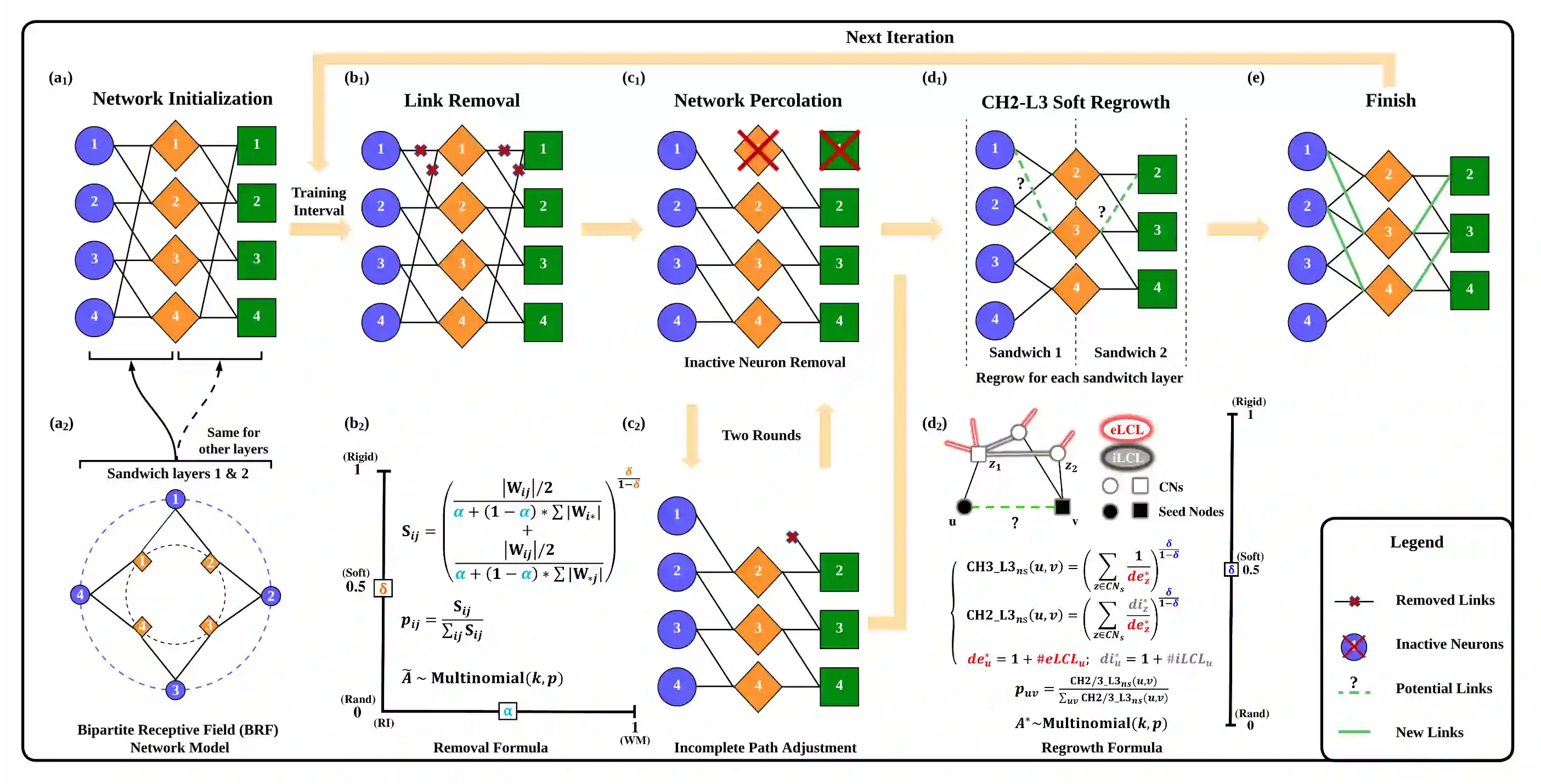
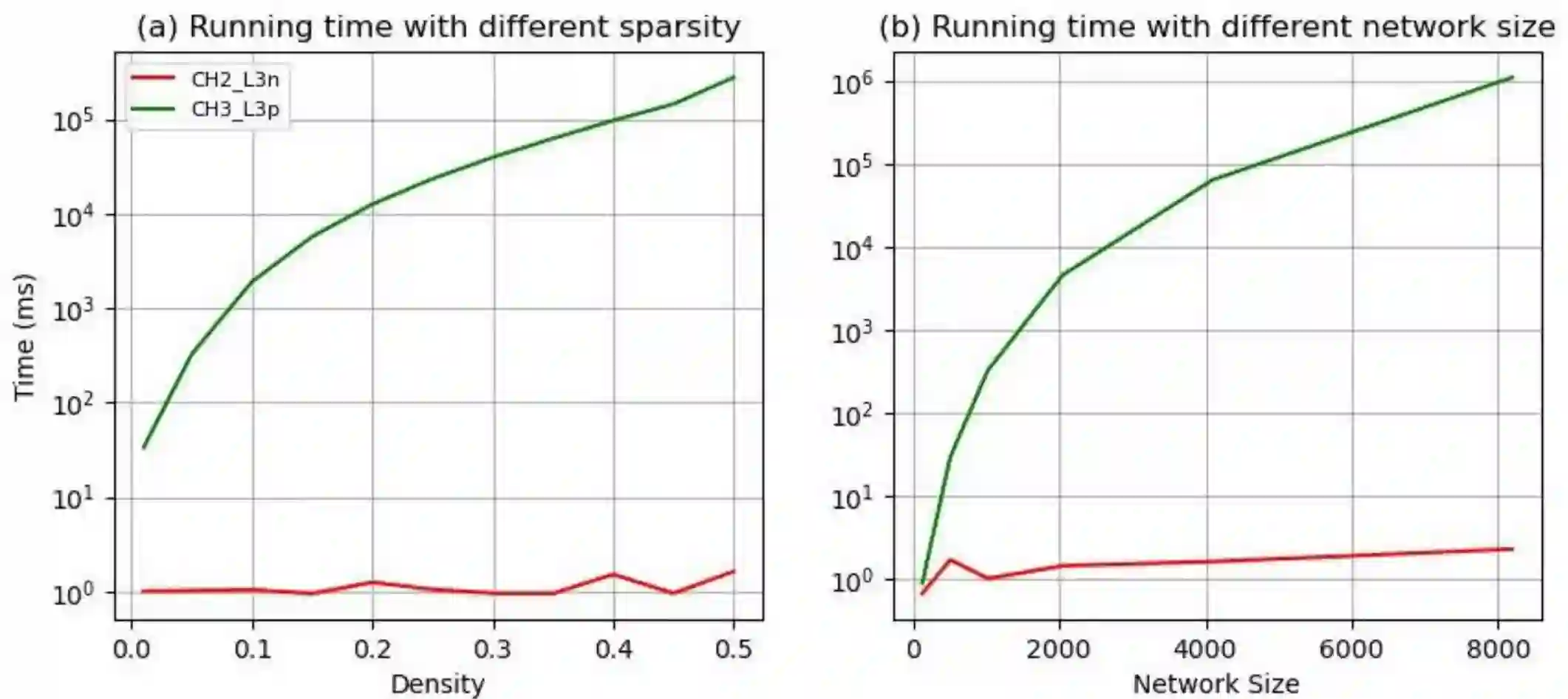
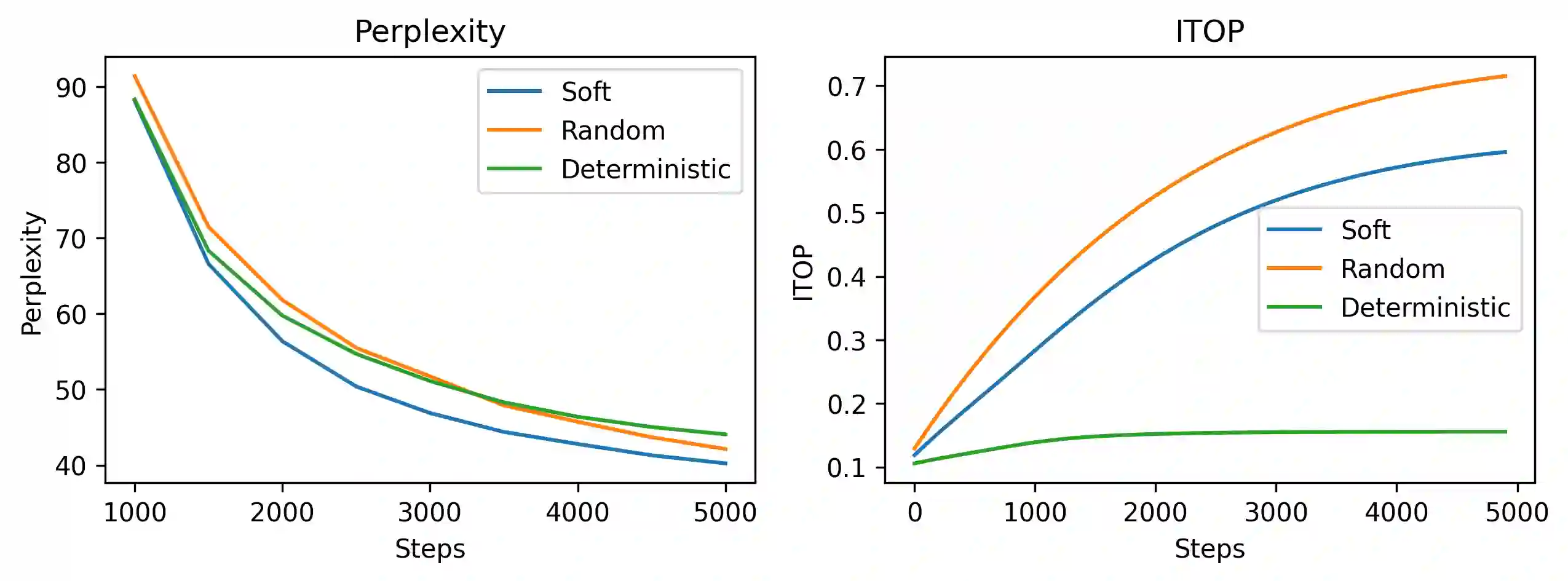
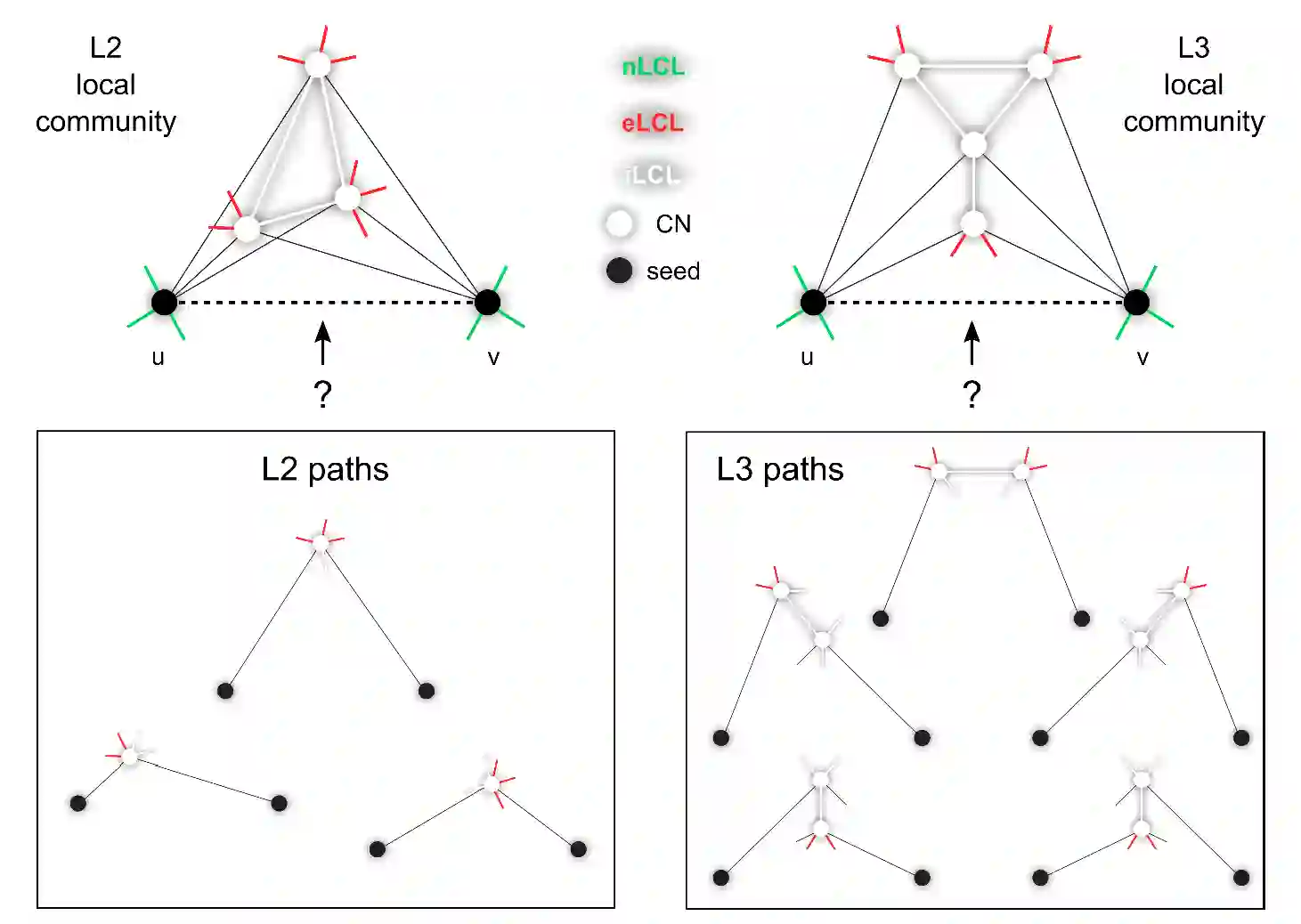
Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties in keeping peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (less than 1% connectivity) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is $O(Nd^3)$ - N node network size, d node degree - restricting it to ultra-sparse regimes. