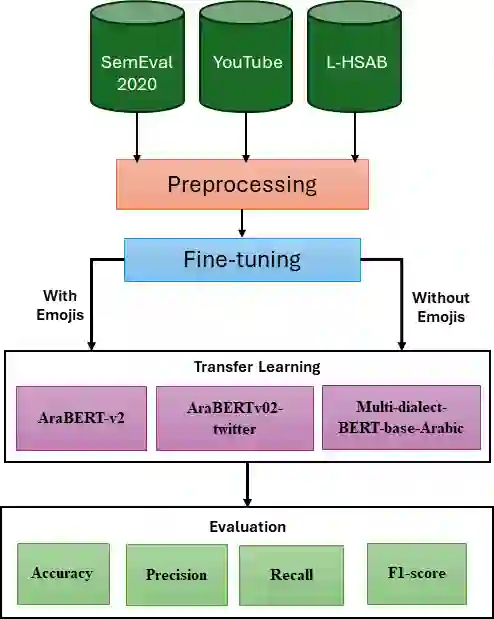
The complex challenge of detecting sarcasm in Arabic speech on social media is increased by the language diversity and the nature of sarcastic expressions. There is a significant gap in the capability of existing models to effectively interpret sarcasm in Arabic, which mandates the necessity for more sophisticated and precise detection methods. In this paper, we investigate the impact of a fundamental preprocessing component on sarcasm speech detection. While emojis play a crucial role in mitigating the absence effect of body language and facial expressions in modern communication, their impact on automated text analysis, particularly in sarcasm detection, remains underexplored. We investigate the impact of emoji exclusion from datasets on the performance of sarcasm detection models in social media content for Arabic as a vocabulary-super rich language. This investigation includes the adaptation and enhancement of AraBERT pre-training models, specifically by excluding emojis, to improve sarcasm detection capabilities. We use AraBERT pre-training to refine the specified models, demonstrating that the removal of emojis can significantly boost the accuracy of sarcasm detection. This approach facilitates a more refined interpretation of language, eliminating the potential confusion introduced by non-textual elements. The evaluated AraBERT models, through the focused strategy of emoji removal, adeptly navigate the complexities of Arabic sarcasm. This study establishes new benchmarks in Arabic natural language processing and presents valuable insights for social media platforms.
翻译:社交媒体上阿拉伯语话语中讽刺检测的复杂挑战因语言多样性和讽刺表达的本质而加剧。现有模型在有效解读阿拉伯语讽刺方面存在显著能力差距,这要求开发更精密和准确的检测方法。本文研究了基本预处理组件对讽刺话语检测的影响。尽管表情符号在现代交流中缓解肢体语言和面部表情缺失效应方面具有关键作用,但其对自动化文本分析(尤其是讽刺检测)的影响仍未被充分探索。我们以阿拉伯语这一词汇超丰富语言为对象,研究了从数据集中排除表情符号对社交媒体内容讽刺检测模型性能的影响。本研究包括对AraBERT预训练模型的适配与增强,具体通过排除表情符号来提升讽刺检测能力。我们利用AraBERT预训练对指定模型进行优化,证明移除表情符号可显著提升讽刺检测的准确性。该方法通过消除非文本元素可能引入的混淆,促进了更精细的语言解读。经过评估的AraBERT模型通过专注于表情符号移除的策略,娴熟地驾驭了阿拉伯语讽刺的复杂性。本研究为阿拉伯语自然语言处理设立了新基准,并为社交媒体平台提供了宝贵见解。