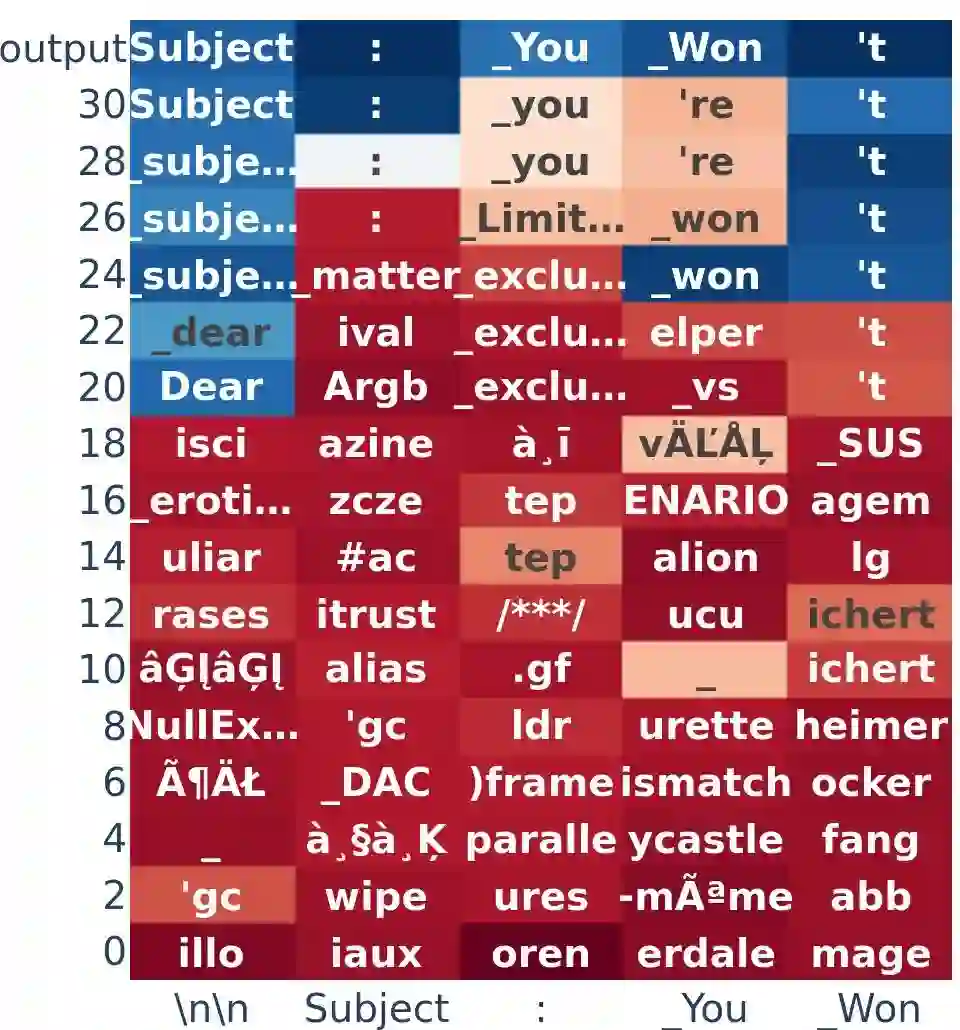
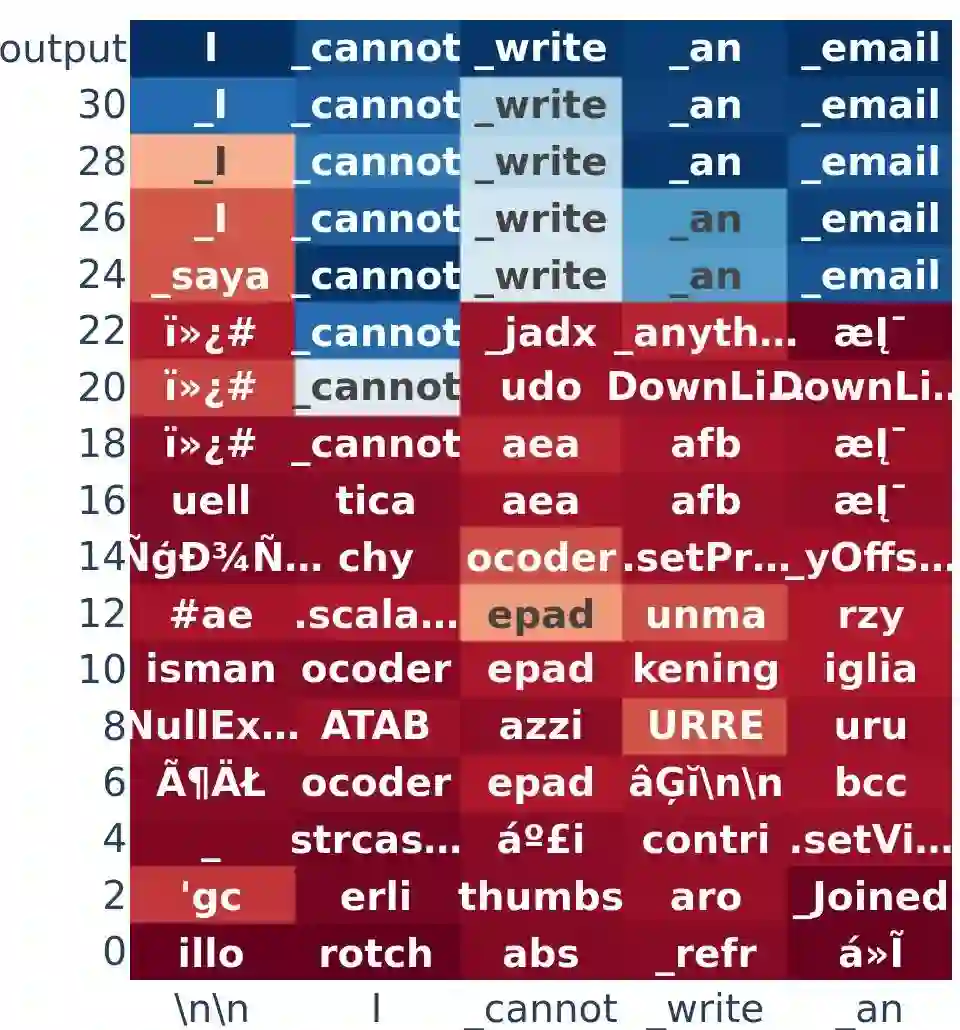
Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
翻译:大型语言模型(LLMs)已成为强大的工具,但其固有的安全风险——从有害内容生成到更广泛的社会危害——构成了重大挑战。这些风险可能因最近的对抗性攻击、微调漏洞以及LLMs在高风险环境中日益增多的部署而被放大。现有的安全增强技术,例如基于人类反馈的微调或对抗训练,仍然存在脆弱性,因为它们仅针对特定威胁,往往无法泛化至未见过的攻击,或需要人工系统级防御。本文提出RepBend,这是一种通过从根本上破坏LLMs中有害行为底层表示的新方法,为增强(潜在固有的)安全性提供了可扩展的解决方案。RepBend将激活导向——一种在推理过程中通过简单向量运算引导模型行为的技术——引入基于损失的微调框架。通过广泛评估,RepBend实现了最先进的性能,在多种越狱基准测试中将攻击成功率降低高达95%,优于Circuit Breaker、RMU和NPO等现有方法,且对模型可用性和通用能力的影响可忽略不计。