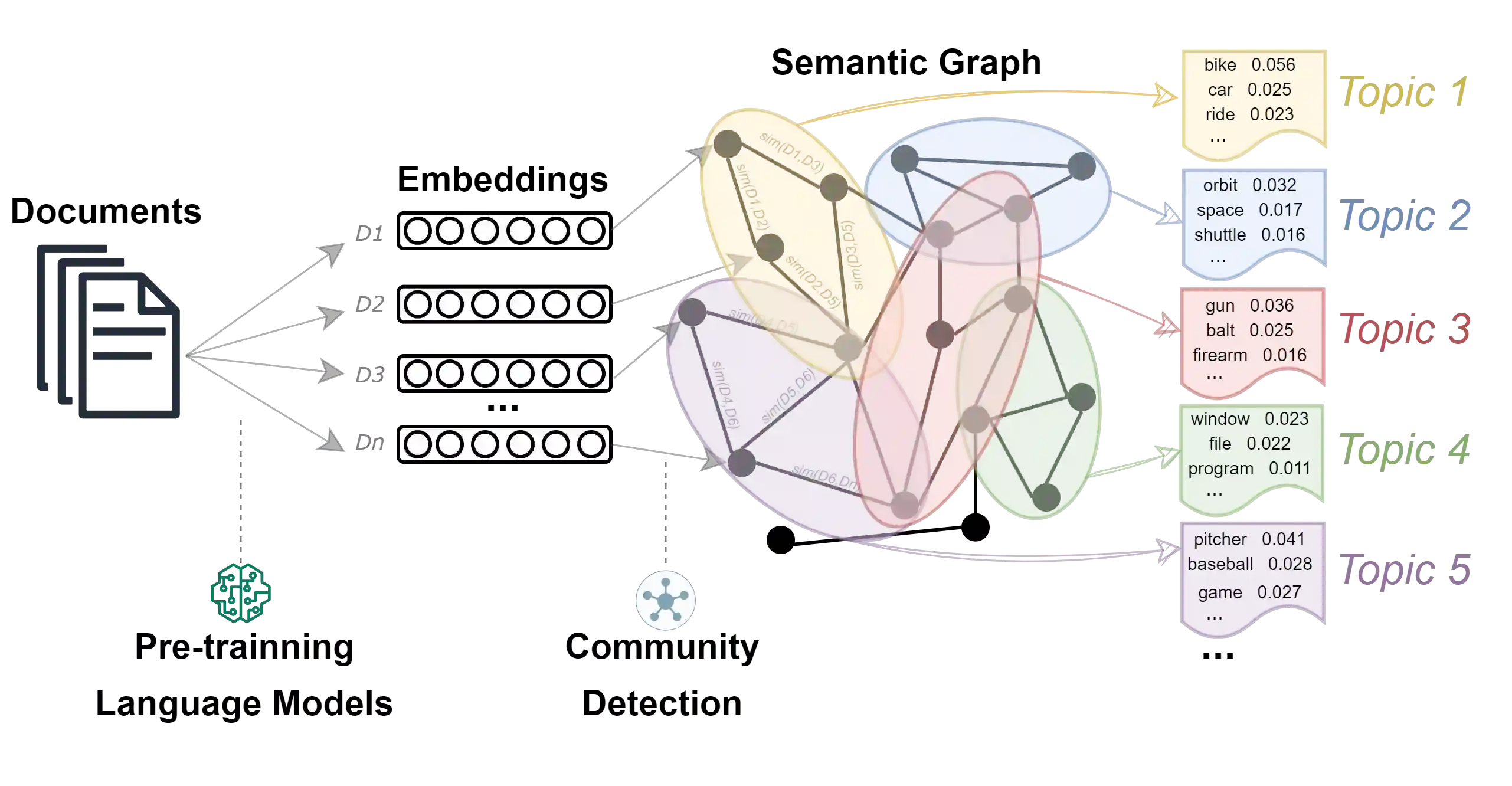
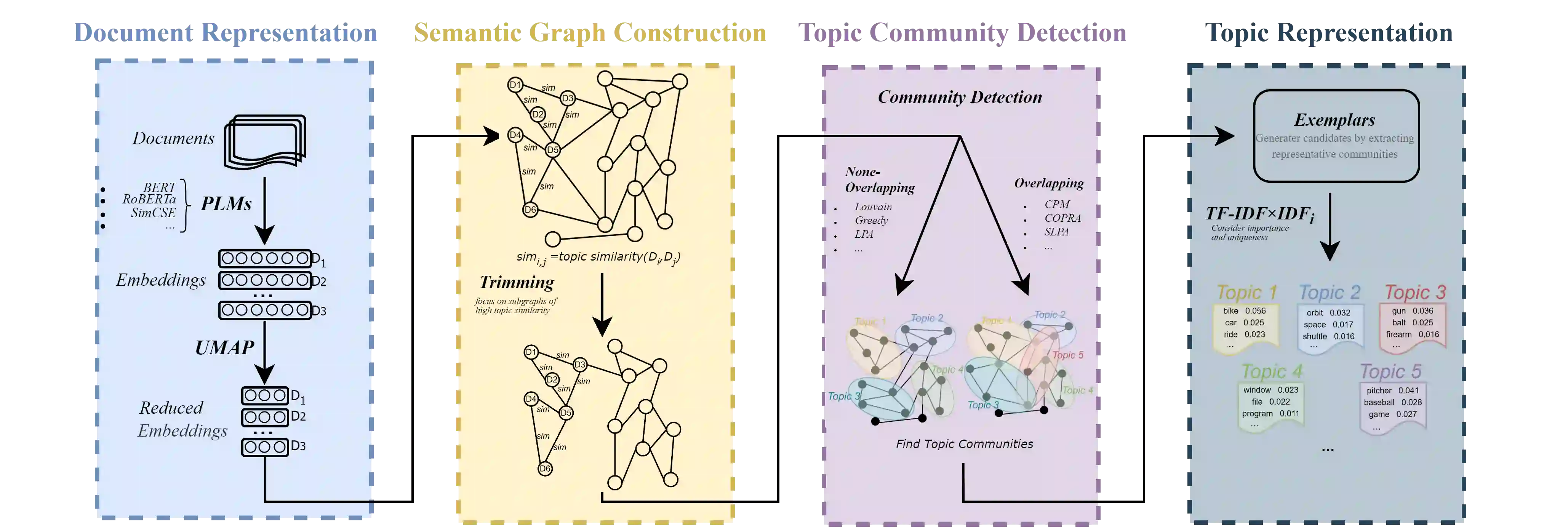
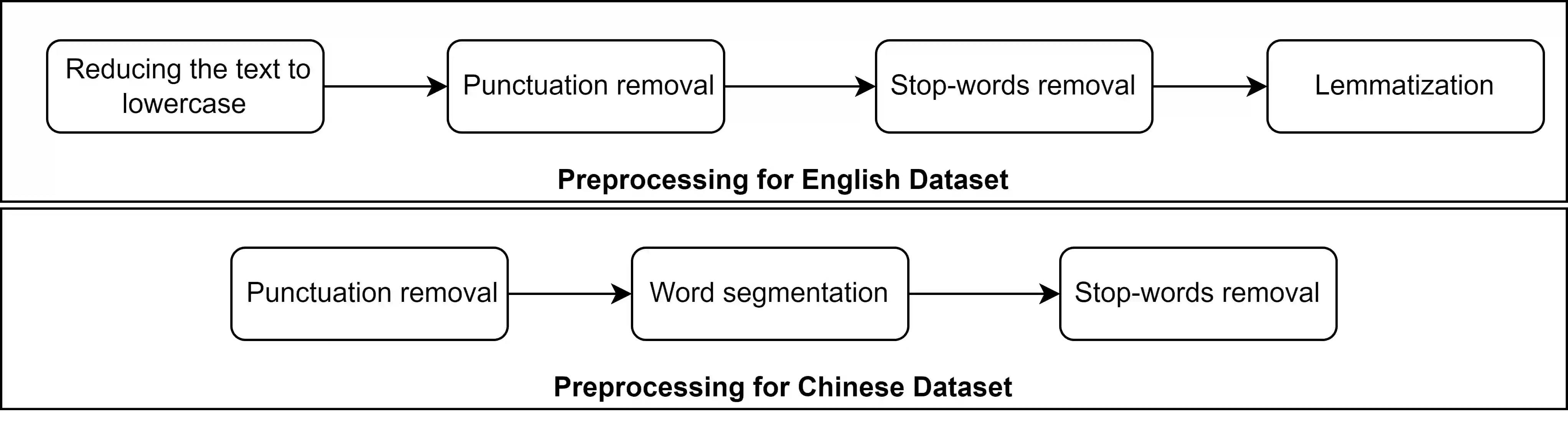
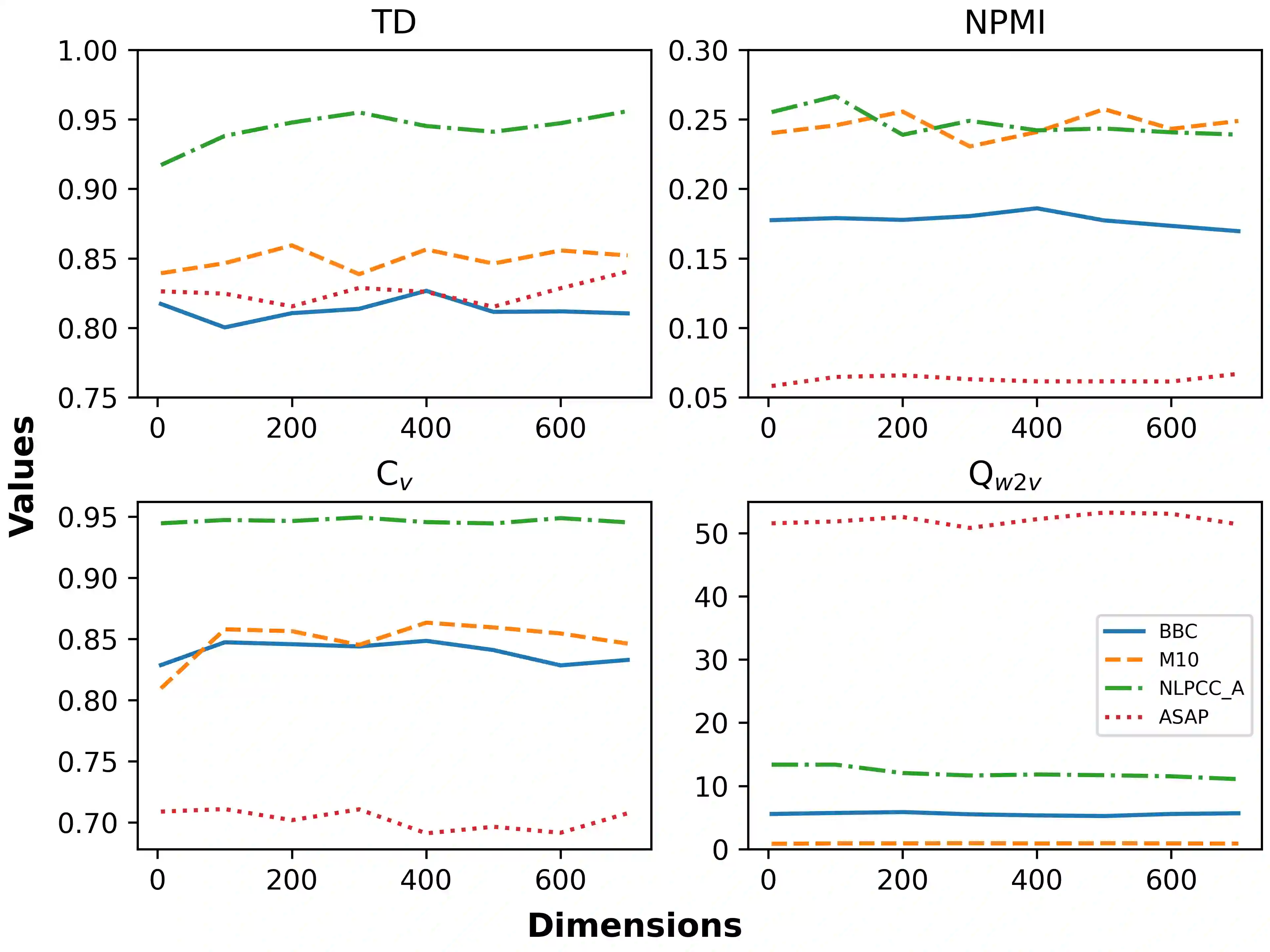
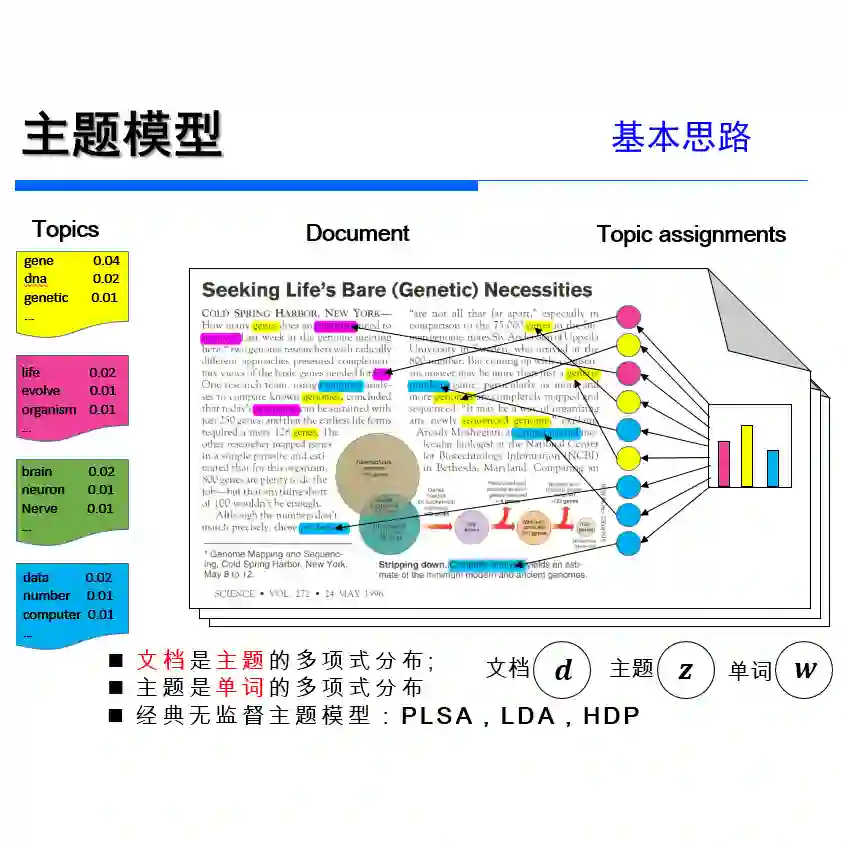
It has been reported that clustering-based topic models, which cluster high-quality sentence embeddings with an appropriate word selection method, can generate better topics than generative probabilistic topic models. However, these approaches suffer from the inability to select appropriate parameters and incomplete