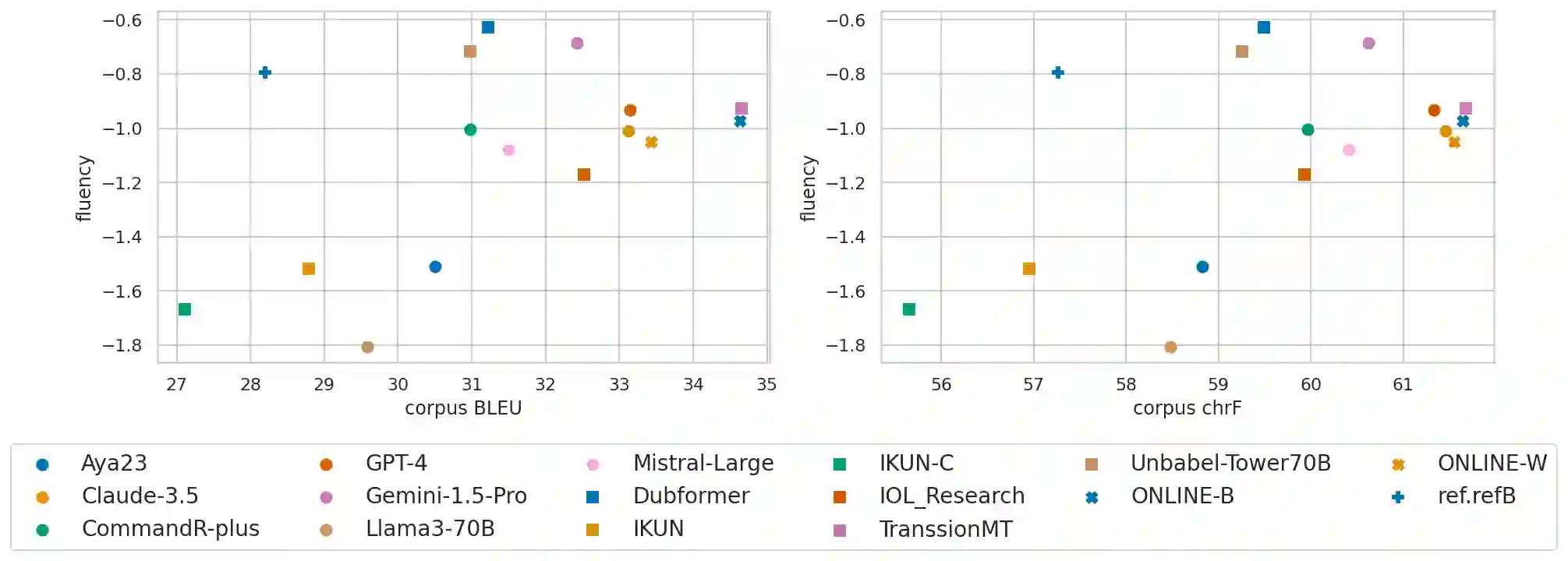
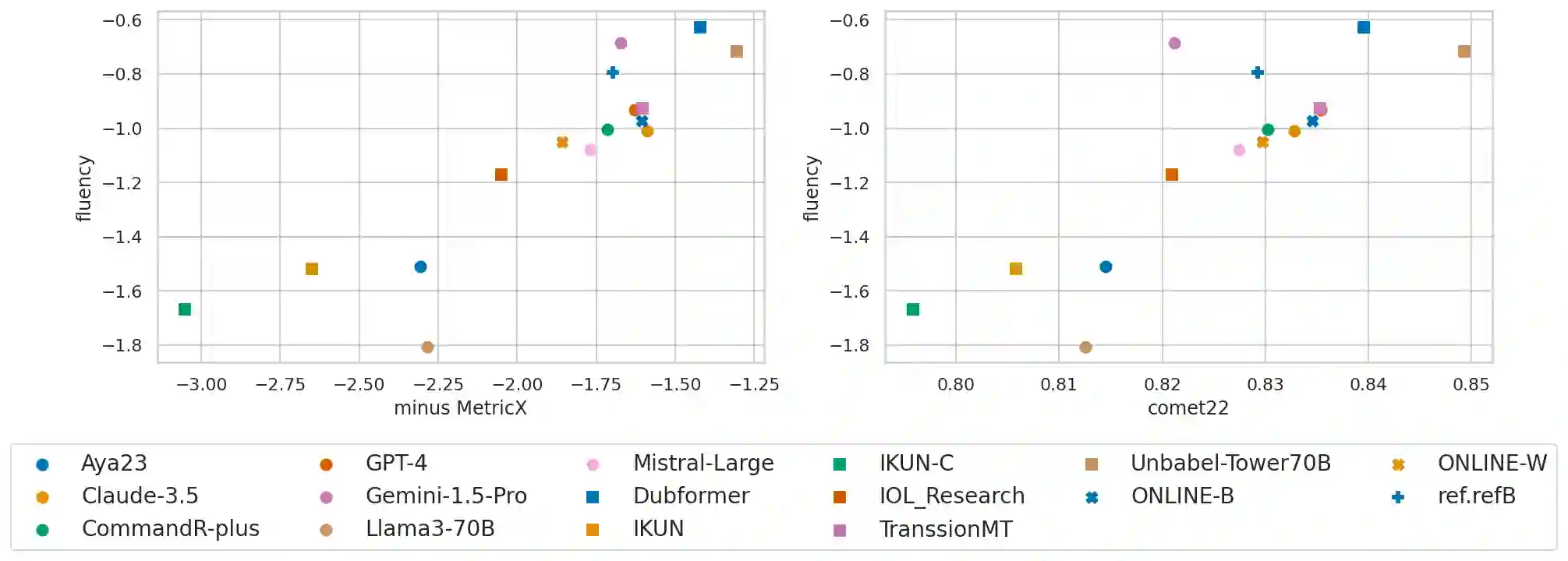
The goal of translation, be it by human or by machine, is, given some text in a source language, to produce text in a target language that simultaneously 1) preserves the meaning of the source text and 2) achieves natural expression in the target language. However, researchers in the machine translation community usually assess translations using a single score intended to capture semantic accuracy and the naturalness of the output simultaneously. In this paper, we build on recent advances in information theory to mathematically prove and empirically demonstrate that such single-score summaries do not and cannot give the complete picture of a system's true performance. Concretely, we prove that a tradeoff exists between accuracy and naturalness and demonstrate it by evaluating the submissions