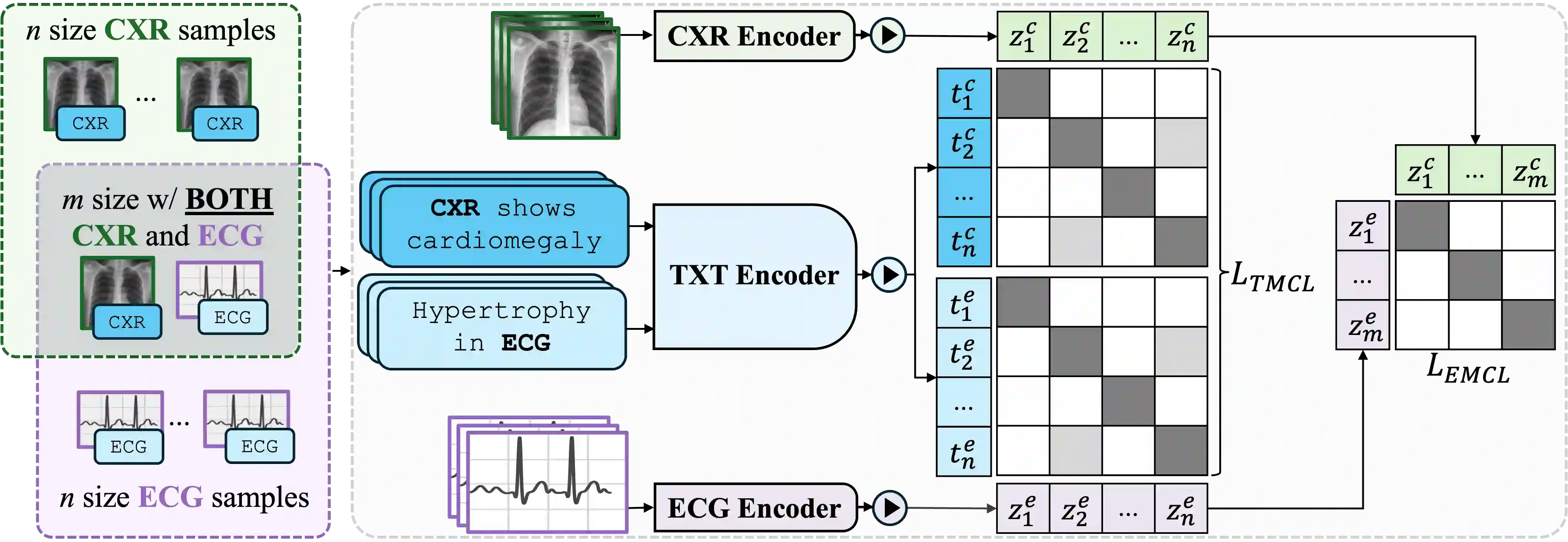
Medical vision-language pretraining models (VLPM) have achieved remarkable progress in fusing chest X-rays (CXR) with clinical texts, introducing image-text data binding approaches that enable zero-shot learning and downstream clinical tasks. However, the current landscape lacks the holistic integration of additional medical modalities, such as electrocardiograms (ECG). We present MEDBind (Medical Electronic patient recorD), which learns joint embeddings across CXR, ECG, and medical text. Using text data as the central anchor, MEDBind features tri-modality binding, delivering competitive performance in top-K retrieval, zero-shot, and few-shot benchmarks against established VLPM, and the ability for CXR-to-ECG zero-shot classification and retrieval. This seamless integration is achieved through combination of contrastive loss on modality-text pairs with our proposed contrastive loss function, Edge-Modality Contrastive Loss, fostering a cohesive embedding space for CXR, ECG, and text. Finally, we demonstrate that MEDBind can improve downstream tasks by directly integrating CXR and ECG embeddings into a large-language model for multimodal prompt tuning.
翻译:医学视觉-语言预训练模型在融合胸部X光片与临床文本方面取得了显著进展,引入了图像-文本数据绑定方法,实现了零样本学习和下游临床任务。然而,当前研究缺乏对其他医学模态(如心电图)的整体性整合。我们提出MEDBind(医学电子病历),该方法学习跨CXR、ECG和医学文本的联合嵌入。以文本数据为中心锚点,MEDBind通过三模态绑定,在Top-K检索、零样本和少样本基准测试中与现有VLPM相比展现出竞争性性能,并具备CXR到ECG零样本分类与检索能力。这种无缝整合通过结合模态-文本对的对比损失与我们提出的边缘模态对比损失函数实现,为CXR、ECG和文本构建了统一的嵌入空间。最后,我们证明MEDBind可通过直接将CXR和ECG嵌入整合到大语言模型中进行多模态提示调优,从而改进下游任务。