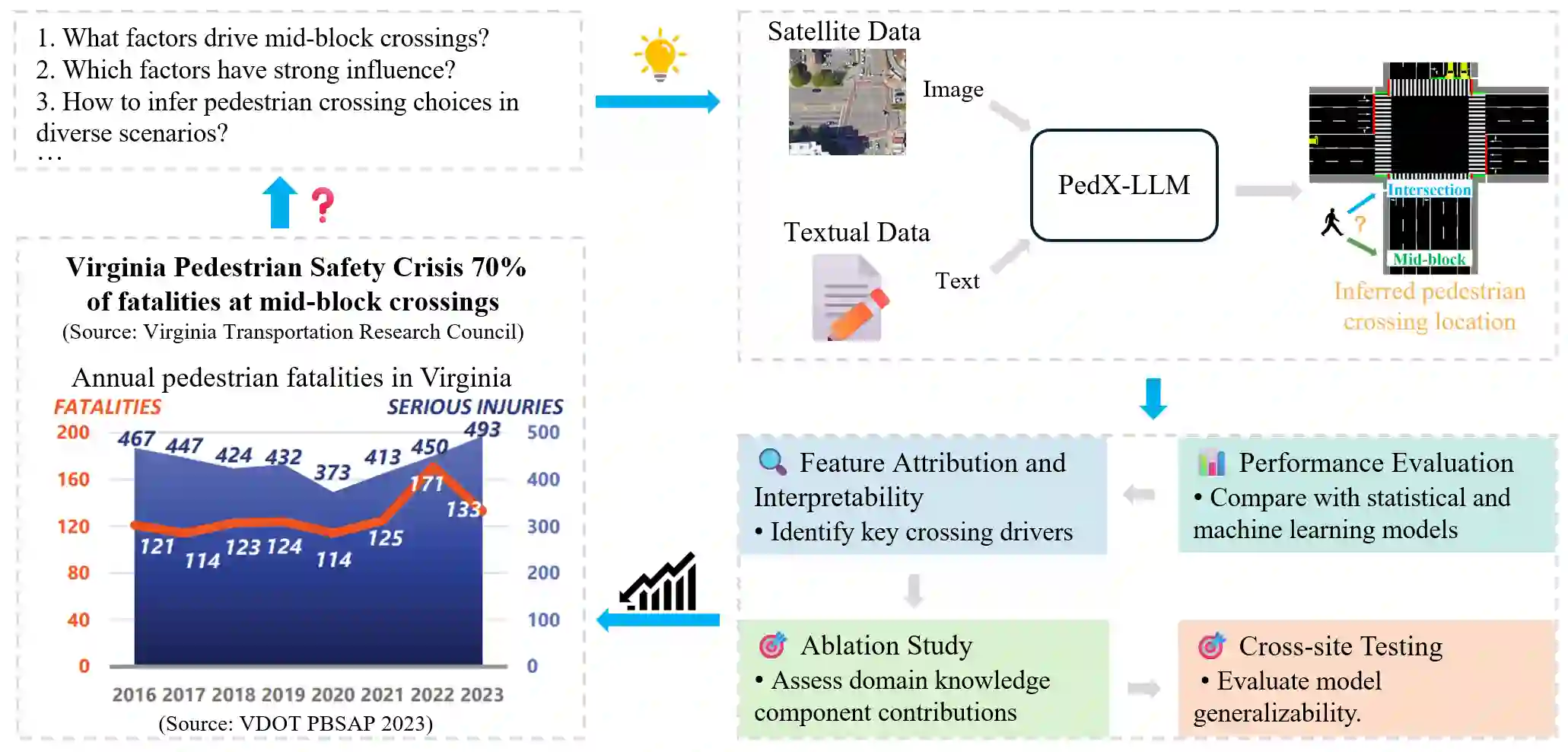
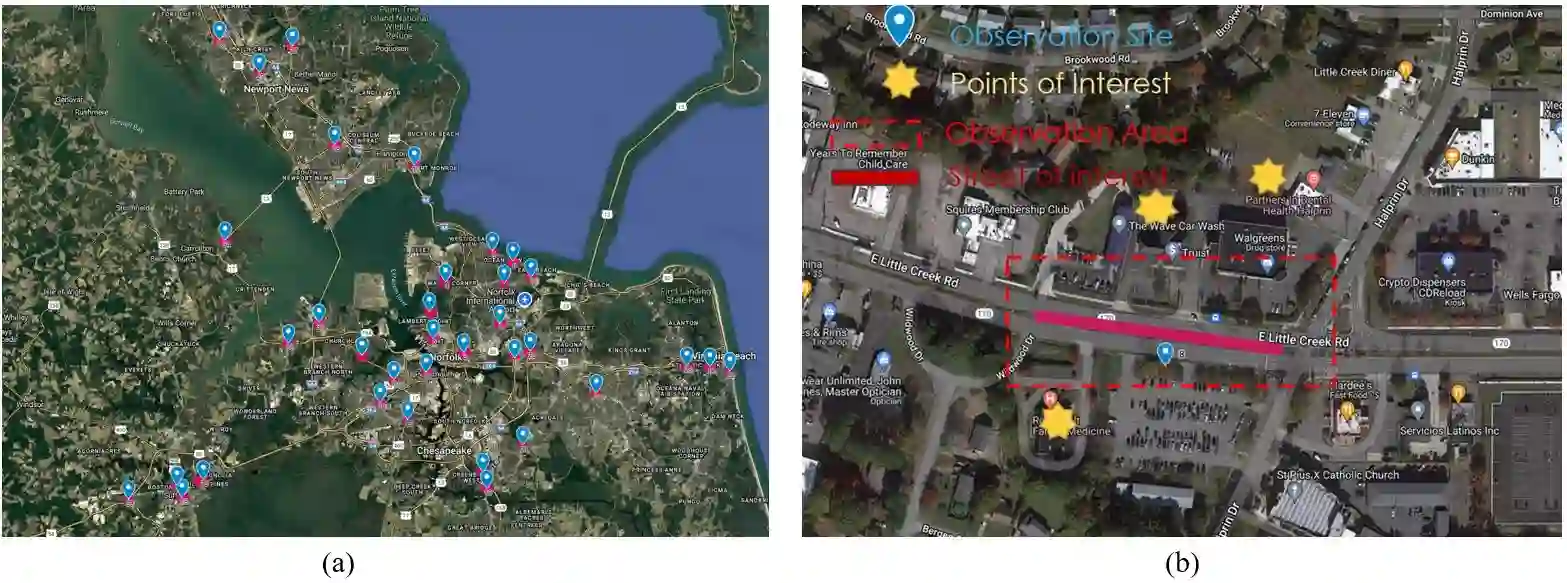
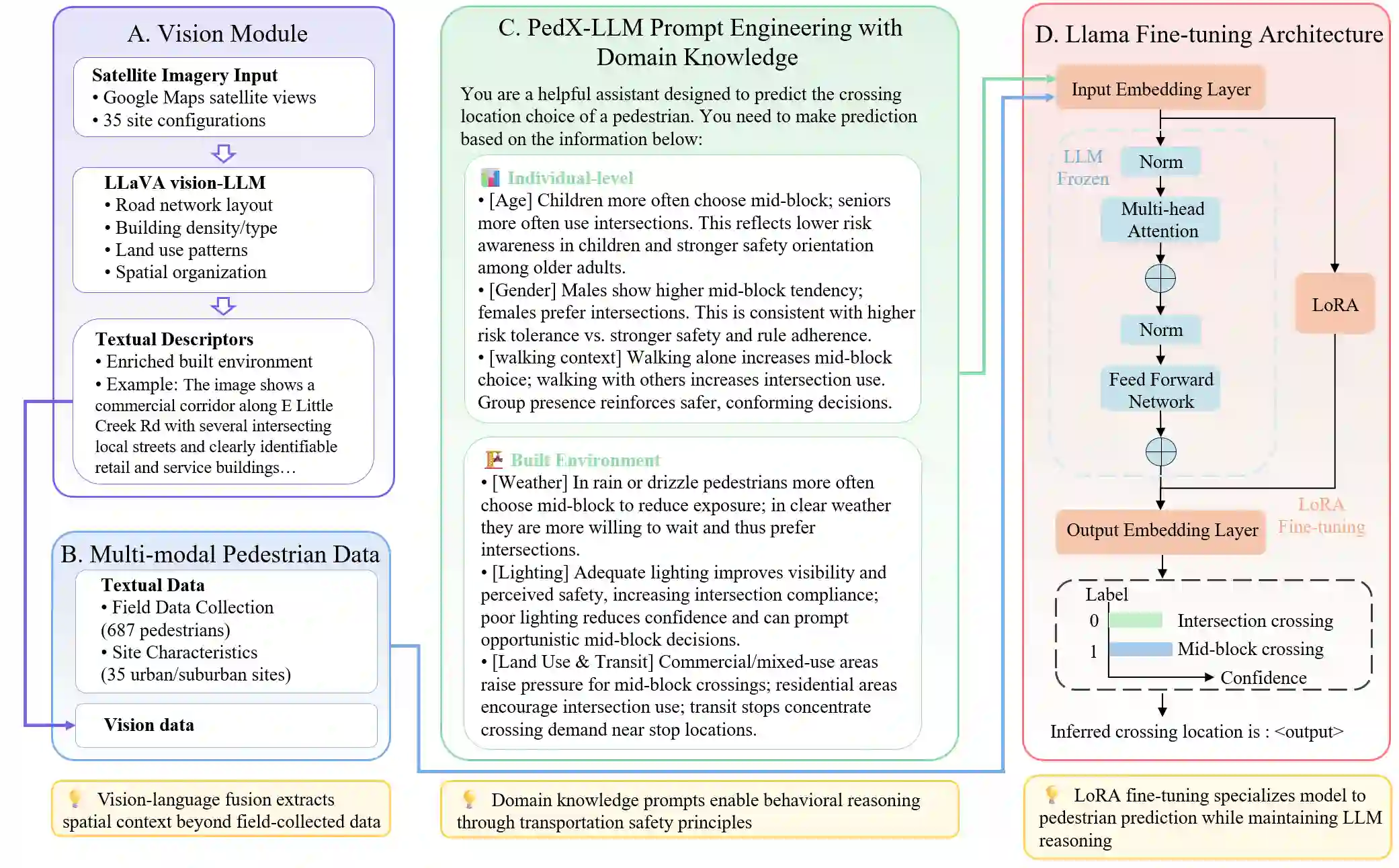
Existing paradigms for inferring pedestrian crossing behavior, ranging from statistical models to supervised learning methods, demonstrate limited generalizability and perform inadequately on new sites. Recent advances in Large Language Models (LLMs) offer a shift from numerical pattern fitting to semantic, context-aware behavioral reasoning, yet existing LLM applications lack domain-specific adaptation and visual context. This study introduces Pedestrian Crossing LLM (PedX-LLM), a vision-and-knowledge enhanced framework designed to transform pedestrian crossing inference from site-specific pattern recognition to generalizable behavioral reasoning. By integrating LLaVA-extracted visual features with textual data