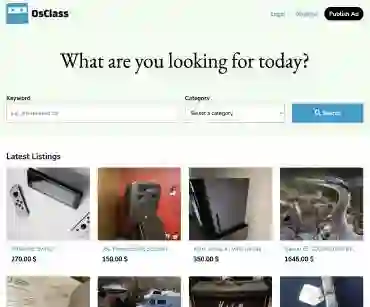
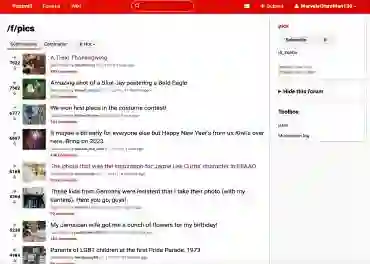
Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic \textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.
翻译:能够规划、推理并在网络上执行操作的自主智能体,为自动化计算机任务提供了有前景的途径。然而,现有的大多数基准测试主要关注基于文本的智能体,忽略了众多需要视觉信息才能有效解决的自然任务。由于大多数计算机界面是为人类感知设计的,视觉信息通常以纯文本模型难以有效利用的方式补充文本数据。为弥合这一差距,我们引入了VisualWebArena——一个旨在评估多模态网络智能体在真实《视觉基础任务》中性能的基准测试。VisualWebArena包含一系列多样且复杂的基于网络的任务,用于评估自主多模态智能体的各种能力。要在该基准测试上取得良好表现,智能体需要准确处理图像-文本输入,理解自然语言指令,并在网站上执行操作以完成用户定义的目标。我们对基于最先进LLM的自主智能体(包括多种多模态模型)进行了广泛评估。通过大量定量与定性分析,我们揭示了纯文本LLM智能体的若干局限性,并展示了当前最先进多模态语言智能体在能力上的差距。VisualWebArena为评估多模态自主语言智能体提供了框架,并为构建更强大的网络自主智能体提供了见解。我们的代码、基线模型及数据已在https://jykoh.com/vwa公开。