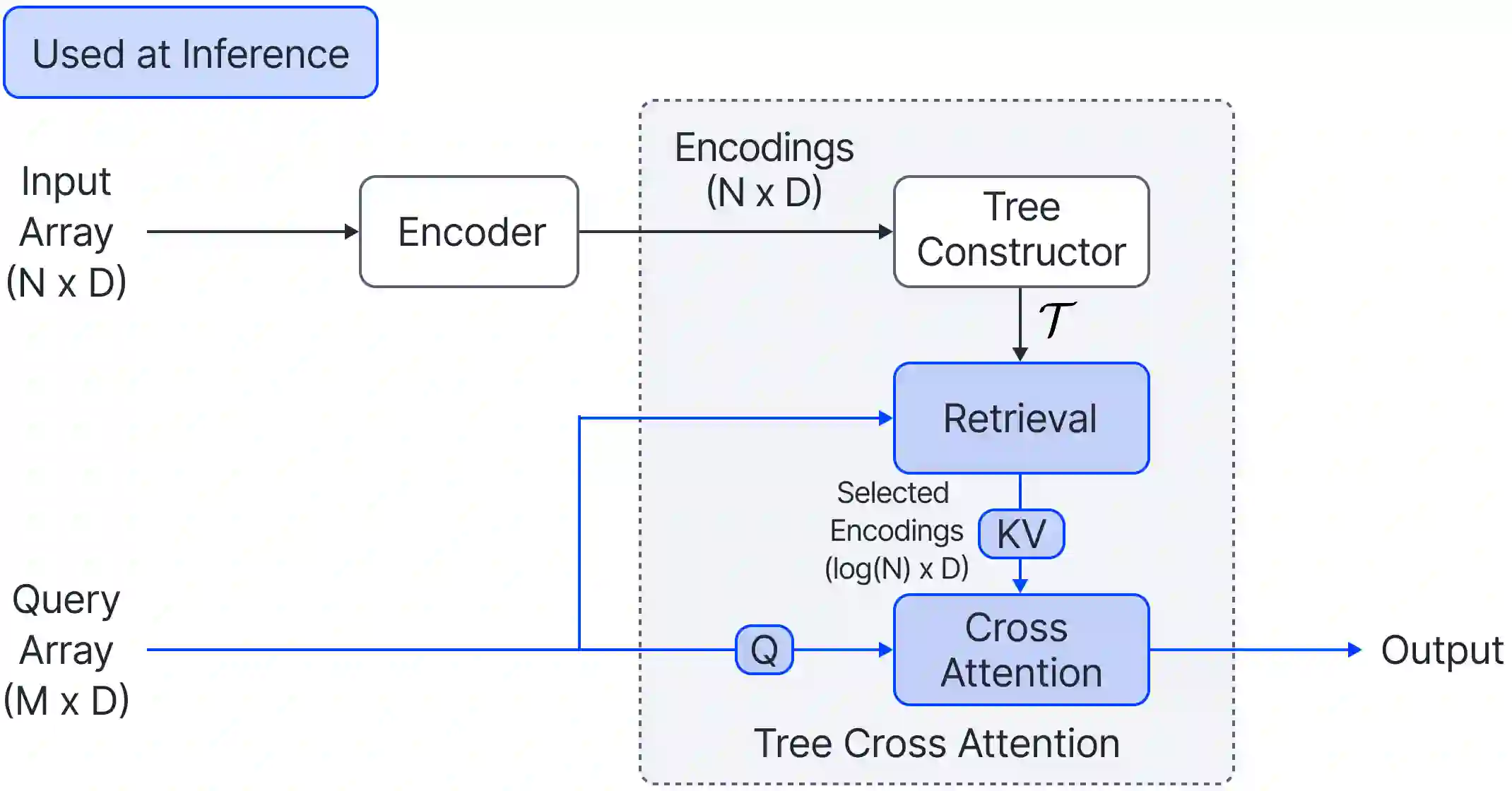
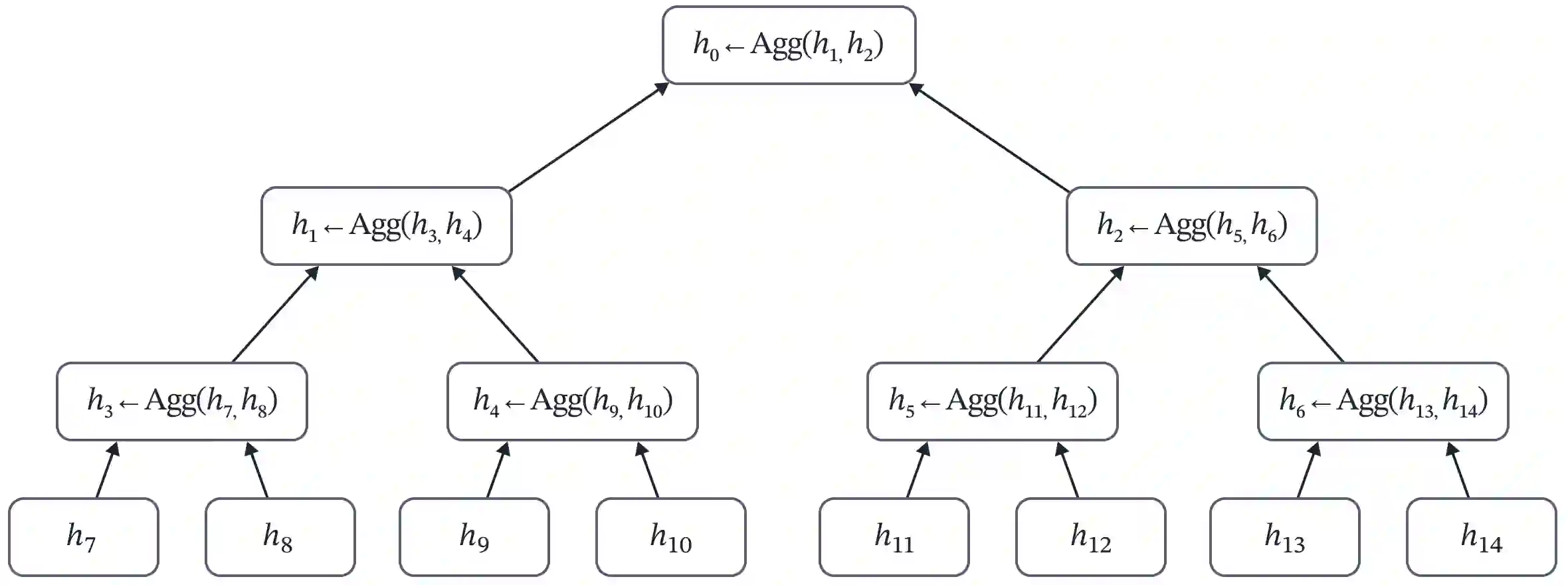
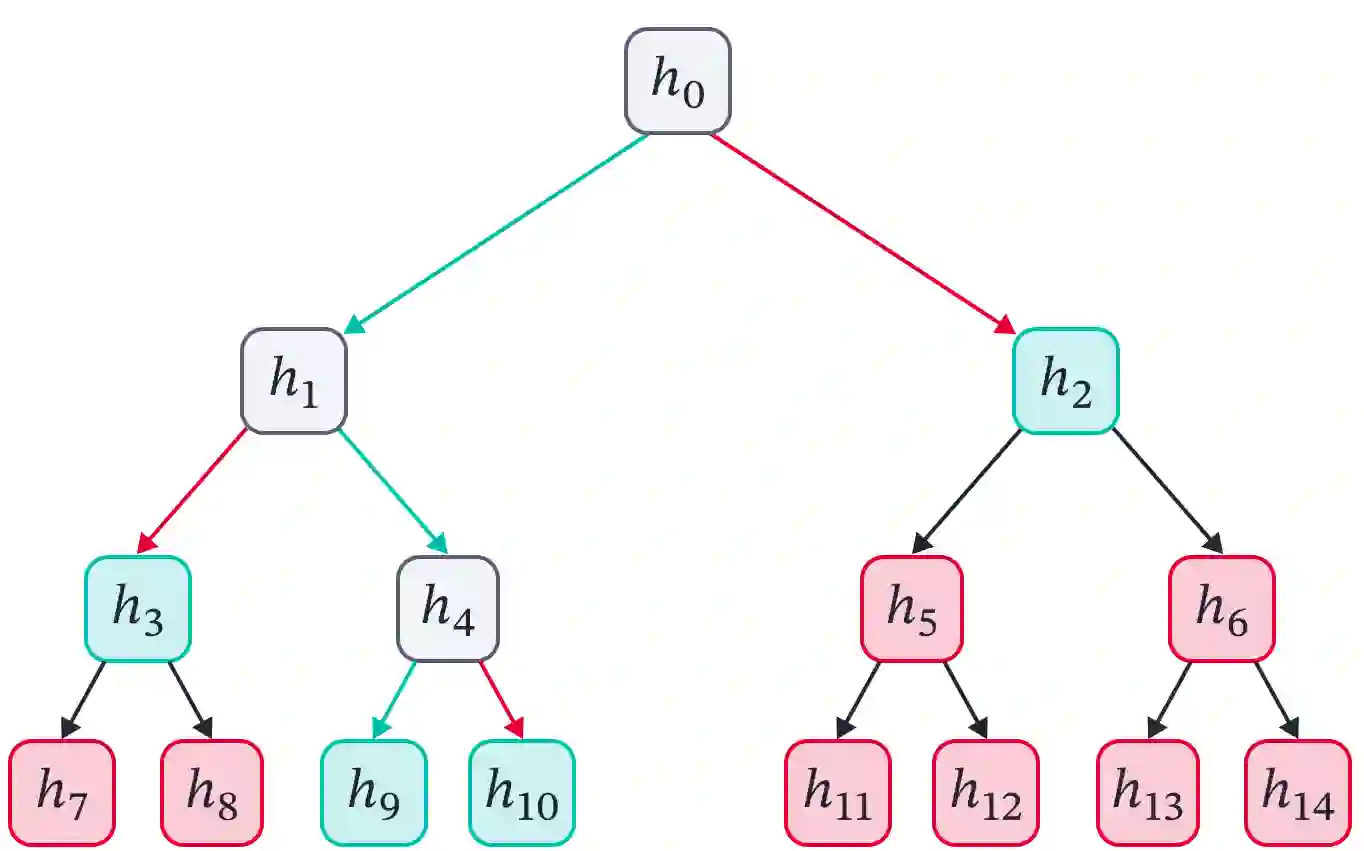
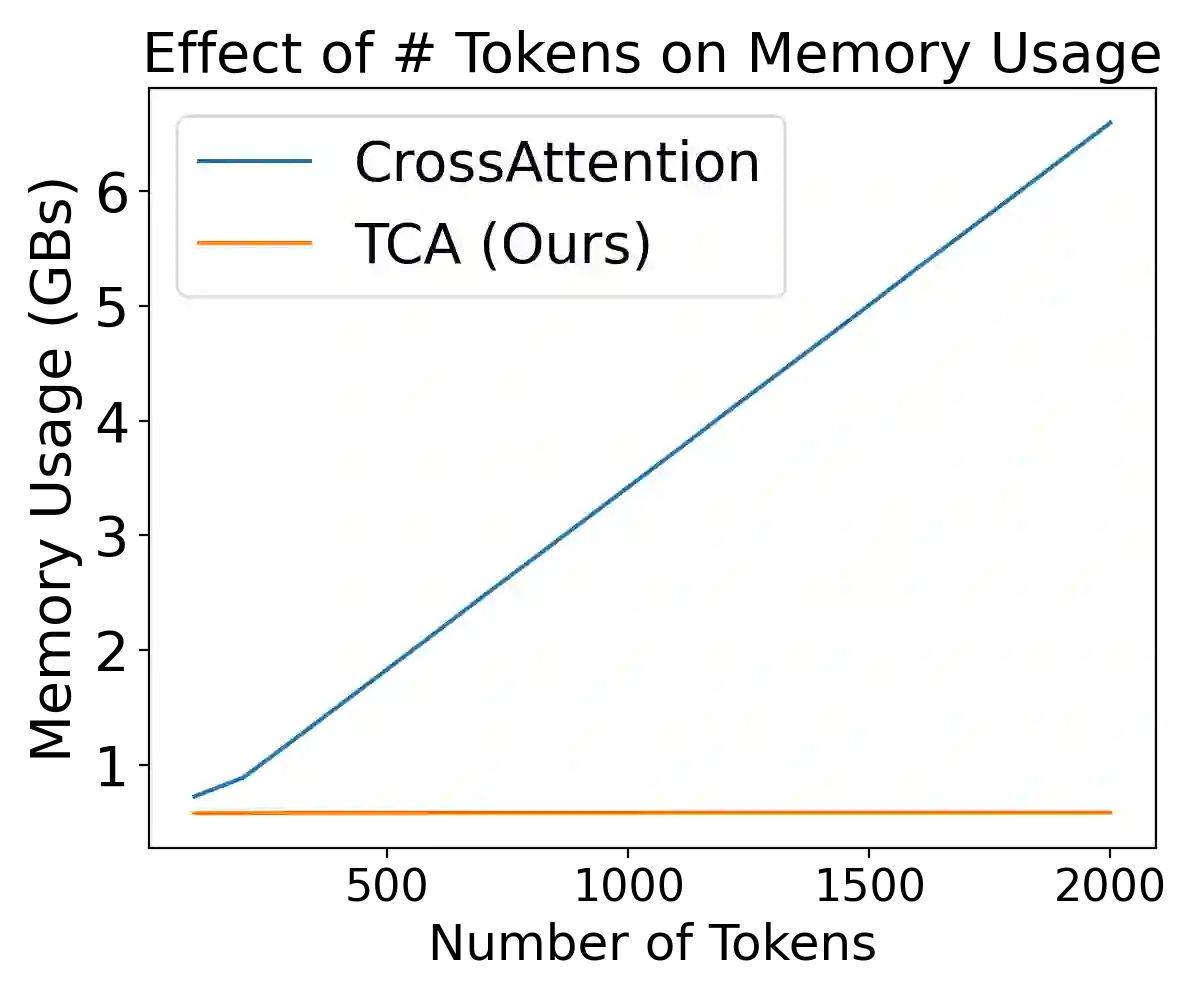
Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
翻译:交叉注意力是一种从上下文令牌集合中检索信息以进行预测的流行方法。在推理时,交叉注意力会扫描所有 $\mathcal{O}(N)$ 个令牌。然而在实践中,通常仅需少量令牌即可获得良好性能。诸如 Perceiver IO 等方法在推理时较为高效,因为它们将信息蒸馏到一组更小的潜在令牌 $L < N$ 上,随后对其应用交叉注意力,从而仅产生 $\mathcal{O}(L)$ 的复杂度。然而,随着输入令牌数量和需蒸馏信息量的增加,所需潜在令牌的数量也会显著增长。在这项工作中,我们提出树交叉注意力(TCA)——一种基于交叉注意力的模块,它仅从对数数量级 $\mathcal{O}(\log(N))$ 的令牌中检索信息进行推理。TCA 将数据组织成树结构,并在推理时执行树搜索以检索相关预测令牌。借助 TCA,我们引入了 ReTreever,一种用于令牌高效推理的灵活架构。实验表明,树交叉注意力(TCA)在各种分类和不确定性回归任务中表现与交叉注意力相当,同时显著提高了令牌效率。此外,我们将 ReTreever 与 Perceiver IO 进行比较,发现在使用相同数量令牌进行推理时,ReTreever 取得了显著优势。