and transportation domain knowledge, PedX-LLM fine-tunes a LLaMA-2-7B foundation model via Low-Rank Adaptation (LoRA) to infer crossing decisions. PedX-LLM achieves 82.0% balanced accuracy, outperforming the best statistical and supervised learning methods. Results demonstrate that the vision-augmented module contributes a 2.9% performance gain by capturing the built environment and integrating domain knowledge yields an additional 4.1% improvement. To evaluate generalizability across unseen environments, cross-site validation was conducted using site-based partitioning. The zero-shot PedX-LLM configuration achieves 66.9% balanced accuracy on five unseen test sites, outperforming the baseline data-driven methods by at least 18 percentage points. Incorporating just five validation examples via few-shot learning to PedX-LLM further elevates the balanced accuracy to 72.2%. PedX-LLM demonstrates strong generalizability to unseen scenarios, confirming that vision-and-knowledge-enhanced reasoning enables the model to mimic human-like decision logic and overcome the limitations of purely data-driven methods.
翻译:现有行人过街行为推理范式,从统计模型到监督学习方法,均表现出有限的泛化能力,在新场景中表现不佳。大型语言模型(LLMs)的最新进展提供了从数值模式拟合到语义化、上下文感知行为推理的转变,然而现有的LLM应用缺乏领域适应性及视觉上下文。本研究提出行人过街大型语言模型(PedX-LLM),这是一个视觉与知识增强的框架,旨在将行人过街推理从特定场景的模式识别转变为可泛化的行为推理。通过整合LLaVA提取的视觉特征与文本数据及交通领域知识,PedX-LLM通过低秩自适应(LoRA)微调LLaMA-2-7B基础模型,以推断过街决策。PedX-LLM实现了82.0%的平衡准确率,优于最佳的统计与监督学习方法。结果表明,视觉增强模块通过捕捉建成环境特征贡献了2.9%的性能提升,而整合领域知识则带来了额外的4.1%改进。为评估模型在未见环境中的泛化能力,采用基于场景划分的跨场景验证方法。零样本配置的PedX-LLM在五个未见测试场景上达到66.9%的平衡准确率,较基线数据驱动方法至少高出18个百分点。通过少量样本学习,仅向PedX-LLM引入五个验证样本即可将平衡准确率进一步提升至72.2%。PedX-LLM展现出对未见场景的强泛化能力,证实了视觉与知识增强的推理使模型能够模拟类人决策逻辑,并克服纯数据驱动方法的局限性。