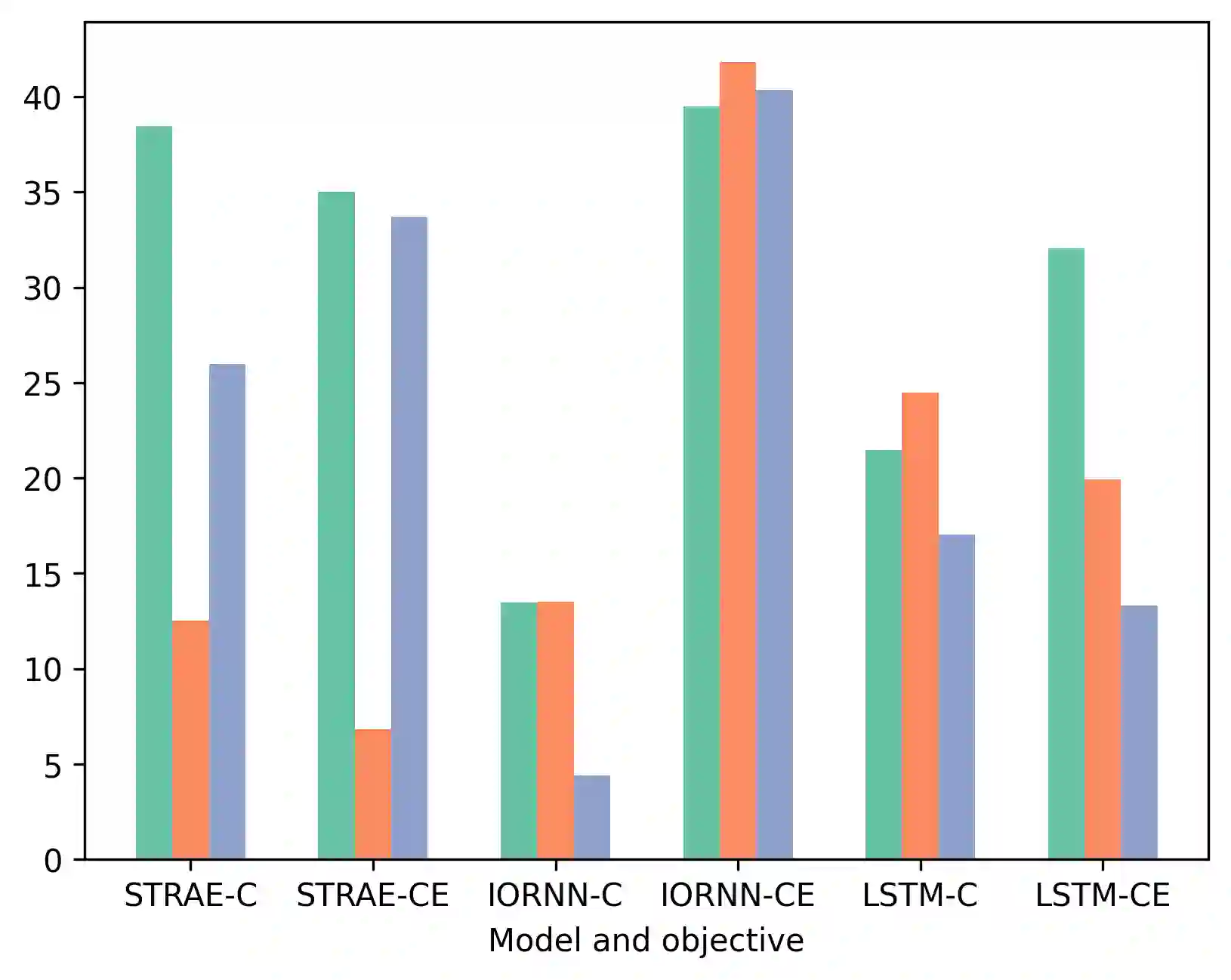
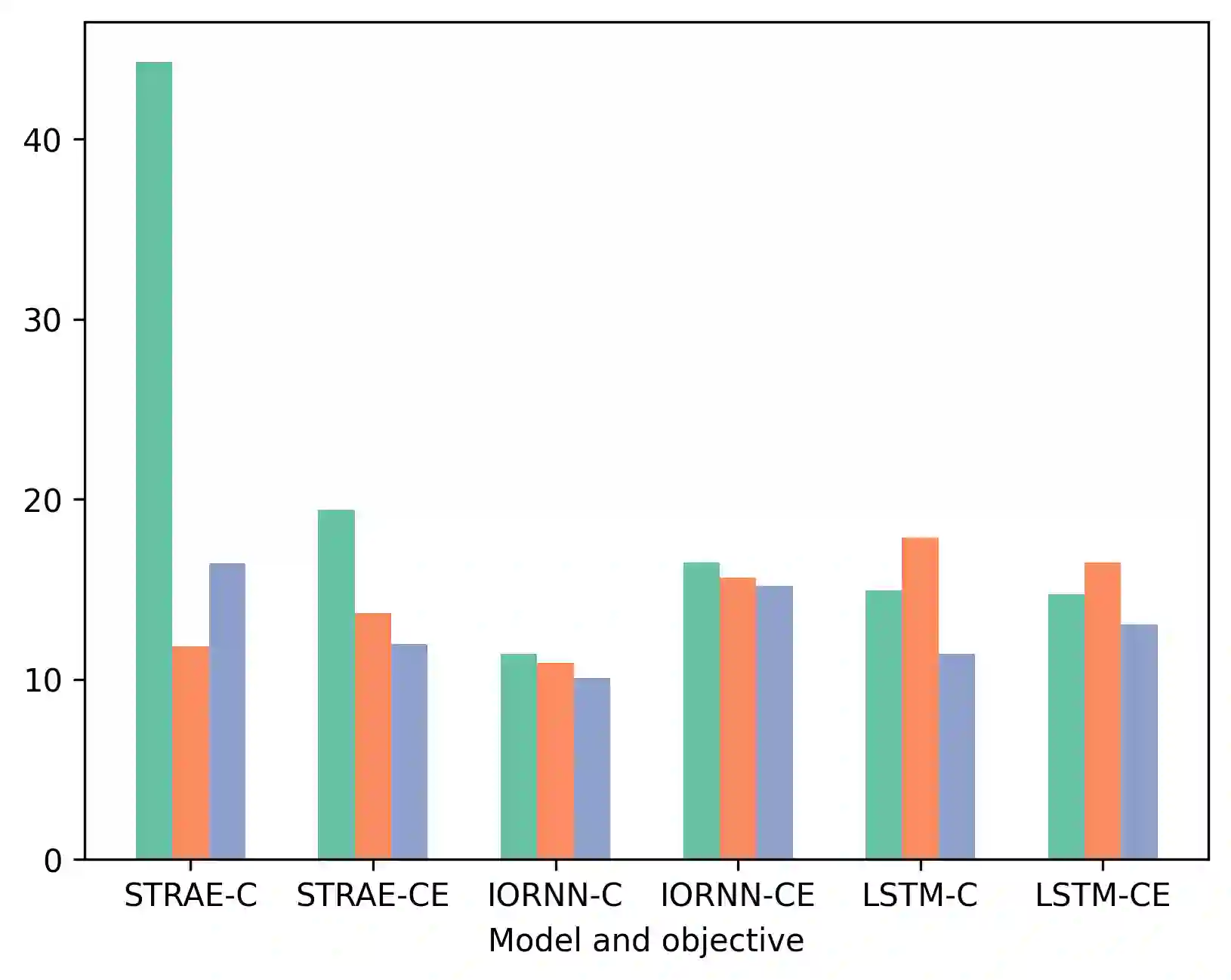
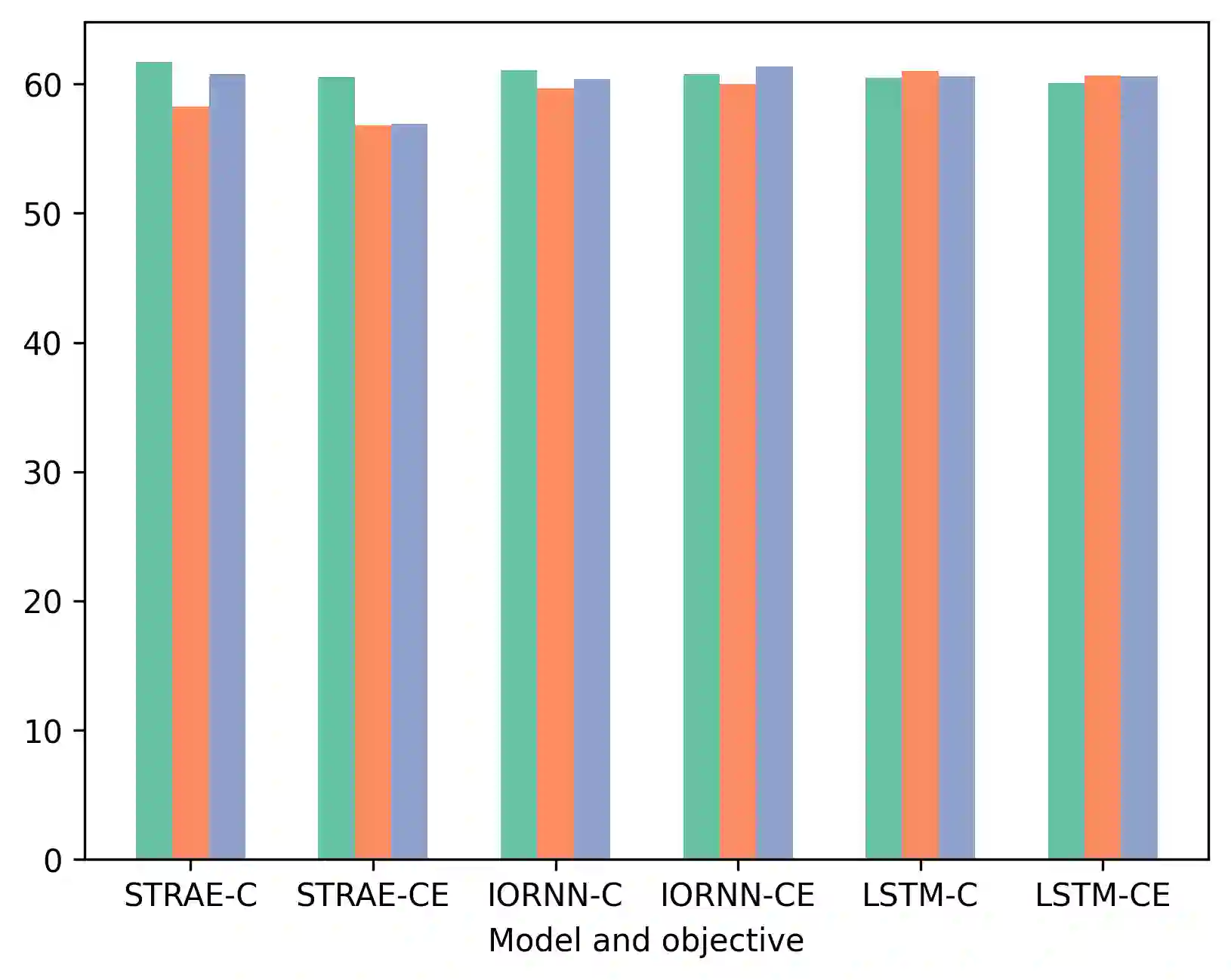
This work presents StrAE: a Structured Autoencoder framework that through strict adherence to explicit structure, and use of a novel contrastive objective over tree-structured representations, enables effective learning of multi-level representations. Through comparison over different forms of structure, we verify that our results are directly attributable to the informativeness of the structure provided as input, and show that this is not the case for existing tree models. We