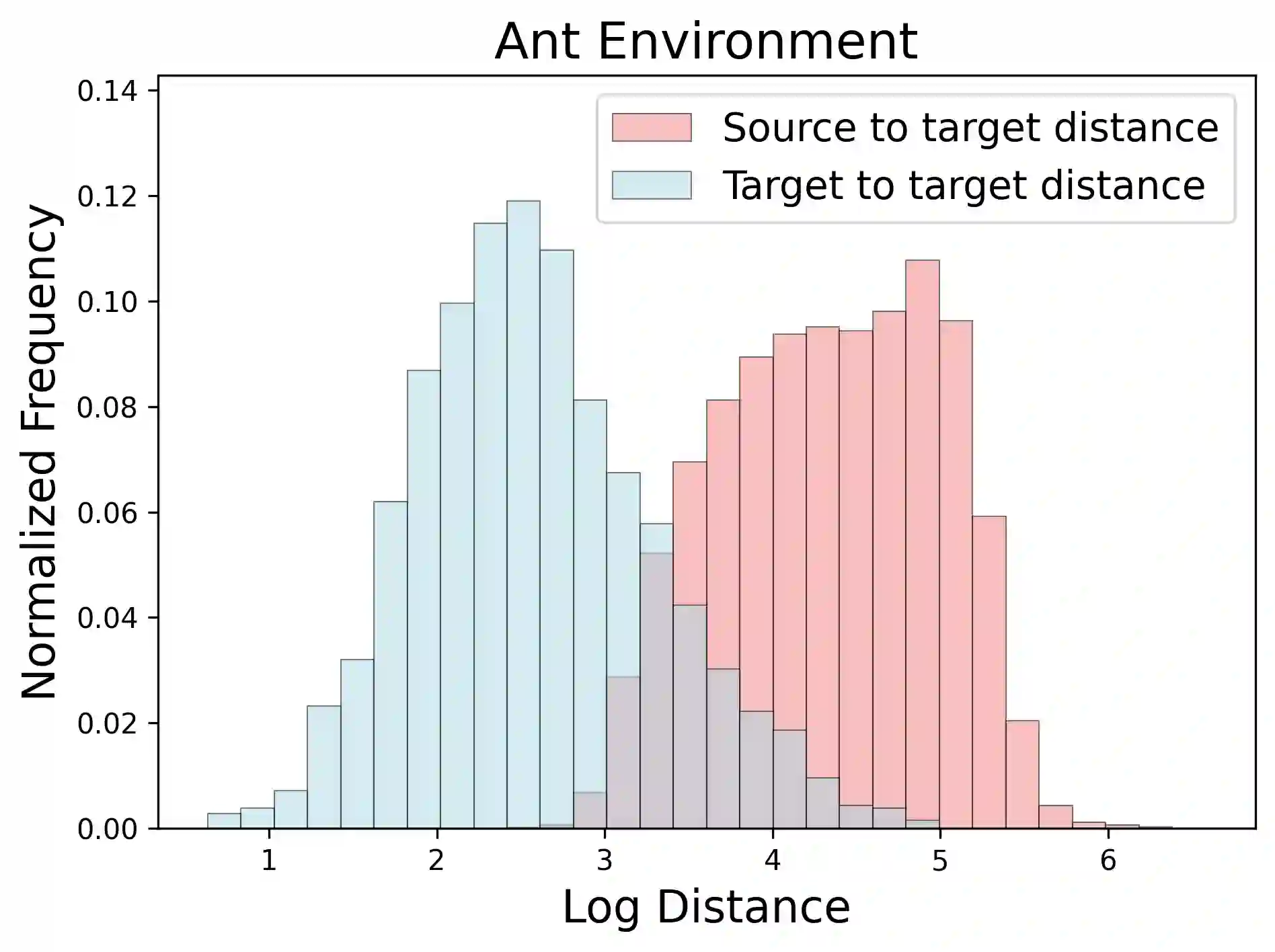
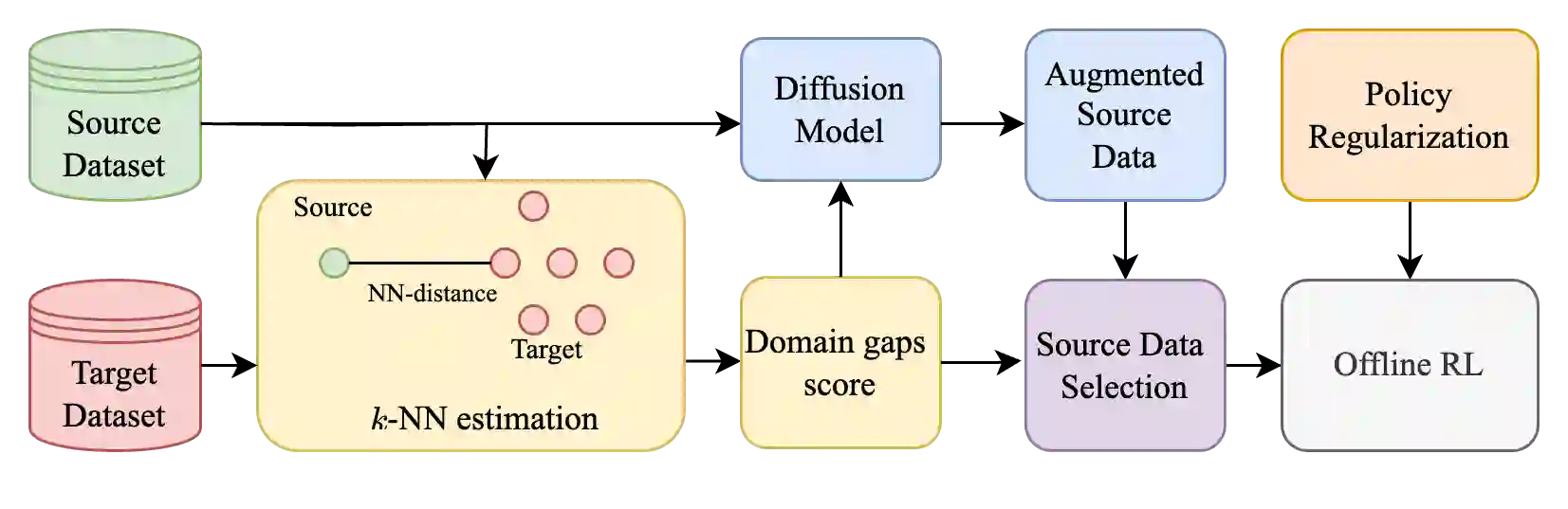
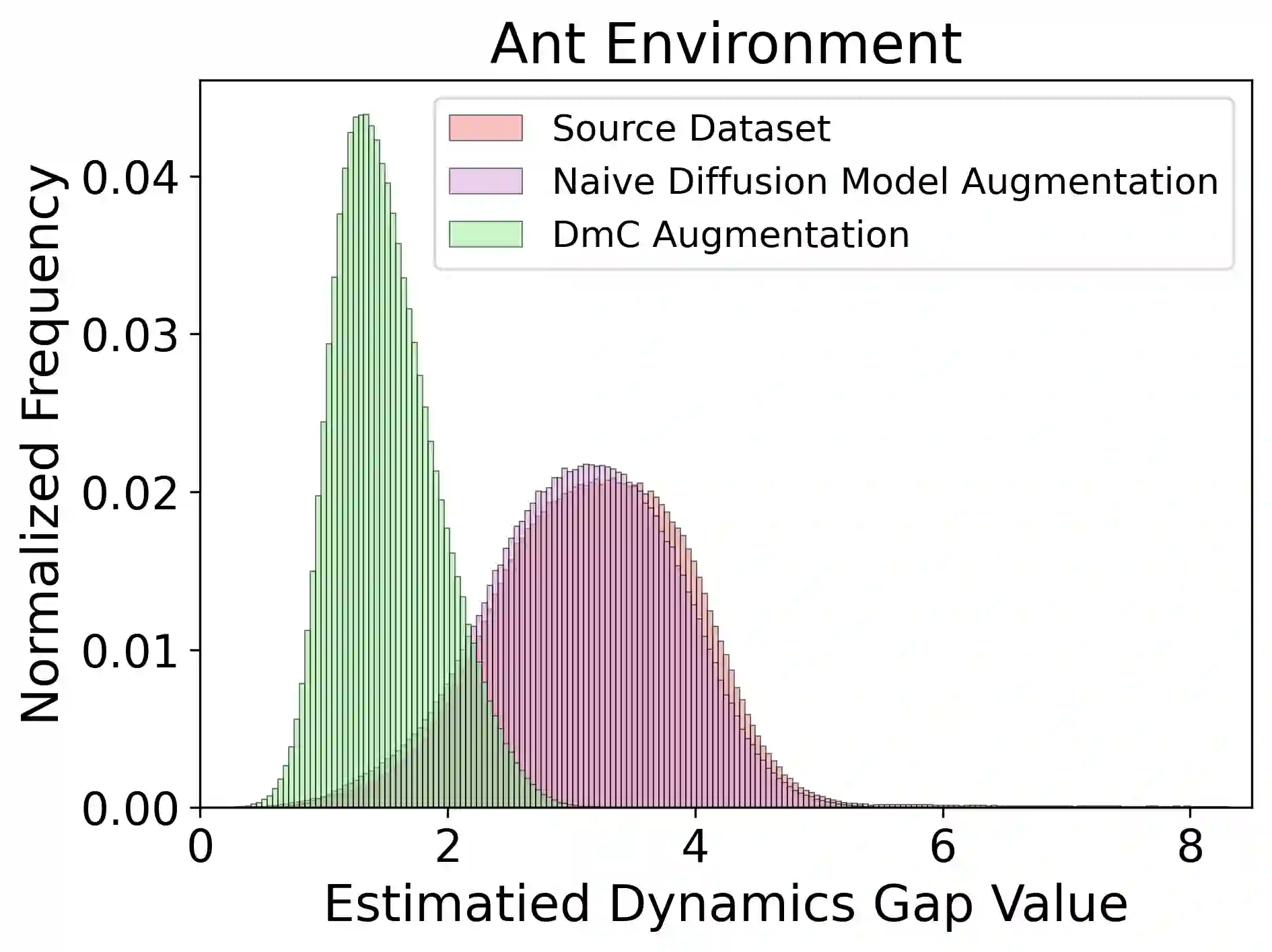
Cross-domain offline reinforcement learning (RL) seeks to enhance sample efficiency in offline RL by utilizing additional offline source datasets. A key challenge is to identify and utilize source samples that are most relevant to the target domain. Existing approaches address this challenge by measuring domain gaps through domain classifiers, target transition dynamics modeling, or mutual information estimation using contrastive loss. However, these methods often require large target datasets, which is impractical in many real-world scenarios. In this work, we address cross-domain offline RL under a limited target data setting, identifying two primary