to the WMT24 shared task. Our findings help explain well-known empirical phenomena, such as the observation that optimizing translation systems for a specific accuracy metric (like BLEU) initially improves the system's naturalness, while ``overfitting'' the system to the metric can significantly degrade its naturalness. Thus, we advocate for a change in how translations are evaluated: rather than comparing systems using a single number, they should be compared on an accuracy-naturalness plane.
翻译:翻译的目标,无论是人工翻译还是机器翻译,都是在给定源语言文本的情况下,生成目标语言文本,该文本需同时满足:1) 保留源文本的意义,2) 在目标语言中实现自然的表达。然而,机器翻译领域的研究人员通常使用一个单一的分数来评估翻译,该分数旨在同时捕捉语义准确性和输出的自然性。在本文中,我们基于信息论的最新进展,从数学上证明并通过实验证明,这种单一分数的总结不能、也无法完整反映一个系统的真实性能。具体而言,我们证明了准确性与自然性之间存在权衡,并通过评估WMT24共享任务的提交结果来展示这一点。我们的发现有助于解释一些众所周知的实证现象,例如观察到针对特定准确性指标(如BLEU)优化翻译系统最初会提高系统的自然性,而对该指标的“过拟合”则会显著降低其自然性。因此,我们主张改变翻译的评估方式:不应使用单一数字来比较系统,而应在准确性与自然性构成的平面上进行比较。