then further extend StrAE to allow the model to define its own compositions using a simple localised-merge algorithm. This variant, called Self-StrAE, outperforms baselines that don't involve explicit hierarchical compositions, and is comparable to models given informative structure (e.g. constituency parses). Our experiments are conducted in a data-constrained (circa 10M tokens) setting to help tease apart the contribution of the inductive bias to effective learning. However, we find that this framework can be robust to scale, and when extended to a much larger dataset (circa 100M tokens), our 430 parameter model performs comparably to a 6-layer RoBERTa many orders of magnitude larger in size. Our findings support the utility of incorporating explicit composition as an inductive bias for effective representation learning.
翻译:本文提出了StrAE:一种结构化自编码框架,通过严格遵循显式结构,并采用针对树形结构表示的新型对比目标,实现了多层级表示的有效学习。通过比较不同结构形式,我们验证了结果直接源于输入结构的信息量,并表明现有树模型不具备这一特性。我们进一步扩展StrAE,允许模型使用简单的局部融合算法自主定义组合方式。该变体称为Self-StrAE,其性能优于不涉及显式层级组合的基线模型,且与使用信息性结构(如成分句法分析)的模型表现相当。我们的实验在数据受限(约1000万词元)条件下进行,以厘清归纳偏置对有效学习的贡献。然而,我们发现该框架对规模具有鲁棒性,当扩展至更大规模数据集(约1亿词元)时,仅含430个参数的模型表现可与规模大数个数量级的6层RoBERTa相媲美。我们的研究结果支持将显式组合作为归纳偏置纳入表示学习的有效性。