challenges: (1) Dataset imbalance, which is caused by large source and small target datasets and leads to overfitting in neural network-based domain gap estimators, resulting in uninformative measurements; and (2) Partial domain overlap, where only a subset of the source data is closely aligned with the target domain. To overcome these issues, we propose DmC, a novel framework for cross-domain offline RL with limited target samples. Specifically, DmC utilizes $k$-nearest neighbor ($k$-NN) based estimation to measure domain proximity without neural network training, effectively mitigating overfitting. Then, by utilizing this domain proximity, we introduce a nearest-neighbor-guided diffusion model to generate additional source samples that are better aligned with the target domain, thus enhancing policy learning with more effective source samples. Through theoretical analysis and extensive experiments in diverse MuJoCo environments, we demonstrate that DmC significantly outperforms state-of-the-art cross-domain offline RL methods, achieving substantial performance gains.
翻译:跨域离线强化学习旨在利用额外的离线源数据集提升离线强化学习的样本效率。其核心挑战在于识别并利用与目标域最相关的源样本。现有方法通常通过域分类器、目标转移动态建模或基于对比损失的互信息估计来衡量域间差异。然而,这些方法往往需要大规模目标数据集,这在许多实际场景中难以满足。本文针对目标数据受限场景下的跨域离线强化学习问题,识别出两大主要挑战:(1)数据集不平衡——源数据集大而目标数据集小,导致基于神经网络的域差异估计器容易过拟合,从而产生无意义的度量结果;(2)部分域重叠——仅部分源数据与目标域高度相关。为克服这些问题,我们提出DmC,一种面向有限目标样本的跨域离线强化学习新框架。具体而言,DmC采用基于$k$最近邻的估计方法衡量域间邻近度,无需训练神经网络,有效缓解了过拟合问题。进而利用该域邻近度信息,我们提出最近邻引导的扩散模型,生成与目标域更匹配的增强源样本,从而通过更有效的源样本提升策略学习效果。通过在多样化MuJoCo环境中的理论分析与大量实验,我们证明DmC显著优于当前最先进的跨域离线强化学习方法,取得了实质性的性能提升。