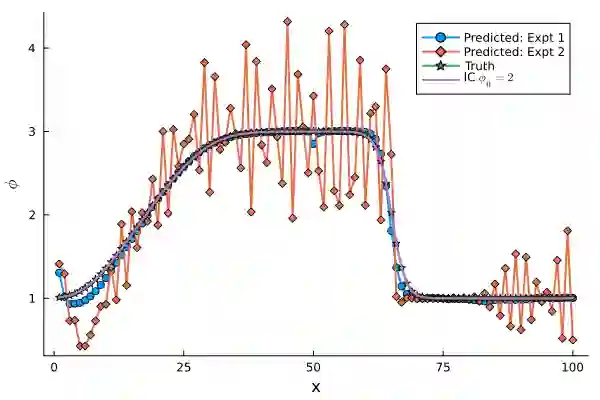
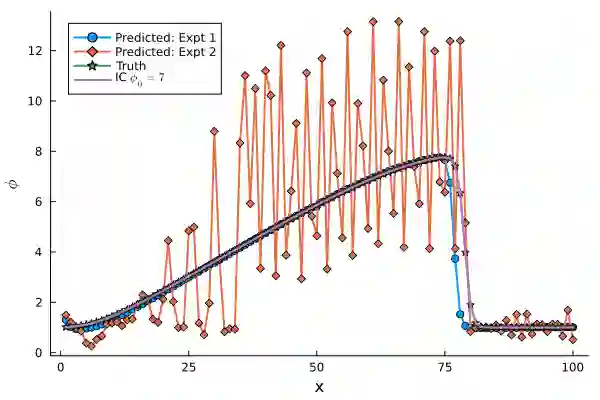
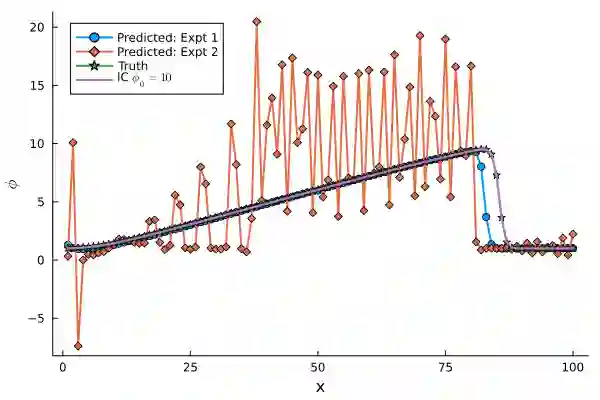
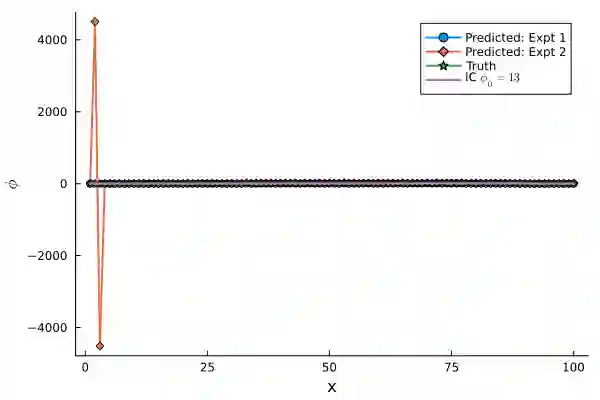
Differentiable Programming for scientific machine learning (SciML) has recently seen considerable interest and success, as it directly embeds neural networks inside PDEs, often called as NeuralPDEs, derived from first principle physics. Therefore, there is a widespread assumption in the community that NeuralPDEs are more trustworthy and generalizable than black box models. However, like any SciML model, differentiable programming relies predominantly on high-quality PDE simulations as "ground truth" for training. However, mathematics dictates that these are only discrete numerical approximations of the true physics. Therefore, we ask: Are NeuralPDEs and differentiable programming models trained on PDE simulations as physically interpretable as we think? In this work, we rigorously attempt to answer these questions, using established ideas from numerical analysis, experiments, and analysis of model Jacobians. Our study shows that NeuralPDEs learn the artifacts in the simulation training data arising from the discretized Taylor Series truncation error of the spatial derivatives. Additionally, NeuralPDE models are systematically biased, and their generalization capability is likely enabled by a fortuitous interplay of numerical dissipation and truncation error in the training dataset and NeuralPDE, which seldom happens in practical applications. This bias manifests aggressively even in relatively accessible 1-D equations, raising concerns about the veracity of differentiable programming on complex, high-dimensional, real-world PDEs, and in dataset integrity of foundation models. Further, we observe that the initial condition constrains the truncation error in initial-value problems in PDEs, thereby exerting limitations to extrapolation. Finally, we demonstrate that an eigenanalysis of model weights can indicate a priori if the model will be inaccurate for out-of-distribution testing.
翻译:科学机器学习中的可微分编程近期受到广泛关注并取得显著成功,其将神经网络直接嵌入从第一性原理物理推导出的偏微分方程中,常被称为神经偏微分方程。因此,学界普遍认为神经偏微分方程比黑箱模型更可信且更具泛化能力。然而,与任何科学机器学习模型一样,可微分编程主要依赖高质量的偏微分方程模拟作为训练的“真实数据”。但数学原理表明,这些模拟仅是真实物理过程的离散数值近似。因此,我们提出疑问:基于偏微分方程模拟训练的神经偏微分方程和可微分编程模型是否如我们所想的那般具有物理可解释性?本研究通过数值分析中的成熟理论、实验以及模型雅可比矩阵分析,系统性地尝试回答这些问题。我们的研究表明,神经偏微分方程会学习模拟训练数据中由空间导数离散化泰勒级数截断误差产生的伪影。此外,神经偏微分模型存在系统性偏差,其泛化能力可能源于训练数据集与神经偏微分方程中数值耗散和截断误差的偶然性相互作用,而这种情形在实际应用中鲜少发生。这种偏差甚至在相对简单的1维方程中也会显著显现,引发了对可微分编程在复杂高维现实世界偏微分方程中的有效性、以及基础模型数据集完整性的担忧。进一步地,我们观察到在偏微分方程的初值问题中,初始条件会约束截断误差,从而限制外推能力。最后,我们证明通过对模型权重进行特征分析,可以预先判断模型在分布外测试中是否会出现不准确的情况。