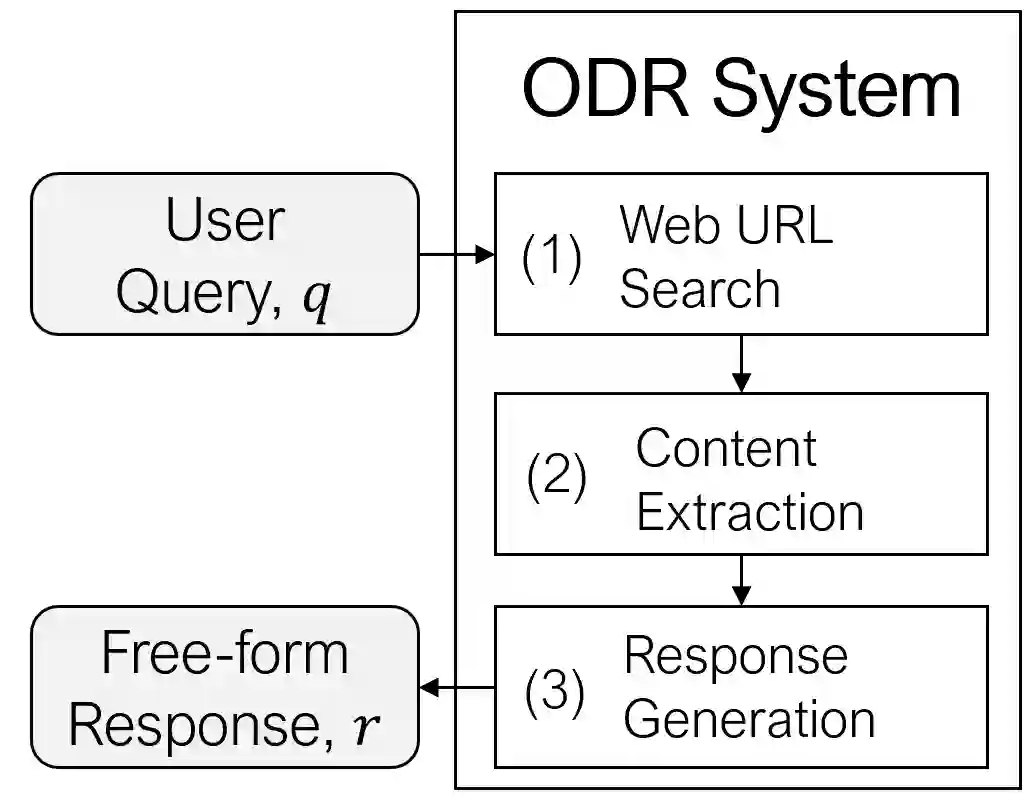
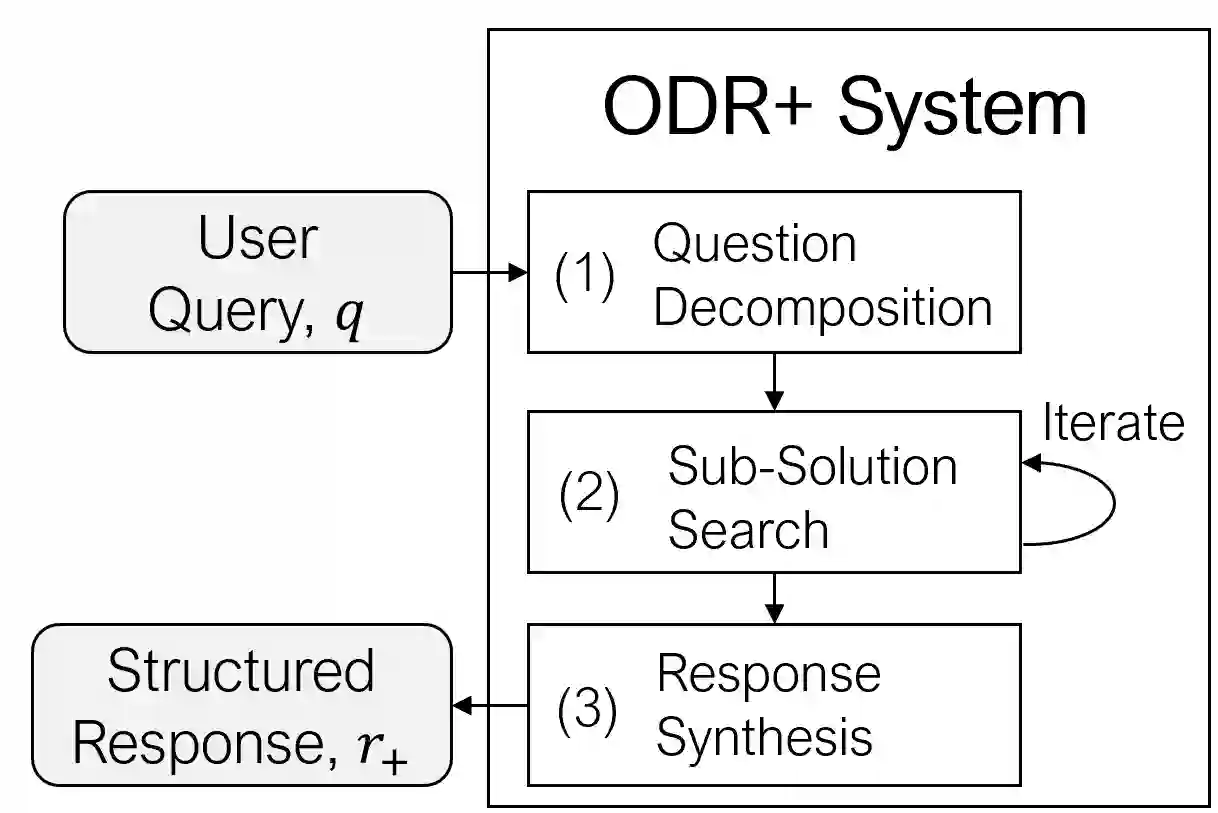
We focus here on Deep Research Agents (DRAs), which are systems that can take a natural language prompt from a user, and then autonomously search for, and utilize, internet-based content to address the prompt. Recent DRAs have demonstrated impressive capabilities on public benchmarks however, recent research largely involves proprietary closed-source systems. At the time of this work, we only found one open-source DRA, termed Open Deep Research (ODR). In this work we adapt the challenging recent BrowseComp benchmark to compare ODR to existing proprietary systems. We propose BrowseComp-Small (BC-Small), comprising a subset of BrowseComp, as a more computationally-tractable DRA benchmark for academic labs. We benchmark ODR and two other proprietary systems on BC-Small: one system from