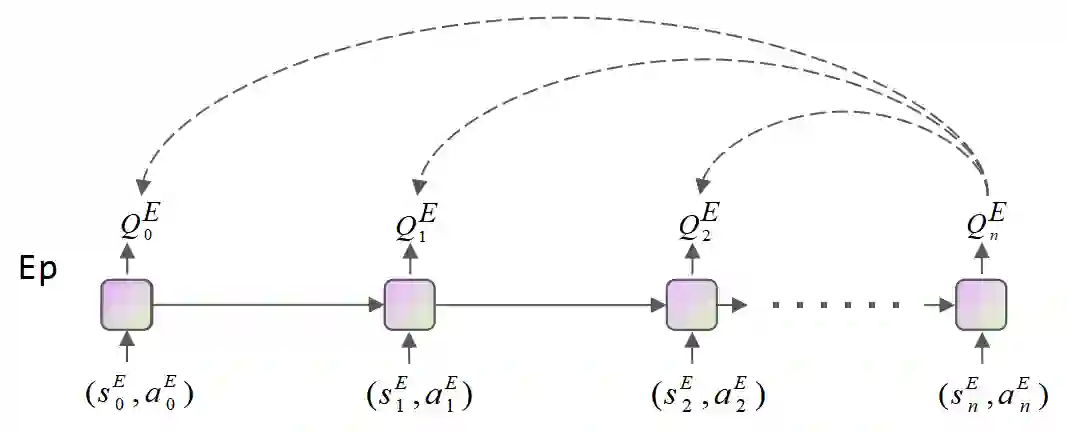
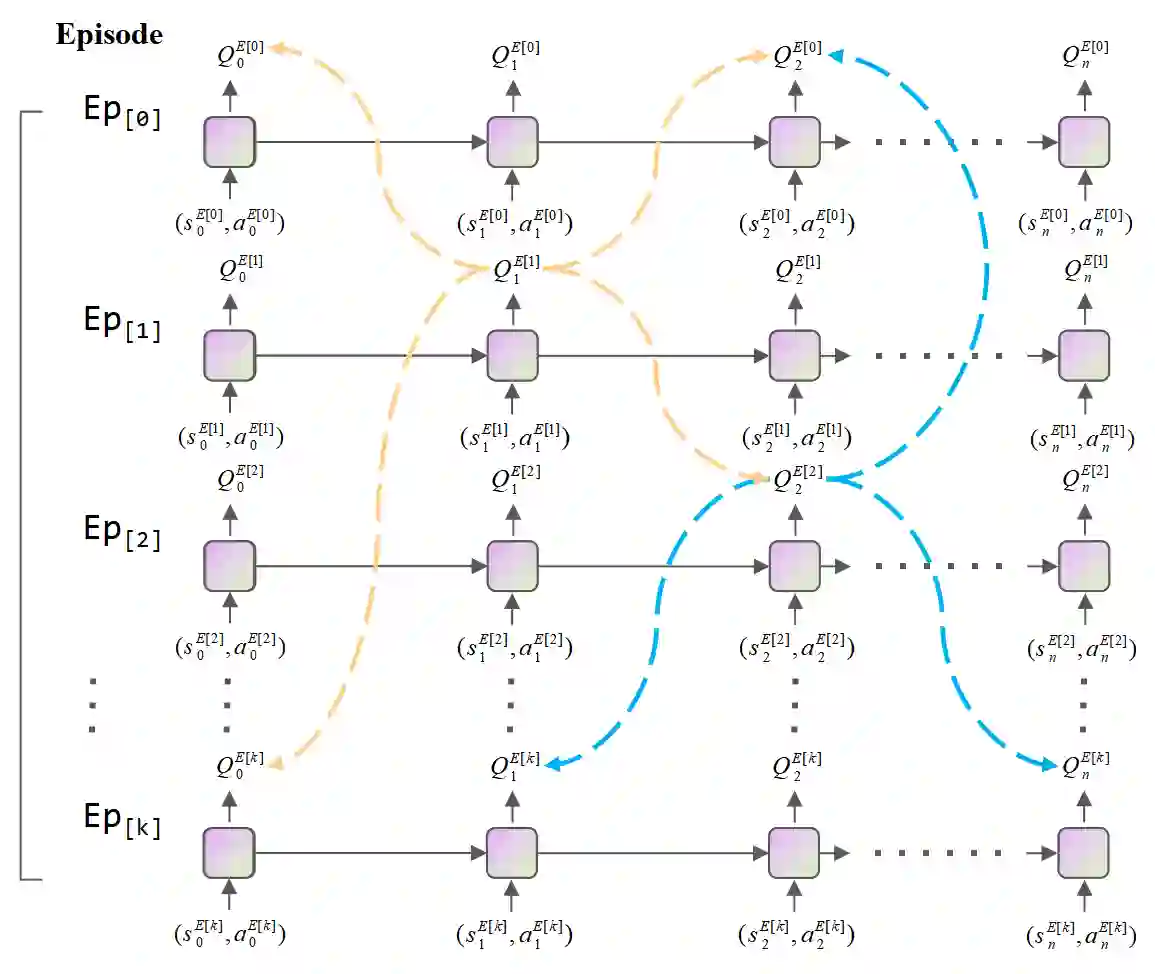
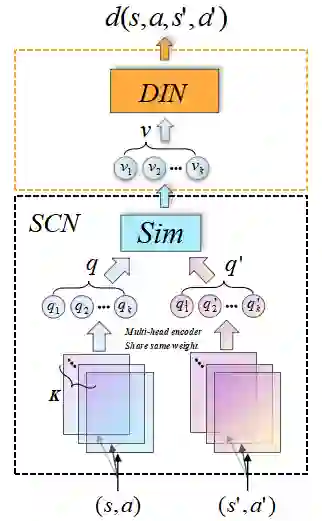
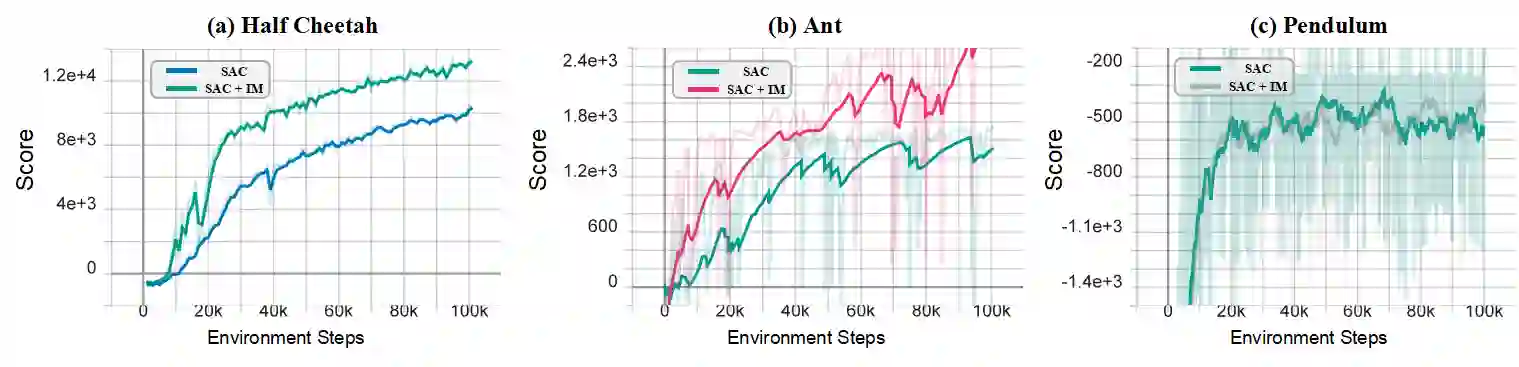
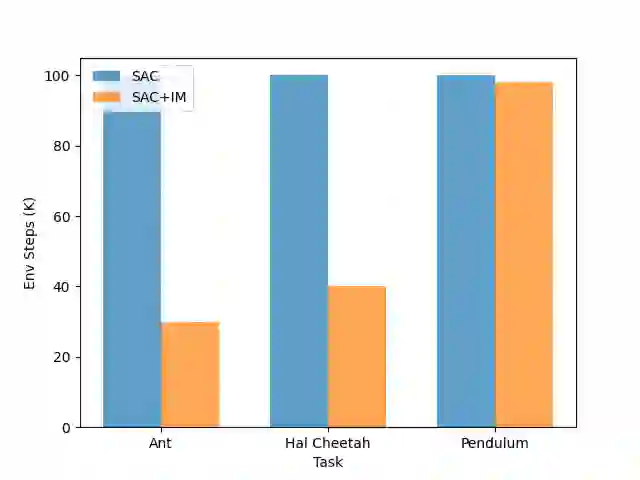
Reinforcement learning (RL) algorithms face the challenge of limited data efficiency, particularly when dealing with high-dimensional state spaces and large-scale problems. Most RL methods often rely solely on state transition information within the same episode when updating the agent's Critic, which can lead to low data efficiency and sub-optimal training time consumption. Inspired by human-like analogical reasoning abilities, we introduce a novel mesh information propagation mechanism, termed the 'Imagination Mechanism (IM)', designed to significantly enhance the data efficiency of RL algorithms. Specifically, IM enables information generated by a single sample to be effectively broadcasted to different states, instead of simply transmitting in the same episode and it allows the model to