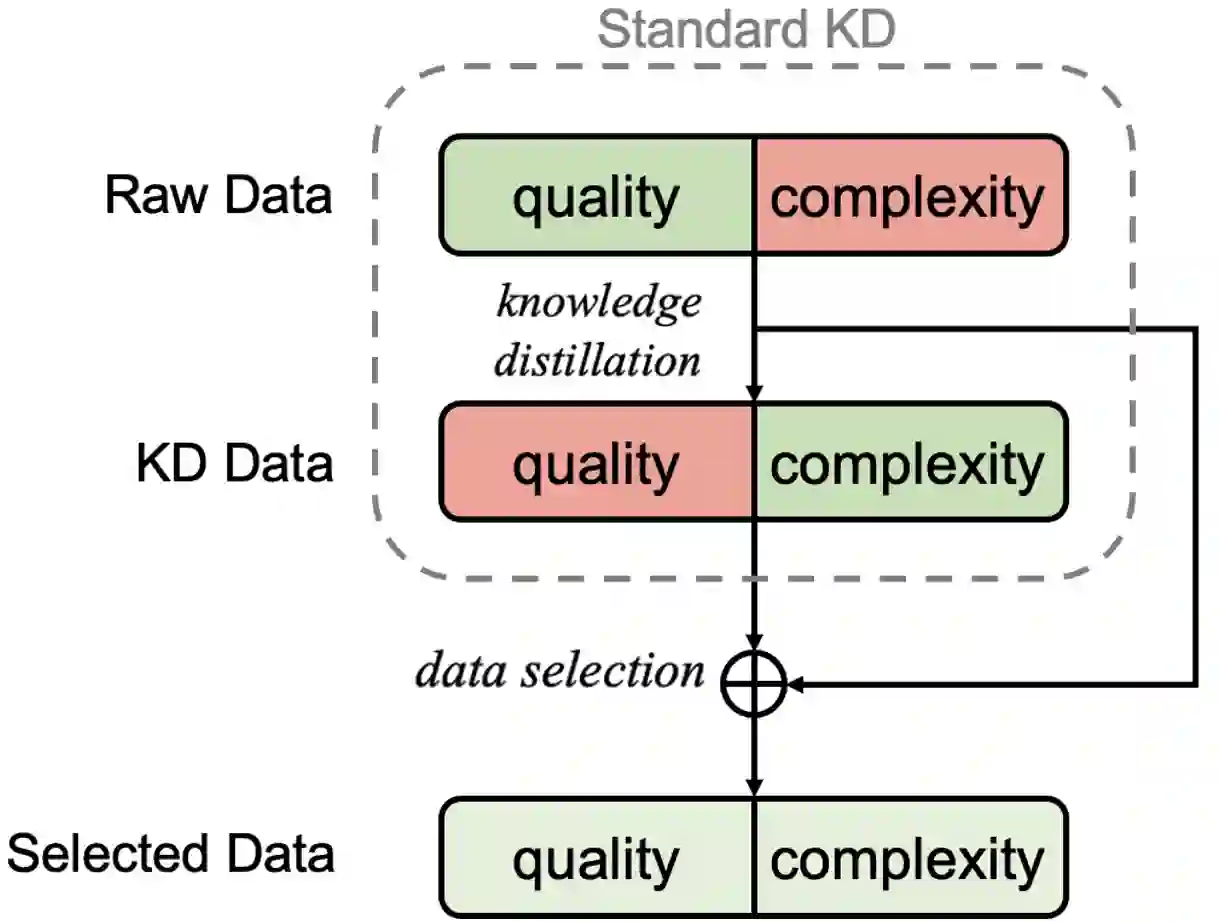
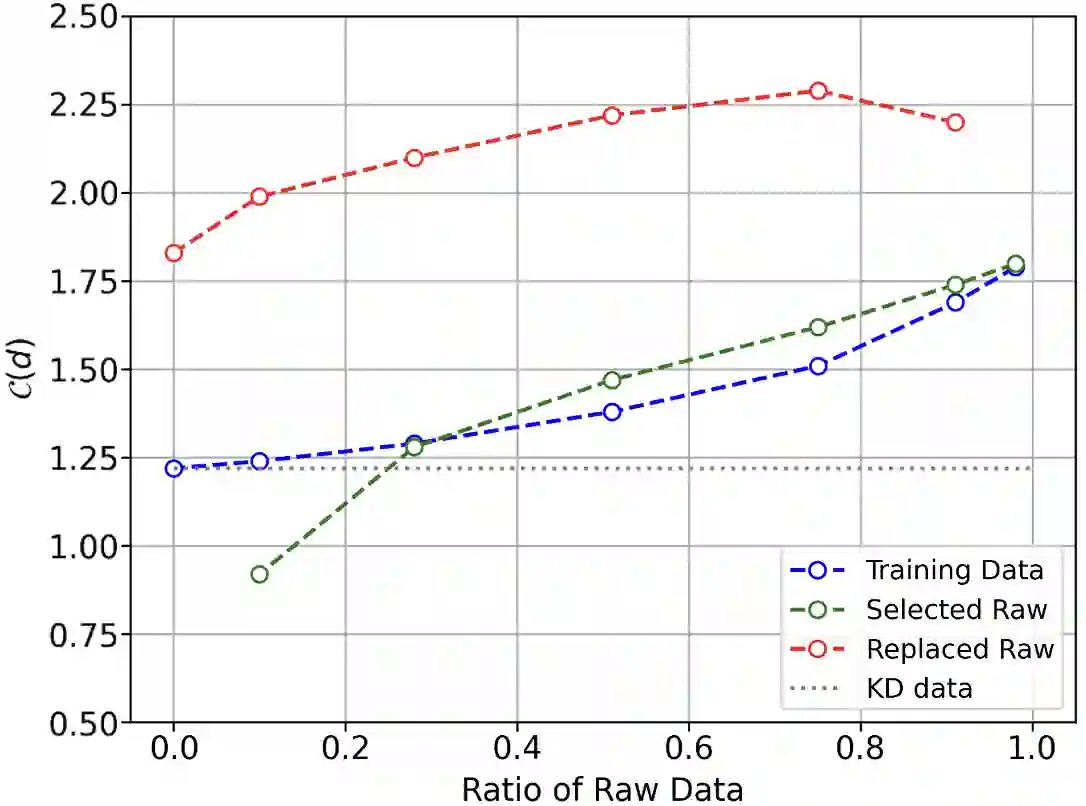
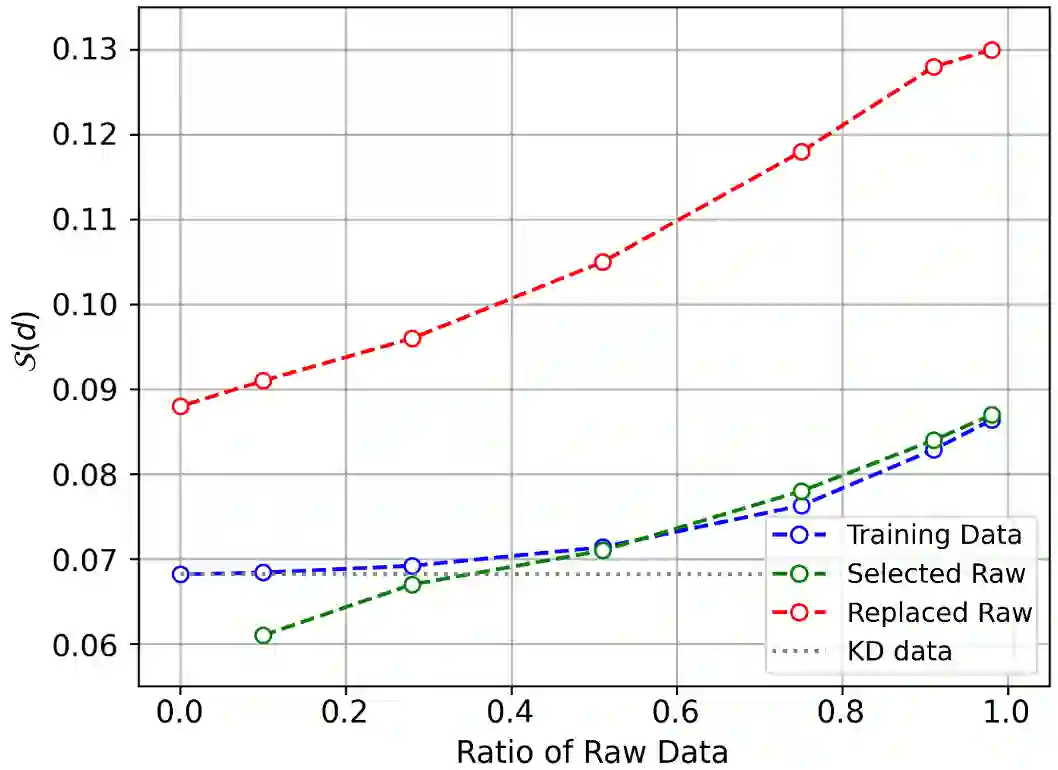
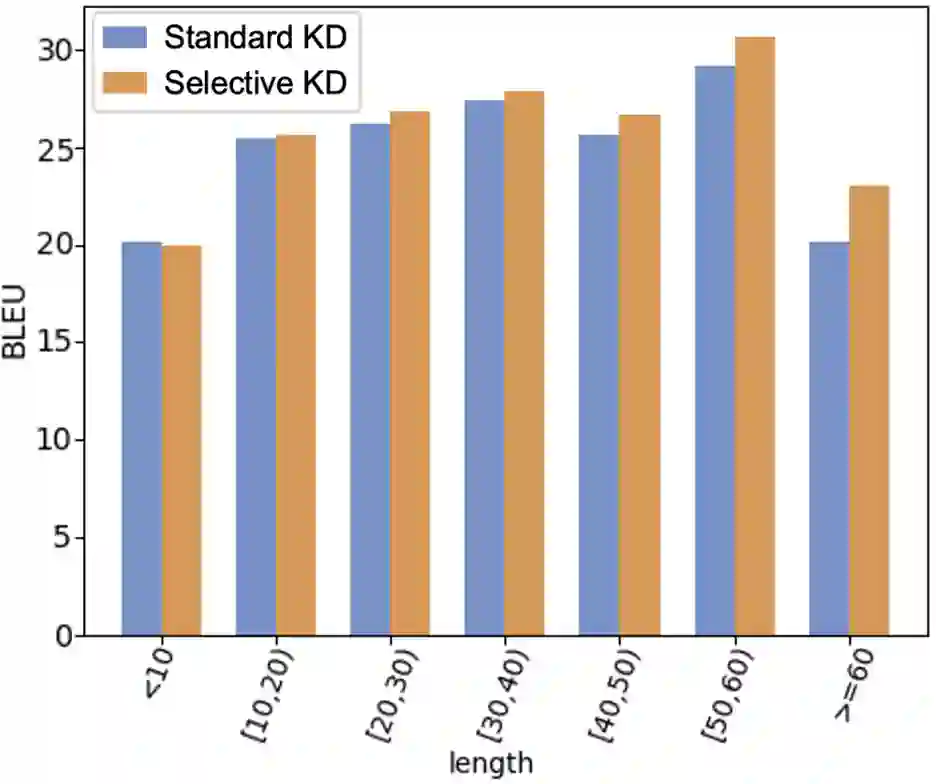
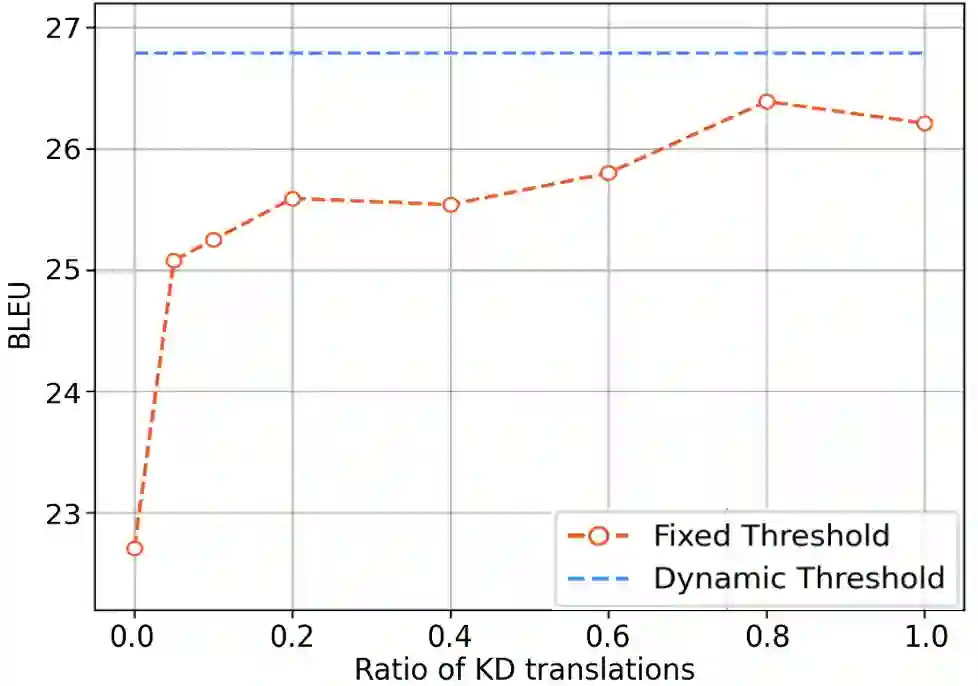
Benefiting from the sequence-level knowledge distillation, the Non-Autoregressive Transformer (NAT) achieves great success in neural machine translation tasks. However, existing knowledge