Anthropic and one system from Google. We find that all three systems achieve 0% accuracy on the test set of 60 questions. We introduce three strategic improvements to ODR, resulting in the ODR+ model, which achieves a state-of-the-art 10% success rate on BC-Small among both closed-source and open-source systems. We report ablation studies indicating that all three of our improvements contributed to the success of ODR+.
翻译:本文聚焦于深度研究智能体(DRAs),这类系统能够接收用户的自然语言提示,并自主搜索和利用基于互联网的内容来应对该提示。近期的DRAs在公共基准测试中展现出令人印象深刻的能力,然而当前研究主要涉及专有的闭源系统。在本研究开展时,我们仅发现一个开源DRA,称为开源深度研究(ODR)。本工作中,我们调整了近期具有挑战性的BrowseComp基准,用以比较ODR与现有专有系统。我们提出BrowseComp精简版(BC-Small),作为BrowseComp的一个子集,为学术实验室提供计算上更易处理的DRA基准。我们在BC-Small上对ODR及另外两个专有系统进行了基准测试:一个来自Anthropic,另一个来自Google。研究发现,所有三个系统在包含60个问题的测试集上均取得0%的准确率。我们针对ODR引入了三项策略性改进,由此产生了ODR+模型,该模型在BC-Small上实现了10%的成功率,在闭源与开源系统中均达到最先进水平。我们报告的消融研究表明,所有三项改进均对ODR+的成功有所贡献。