better understand the interdependencies between states and learn scarce sample information more efficiently. To promote versatility, we extend the imagination mechanism to function as a plug-and-play module that can be seamlessly and fluidly integrated into other widely adopted RL models. Our experiments demonstrate that Imagination mechanism consistently boosts four mainstream SOTA RL-algorithms, such as SAC, PPO, DDPG, and DQN, by a considerable margin, ultimately leading to superior performance than before across various tasks. For access to our code and data, please visit https://github.com/Zero-coder/FECAM.
翻译:强化学习算法面临数据效率有限的挑战,尤其在处理高维状态空间和大规模问题时。大多数强化学习方法在更新智能体Critic时仅依赖同一轨迹内的状态转移信息,这可能导致数据效率低下及训练时间消耗欠佳。受人类类比推理能力启发,我们提出了一种名为"想象机制(IM)"的新型网格信息传播机制,旨在显著提升强化学习算法的数据效率。具体而言,IM能使单个样本产生的信息有效广播至不同状态,而非仅在相同轨迹内传递,从而帮助模型更好地理解状态间的相互依赖关系,更高效地学习稀缺样本信息。为提升通用性,我们将想象机制扩展为即插即用模块,可无缝、流畅地集成到其他主流强化学习模型中。实验表明,想象机制能显著提升四个主流SOTA强化学习算法(如SAC、PPO、DDPG和DQN)的性能,最终在不同任务中实现更优表现。代码与数据请访问https://github.com/Zero-coder/FECAM。