models that overlook the quantitative relation between words with topics and topics with text. To solve these issues, we propose graph to topic (G2T), a simple but effective framework for topic modelling. The framework is composed of four modules. First, document representation is acquired using pretrained language models. Second, a semantic graph is constructed according to the similarity between document representations. Third, communities in document semantic graphs are identified, and the relationship between topics and documents is quantified accordingly. Fourth, the word--topic distribution is computed based on a variant of TFIDF. Automatic evaluation suggests that G2T achieved state-of-the-art performance on both English and Chinese documents with different lengths. Human judgements demonstrate that G2T can produce topics with better interpretability and coverage than baselines. In addition, G2T can not only determine the topic number automatically but also give the probabilistic distribution of words in topics and topics in documents. Finally, G2T is publicly available, and the distillation experiments provide instruction on how it works.
翻译:已有研究表明,基于聚类的主题模型通过结合适当的词选择方法对高质量句子嵌入进行聚类,能够生成比生成式概率主题模型更优的主题。然而,这类方法存在参数选择困难以及模型不完整的问题——未能充分考虑词与主题、主题与文本之间的量化关系。为解决上述问题,本文提出图到主题(G2T)这一简单有效的主题建模框架。该框架由四个模块构成:首先,利用预训练语言模型获取文档表示;其次,根据文档表示之间的相似性构建语义图;第三,识别文档语义图中的社区,并据此量化主题与文档之间的关系;第四,基于TFIDF的变体计算词-主题分布。自动评测表明,G2T在英文和中文不同长度文档上均取得了最先进性能。人工评估显示,与基线方法相比,G2T生成的主题具有更优的可解释性和覆盖率。此外,G2T不仅能自动确定主题数量,还能给出词在主题中的概率分布及主题在文档中的概率分布。最后,G2T已开源,蒸馏实验为其工作机制提供了指导说明。