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. Here, we design the first brain-inspired network model - termed bipartite receptive field (BRF) - to initialize the connectivity of sparse artificial neural networks. We further introduce a GPU-friendly matrix-based approximation of CH link prediction, reducing complexity to $O(N^3)$. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a flexible strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. Additionally, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that BRF offers performance advantages over previous network science models. Using 1% of connections, CHTs outperforms fully connected networks in MLP architectures on image classification tasks, compressing some networks to less than 30% of the nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Finally, at 30% connectivity, both CHTs and CHTss outperform other DST methods in language modeling task.
翻译:动态稀疏训练(DST)能够降低人工神经网络的计算需求,但在高稀疏度下难以保持峰值性能。Cannistraci-Hebb训练(CHT)是一种受大脑启发的、用于在DST中增长连接的方法。CHT利用一种无梯度、拓扑驱动的链路再生机制,与全连接网络相比,已在多种任务中展现出超稀疏(连接度低于1%)优势。然而,CHT存在两个主要缺点:(i)其时间复杂度为$O(Nd^3)$(N为网络节点数,d为节点度),这限制了其仅适用于超稀疏状态;(ii)它选择最高链路预测分数进行连接,这在训练早期网络连接不可靠时并不合适。本文中,我们设计了首个受大脑启发的网络模型——称为二分感受野(BRF)——用于初始化稀疏人工神经网络的连接结构。我们进一步提出了一种适用于GPU的、基于矩阵的CH链路预测近似方法,将复杂度降低至$O(N^3)$。我们引入了Cannistraci-Hebb训练软规则(CHTs),该规则在链路删除与再生中采用灵活的连接采样策略,平衡了网络拓扑的探索与利用。此外,我们将CHTs与S型渐进密度衰减策略相结合(CHTss)。实验结果表明,BRF相比之前的网络科学模型具有性能优势。在图像分类任务中,使用1%的连接时,CHTs在MLP架构上超越了全连接网络,并将某些网络的节点数压缩至原规模的30%以下。在基于Transformer的机器翻译任务中,使用5%的连接时,CHTss超越了全连接网络。最后,在语言建模任务中,当连接度为30%时,CHTs与CHTss均优于其他DST方法。