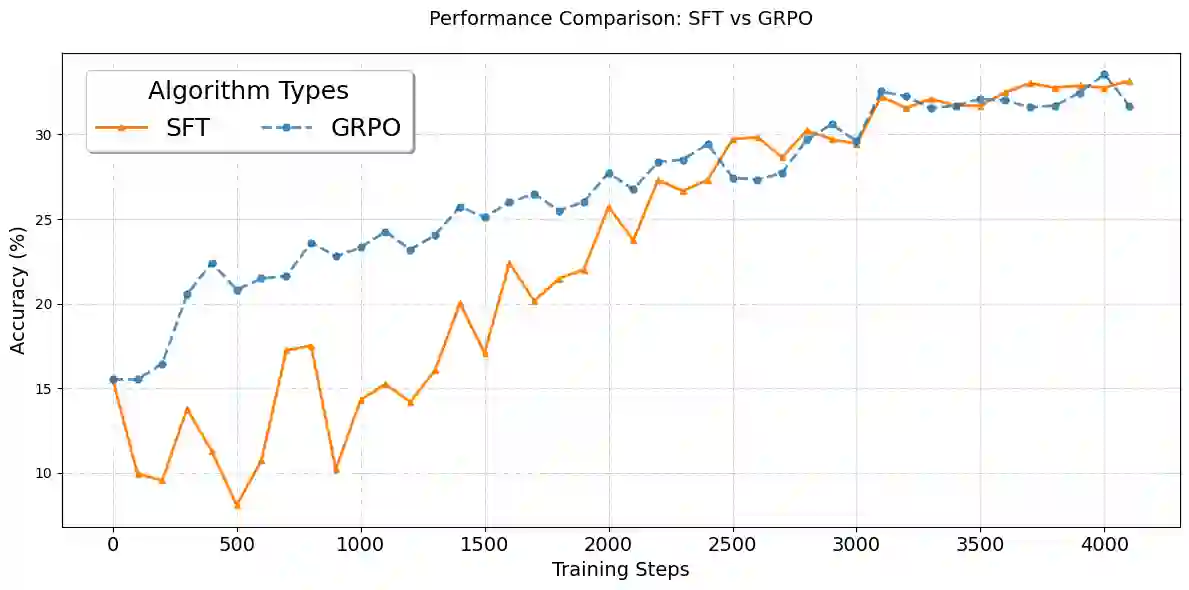
Multimodal Large Language Models (MLLMs) have gained significant traction for their ability to process diverse input data types and generate coherent, contextually relevant outputs across various applications. While supervised fine-tuning (SFT) has been the predominant approach to enhance MLLM capabilities in task-specific optimization, it often falls short in fostering crucial generalized reasoning abilities. Although reinforcement learning (RL) holds great promise in overcoming these limitations, it encounters two significant challenges: (1) its generalized capacities in multimodal tasks remain largely unexplored, and (2) its training constraints, including the constant Kullback-Leibler divergence or the clamp strategy, often result in suboptimal bottlenecks. To address these challenges, we propose OThink-MR1, an advanced MLLM equipped with profound comprehension and reasoning capabilities across multimodal tasks. Specifically, we introduce Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D), which markedly enhances reinforcement learning (RL) performance. For Qwen2-VL-2B-Instruct, GRPO-D achieves a relative improvement of more than 5.72% over SFT and more than 13.59% over GRPO in same-task evaluation on two adapted datasets. Furthermore, GRPO-D demonstrates remarkable cross-task generalization capabilities, with an average relative improvement of more than 61.63% over SFT in cross-task evaluation. These results highlight that the MLLM trained with GRPO-D on one multimodal task can be effectively transferred to another task, underscoring the superior generalized reasoning capabilities of our proposed OThink-MR1 model.
翻译:多模态大语言模型(MLLMs)因其能够处理多样化的输入数据类型,并在各类应用中生成连贯且上下文相关的输出而受到广泛关注。虽然监督微调(SFT)一直是增强MLLM在任务特定优化方面能力的主要方法,但它在培养关键的广义推理能力方面往往存在不足。尽管强化学习(RL)在克服这些局限方面展现出巨大潜力,但它面临两大挑战:(1)其在多模态任务中的广义能力在很大程度上尚未得到探索;(2)其训练约束,包括恒定的Kullback-Leibler散度或裁剪策略,常常导致次优瓶颈。为解决这些挑战,我们提出了OThink-MR1,这是一个具备跨多模态任务深刻理解与推理能力的高级MLLM。具体而言,我们引入了具有动态Kullback-Leibler策略的组相对策略优化方法(GRPO-D),该方法显著提升了强化学习(RL)的性能。对于Qwen2-VL-2B-Instruct模型,在两个适配数据集上的同任务评估中,GRPO-D相比SFT实现了超过5.72%的相对提升,相比GRPO实现了超过13.59%的相对提升。此外,GRPO-D展现出卓越的跨任务泛化能力,在跨任务评估中相比SFT平均相对提升超过61.63%。这些结果表明,使用GRPO-D在一个多模态任务上训练的MLLM能够有效地迁移到另一任务,凸显了我们提出的OThink-MR1模型在广义推理能力方面的优越性。