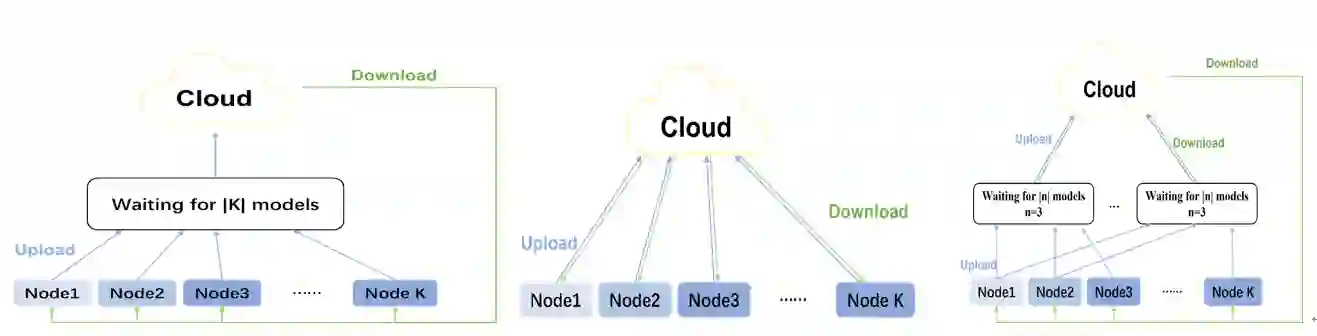
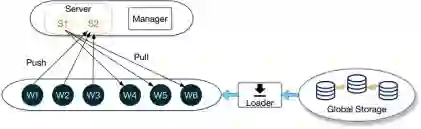
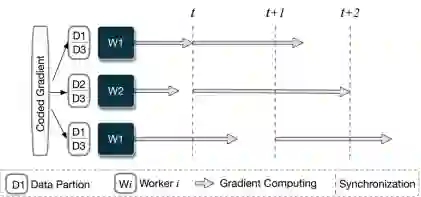
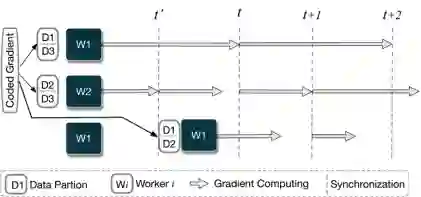
The widespread adoption of distributed learning to train a global model from local data has been hindered by the challenge posed by stragglers. Recent attempts to mitigate this issue through gradient coding have proved difficult due to the large amounts of data redundancy, computational and communicational overhead it brings. Additionally, the complexity of encoding and decoding increases linearly with the number of local workers. In this paper, we present a lightweight coding method for the computing phase and a fair transmission protocol for the communication phase, to mitigate the straggler problem. A two-stage dynamic coding scheme is proposed for the computing phase, where partial gradients are computed by a portion of workers in the first stage and the remainder are decided based on their completion status in the first stage. To ensure fair communication, a perturbed Lyapunov function is designed to balance admission data fairness and maximize throughput. Extensive experimental results demonstrate the superiority of our proposed solution in terms of accuracy and resource utilization in the distributed learning system, even under practical network conditions and benchmark data.
翻译:分布式学习通过利用本地数据训练全局模型的广泛应用,一直受到掉队者问题的阻碍。近期通过梯度编码缓解该问题的尝试,因引入大量数据冗余、计算与通信开销而面临挑战。此外,编码与解码的复杂度随本地工作节点数量线性增长。本文提出一种轻量级计算阶段编码方法及通信阶段公平传输协议,以缓解掉队者问题。针对计算阶段,我们设计了一种两阶段动态编码方案:第一阶段由部分工作节点计算部分梯度,第二阶段根据第一阶段的完成状态动态决定剩余梯度的计算。为保障通信公平性,我们设计了一个带扰动的Lyapunov函数,以平衡准入数据公平性并最大化吞吐量。大量实验结果表明,即使在实际网络条件与基准数据集下,所提方案在分布式学习系统的准确性与资源利用率方面仍具有显著优势。