distillation has side effects, such as propagating errors from the teacher to NAT students, which may limit further improvements of NAT models and are rarely discussed in existing research. In this paper, we introduce selective knowledge distillation by introducing an NAT evaluator to select NAT-friendly targets that are of high quality and easy to learn. In addition, we introduce a simple yet effective progressive distillation method to boost NAT performance. Experiment results on multiple WMT language directions and several representative NAT models show that our approach can realize a flexible trade-off between the quality and complexity of training data for NAT models, achieving strong performances. Further analysis shows that distilling only 5% of the raw translations can help an NAT outperform its counterpart trained on raw data by about 2.4 BLEU.
翻译:受益于序列级知识蒸馏,非自回归Transformer(NAT)在神经机器翻译任务中取得了巨大成功。然而,现有知识蒸馏存在副作用,例如将错误从教师模型传播至NAT学生模型,这可能限制NAT模型的进一步提升,而现有研究对此鲜有探讨。本文通过引入NAT评估器来选择高质量且易于学习的NAT友好型目标,提出了一种选择性知识蒸馏方法。此外,我们引入了一种简单而有效的渐进式蒸馏方法来提升NAT性能。在多个WMT语言方向及若干代表性NAT模型上的实验结果表明,我们的方法能够实现NAT模型训练数据质量与复杂度之间的灵活权衡,从而取得优异性能。进一步分析表明,仅蒸馏5%的原始翻译即可帮助NAT模型在BLEU值上超越基于原始数据训练的对应模型约2.4分。